延續 DAY24 的內容,我們已經學會了 ORB 特徵點偵測與描述,並利用暴力匹配(Brute Force Matcher, BFMatcher)進行特徵點配對。
本章將進一步說明 ORB 與暴力匹配的差異與關係,並介紹 FLANN 匹配與 RANSAC 優化,讓你能更精確地評估與提升匹配結果。
關係說明:
ORB 提供可比對的資料(描述子),暴力匹配則負責將這些描述子進行配對。兩者是分工合作的關係,常一起使用於特徵匹配流程。
依舊使用 box.jpg 與 box_in_scene.jpg 進行測試。
import cv2
import numpy as np
# 讀取圖片
img1 = cv2.imread("box.jpg")
img2 = cv2.imread("box_in_scene.jpg")
img1_gray = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
img2_gray = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
cv2.imshow("Original img1", img1_gray)
cv2.imshow("Original img2", img2_gray)
# 將以下程式碼放在所有顯示語句的最後面
cv2.waitKey()
cv2.destroyAllWindows()
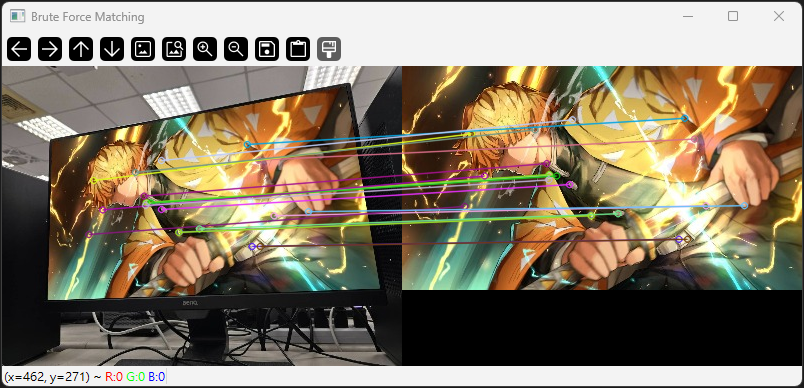
暴力匹配會對每個特徵點進行逐一比對,計算所有特徵點之間的距離,然後選擇距離最近的點作為匹配結果。
# 建立 ORB 物件
orb = cv2.ORB_create()
# 偵測關鍵點與描述子
kp1, des1 = orb.detectAndCompute(img1_gray, None)
kp2, des2 = orb.detectAndCompute(img2_gray, None)
# 建立暴力匹配器(使用漢明距離)
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
# 匹配特徵
matches = bf.match(des1, des2)
# 依照距離排序
matches = sorted(matches, key=lambda x: x.distance)
# 繪製匹配結果
img_matches = cv2.drawMatches(img1, kp1, img2, kp2, matches[:20], None, flags=2)
cv2.imshow("Brute Force Matching", img_matches)
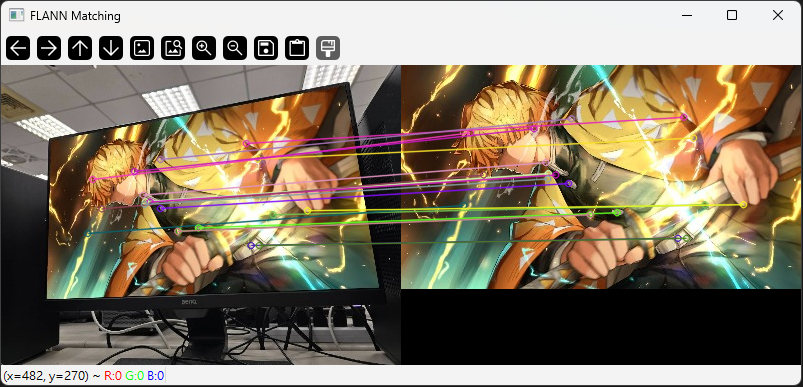
補充說明:
暴力匹配適合特徵點數量較少的情境,實作簡單但計算量大,速度較慢。
FLANN 是一種高效的特徵匹配方法,特別適合大規模資料集,能夠在近似最近鄰的基礎上快速進行特徵匹配。
與暴力匹配相比,FLANN 在特徵點數量多時能大幅提升速度。
# FLANN 參數(適用於 ORB 二進制描述子)
index_params = dict(algorithm=6, table_number=6, key_size=12, multi_probe_level=1)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
