影像金字塔是一種將影像逐步縮小並形成多層次結構的技術,廣泛應用於影像處理、物體偵測、影像分析等領域。
透過金字塔結構,可以有效處理多尺度問題,使物體在不同大小與解析度下都能被識別。
本章將介紹影像金字塔的基本概念、OpenCV 的實作方式,以及多尺度處理的應用與方法比較。
影像金字塔是一系列經過不同層次縮放處理的影像,從原始影像開始,逐步縮小,形成金字塔形狀。
每一層代表不同的解析度,讓我們可以在不同尺度下分析影像。
準備一張圖片 image.jpg,並放在程式同一資料夾。
import cv2
import numpy as np
# 讀取影像
img = cv2.imread("image.jpg")
cv2.imshow("Original", img)
# 將以下程式碼放在所有顯示語句的最後面
cv2.waitKey()
cv2.destroyAllWindows()
說明:
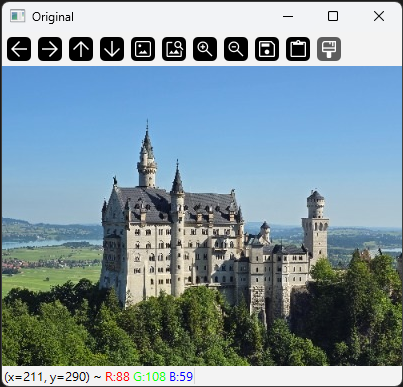
在金字塔處理之前,先顯示原始影像。
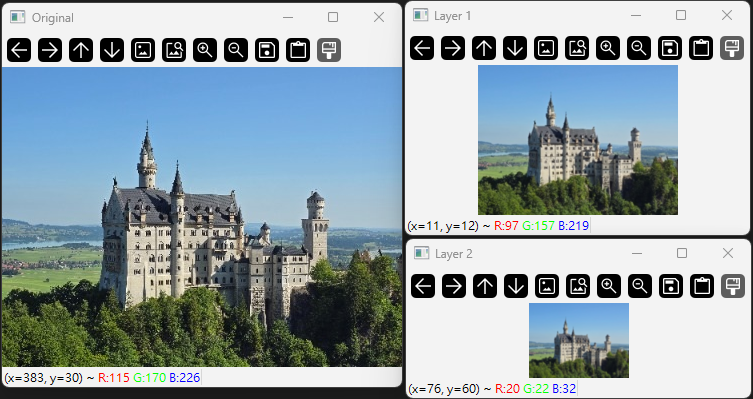
使用 cv2.pyrDown() 生成高斯金字塔,每次調用會將影像縮小一半並進行高斯模糊。
# 建立高斯金字塔
layer1 = cv2.pyrDown(img) # 生成第一層
layer2 = cv2.pyrDown(layer1) # 生成第二層
# 顯示結果
cv2.imshow("Layer 1", layer1)
cv2.imshow("Layer 2", layer2)
說明:
pyrDown() 每次會將影像大小縮小一半,並應用高斯濾波。可反覆應用來生成多層金字塔。
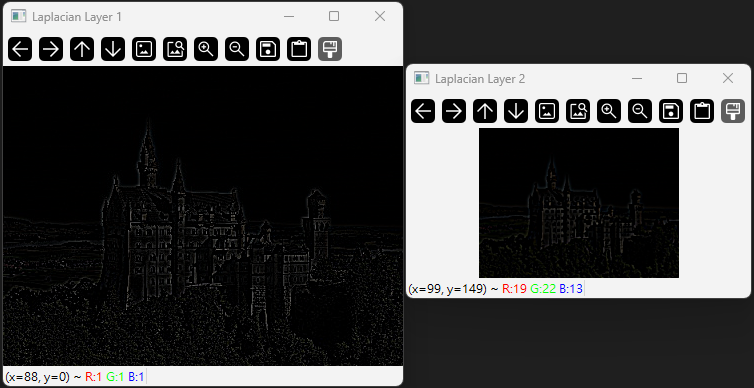
拉普拉斯金字塔是高斯金字塔相鄰兩層的差異,能強調影像的邊緣細節。
可用 cv2.pyrUp() 將低層影像放大,再用 cv2.subtract() 計算差異。
# 建立拉普拉斯金字塔
lap1 = cv2.subtract(img, cv2.pyrUp(layer1)) # 第一層與上一層的差異
lap2 = cv2.subtract(layer1, cv2.pyrUp(layer2)) # 第二層與上一層的差異
# 顯示結果
cv2.imshow("Laplacian Layer 1", lap1)
cv2.imshow("Laplacian Layer 2", lap2)
說明:
cv2.subtract() 用於計算兩層之間的差異,強調影像中的邊緣與細節。
多尺度處理是在不同解析度下分析影像的方法,能有效處理大小物體的識別與分析。
透過金字塔結構,可以在每層不同的解析度下尋找物體,提升物體偵測與識別的效果。
應用場景:
| 類型 | 主要用途 | 優點 | 缺點 |
|---|---|---|---|
| 高斯金字塔 | 降噪、縮小影像 | 多層次分析、降噪效果佳 | 細節可能流失 |
| 拉普拉斯金字塔 | 邊緣強化、重建 | 強調細節、可逆重建 | 對雜訊較敏感 |
補充說明:


 iThome鐵人賽
iThome鐵人賽