昨天看到 0.9926 的分數差點開香檳,但冷靜想想,這絕對不是我的模型忽然變成神。今天的任務就是把這個 bug 修好,用正確的方法重新建立 Target Encoding,再比較三種編碼的表現。
昨天的問題是我先用整份資料計算目標均值,再切訓練/驗證集,導致驗證集也偷看了答案,出現典型的 Target Leakage。
今天我改用 OOF Target Encoding:
from sklearn.model_selection import StratifiedKFold, train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
# 分出特徵和目標
y = train["rule_violation"]
X = train.drop(columns=["rule_violation"])
# 已排除目標重新取得欄位名單
cat_cols = X.select_dtypes(include=["object", "category", "bool"]).columns.tolist()
num_cols = X.select_dtypes(include=["number"]).columns.tolist()
# OOF Target Encoding
global_mean = y.mean()
train_te = pd.DataFrame(index=X.index)
test_te = pd.DataFrame(index=test.index)
kf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
for col in cat_cols:
oof = pd.Series(index=X.index, dtype=float)
for tr_idx, val_idx in kf.split(X, y):
means = pd.concat([X.iloc[tr_idx][col], y.iloc[tr_idx]], axis=1) \
.groupby(col)["rule_violation"].mean()
oof.iloc[val_idx] = X.iloc[val_idx][col].map(means)
train_te[col] = oof.fillna(global_mean)
# 測試集:用全訓練集的均值映射
full_means = pd.concat([X[col], y], axis=1).groupby(col)["rule_violation"].mean()
test_te[col] = test[col].map(full_means).fillna(global_mean)
# 合併數值特徵 + TE 類別特徵
X_te = pd.concat([X[num_cols].reset_index(drop=True),
train_te.reset_index(drop=True)], axis=1)
T_te = pd.concat([test[num_cols].reset_index(drop=True),
test_te.reset_index(drop=True)], axis=1)
然後再做一次模型訓練
## === Target Encoding + RandomForest Baseline ===
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 建立 Baseline Model
X_tr, X_val, y_tr, y_val = train_test_split(X_te, y, test_size=0.2, random_state=42, stratify=y)
rf = RandomForestClassifier(n_estimators=300, random_state=42, n_jobs=-1)
rf.fit(X_tr, y_tr)
print("Val Acc:", accuracy_score(y_val, rf.predict(X_val)))

修正後的 OOF Target Encoding 分數從昨天的 0.99 掉回合理範圍(0.65),證明昨天真的是資料前處理沒有做好,導致洩漏答案。
接著我們比較 One-Hot 、 Frequency Encoding 和 Target Encoding 可以發現三者其實分數差不多,Target Encoding 稍微領先一點點,因此我們就已 Target Encoding 的 Baseline model 上傳至 Kaggle 。
# 用最佳表現的特徵
final_model = RandomForestClassifier(n_estimators=300, random_state=42, n_jobs=-1)
final_model.fit(X_te, y)
test_pred = final_model.predict(T_te)
submission = pd.DataFrame({
submission.columns[0]: submission.iloc[:, 0],
submission.columns[1]: test_pred
})
submission.to_csv("submission.csv", index=False)
print("Submission 檔案已產生,可以上傳 Kaggle leaderboard 驗證!")
而這次比賽很特別的一點是,他需要繳交的是在 kaggle 的 Notebook ,所以我們需要把在自己本機端寫好的程式,丟入 kaggle 的 Notebook 還需要注意的是比賽說明提及:Your Notebook cannot use internet access in this competition. Please disable internet in the Notebook editor and save a new version. 代表我們執行程式時,是需要跑出一個沒有網路的版本去做提交(關網路的方法如下圖)
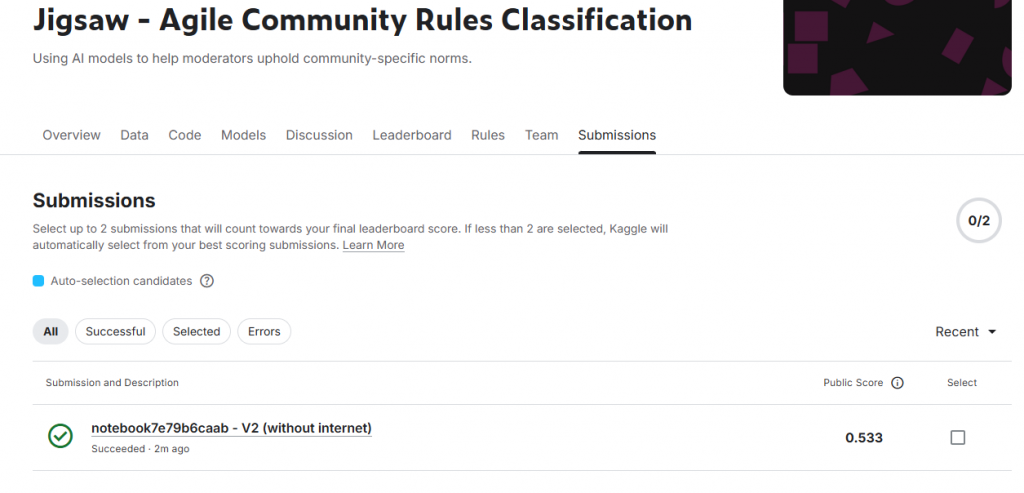
本次實驗以 Target Encoding 搭配簡單的 RandomForestClassifier 建立 Baseline Model 進行測試,最終分數約 0.533,雖然結果有限,但成功驗證了前處理流程與特徵轉換是正確的。接下來我會繼續嘗試更進階的模型與加入更多評估指標,希望可以進一步提升模型效能提升我在 kaggle leaderboard 的分數。


 iThome鐵人賽
iThome鐵人賽