# 執行匹配
matches_flann = flann.match(des1, des2)
matches_flann = sorted(matches_flann, key=lambda x: x.distance)
# 繪製匹配結果
img_matches_flann = cv2.drawMatches(img1, kp1, img2, kp2, matches_flann[:20], None, flags=2)
cv2.imshow("FLANN Matching", img_matches_flann)
補充說明:
FLANN 適合大量特徵點的匹配,速度快且資源消耗低。參數可根據描述子型態調整。
評估特徵匹配結果是否準確非常重要,常見的評估指標如下:
匹配精度通常以比對點的錯誤率來衡量。若匹配的特徵點在圖像中對應位置越接近,則精度越高。
RANSAC(Random Sample Consensus)是一種常用算法,用來過濾錯誤匹配點並進行擬合。
通常用於單應性矩陣(Homography)估算,能有效去除誤匹配。
# 計算匹配點對應的變換矩陣
pts1 = np.float32([kp1[m.queryIdx].pt for m in matches_flann]).reshape(-1, 1, 2)
pts2 = np.float32([kp2[m.trainIdx].pt for m in matches_flann]).reshape(-1, 1, 2)
# 使用 RANSAC 計算單應性矩陣
M, mask = cv2.findHomography(pts1, pts2, cv2.RANSAC, 5.0)
# 根據 RANSAC 結果過濾匹配點
matchesMask = mask.ravel().tolist()
# 繪製結果
img_matches_ransac = cv2.drawMatches(img1, kp1, img2, kp2, matches_flann, None, matchColor=(0, 255, 0), singlePointColor=(255, 0, 0), matchesMask=matchesMask, flags=2)
cv2.imshow("RANSAC Matching", img_matches_ransac)
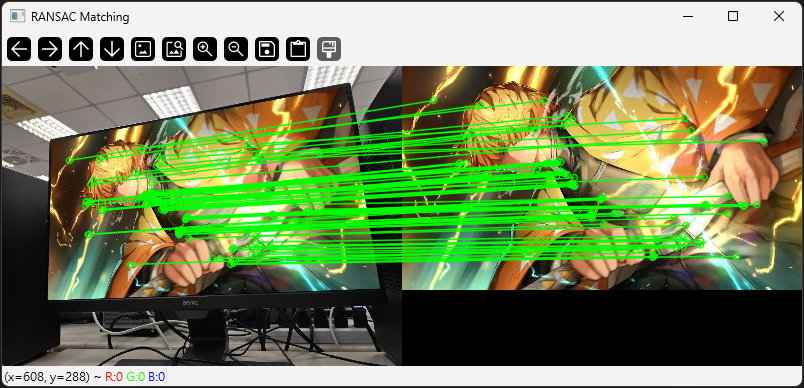
補充說明:
cv2.findHomography() 可利用 RANSAC 過濾錯誤匹配,提升比對結果的準確性。
matchesMask 用來標示正確匹配點,繪製過濾後的匹配結果。
| 方法 | 適用場景 | 優點 | 缺點 |
|---|---|---|---|
| 暴力匹配 | 小型資料集 | 實作簡單、結果精確 | 計算量大、速度慢 |
| FLANN | 大型資料集 | 速度快、適合大量特徵 | 需調整參數、近似匹配 |
| RANSAC | 匹配結果優化 | 能去除誤匹配、提升精度 | 需額外計算、參數敏感 |
補充說明:


 iThome鐵人賽
iThome鐵人賽