首先是必要的 import
import os
import json
from dotenv import find_dotenv, load_dotenv
_ = load_dotenv(find_dotenv())
TAVILY_API_KEY = os.getenv("TAVILY_API_KEY")
from llama_index.core.workflow import (
step,
Context,
Workflow,
Event,
StartEvent,
StopEvent,
)
from llama_index.core import PromptTemplate
from llama_index.llms.openai import OpenAI
from llama_index.core.agent.workflow import ReActAgent
from llama_index.tools.tavily_research.base import TavilyToolSpec
from llama_index.core.tools import FunctionTool
from llama_index.utils.workflow import draw_all_possible_flows
input
qset = {
"id": "113-1-1-med-surg",
"year": "113",
"time": "1",
"qid": "1",
"discipline": "內外科護理學",
"ans": "C",
"question": "有關多發性硬化症之診斷檢查,下列何者錯誤?",
"options": {
"A": "腦脊髓液分析可發現IgG抗體上升",
"B": "視覺誘發電位可觀察到受損的神經在傳導過程出現延遲和中斷",
"C": "超音波檢查可發現中樞神經系統髓鞘脫失",
"D": "核磁共振影像可用來確認多發性硬化症之斑塊"
},
"discipline_slug": "med-surg"
}
exam_question = f"題幹: {qset['question']}\n選項: \nA: {qset['options']['A']}; B: {qset['options']['B']}; C: {qset['options']['C']}; D: {qset['options']['D']}."
print(exam_question)

Prompt
包含: SUB_QUESTION_PROMPT, AGENT_PROMPT, COMBINE_ANSWER_PROMPT
SUB_QUESTION_PROMPT = PromptTemplate("""你是一個考題拆解助手。請根據以下單選題,產生一系列子問題。規則如下:
1. 子問題需為單一問句,避免複合句。
2. 每個子問題必須包含完整上下文,不可依賴原始題目才能理解。
3. 子問題的集合在合併答案後,應能完整回答此單選題。
4. 回應必須是**純 JSON 格式**,不得包含任何額外文字或 Markdown。
### 範例輸出:
{{
"sub_questions": [
"舊金山的人口是多少?",
"舊金山的年度預算是多少?",
"舊金山的 GDP 是多少?"
]
}}
以下是單選題:
{exam_question}
"""
)
print(SUB_QUESTION_PROMPT.format(exam_question=exam_question))
好讀版
主要就是把 Day11: SubQuestionQueryEngine(上): SubQuestion 與 Workflow 發現的幾個問題講給 chatgpt 聽, 然後請他改一版出來
AGENT_PROMPT
agent.get_prompts() 取COMBINE_ANSWER_PROMPT
COMBINE_ANSWER_PROMPT = PromptTemplate("""你是一個考題作答助手。以下是一題單選題,已經被拆解成數個子問題,並且每個子問題都已有答案。
請將所有子問題的答案整合,產生一個完整且連貫的最終解答,以回答原始單選題。
以下是單選題:
{exam_question}
子問題與答案:
{sub_qa}
""")
class QueryEvent(Event):
question: str
class AnswerEvent(Event):
question: str
answer: str
from llama_index.core.agent.workflow import AgentInput, AgentOutput, ToolCall, ToolCallResult
async def run_agent_with_stream(agent, query):
handler = agent.run(query)
results = []
async for ev in handler.stream_events(expose_internal=False):
name = ev.__class__.__name__
print(f"-----stream event: {name}")
results.append((name, ev))
if isinstance(ev, AgentInput):
print(f"len of chat message: {len(ev.input)}")
elif isinstance(ev, AgentOutput):
print(ev.response.blocks[0].text)
elif isinstance(ev, ToolCall):
print(f"{ev.tool_name}: {ev.tool_kwargs}")
elif isinstance(ev, ToolCallResult):
num_rv = len(ev.tool_output.blocks)
print(f"num_result: {num_rv}")
# 最終 response
response = await handler
return results, response
subqa
.update_prompts 把原本的 system prompt 改掉
class SubQuestionQueryEngine(Workflow):
@step
async def query(self, ctx: Context, ev: StartEvent) -> QueryEvent:
# initial
llm = OpenAI(model="gpt-5-mini", temperature=0, json_mode=True)
# subquestions gen
print('sub question gen...')
response = llm.complete(SUB_QUESTION_PROMPT.format(exam_question=ev.question))
print('sub question gen complete')
sub_questions = json.loads(response.text)['sub_questions']
# get num_question
num_question = len(sub_questions)
await ctx.store.set("num_question", len(sub_questions))
await ctx.store.set("exam_question", exam_question)
for idx, q in enumerate(sub_questions):
print(f"send Q{idx+1}: {q}")
ctx.send_event(QueryEvent(question=q))
return None
@step
async def sub_question(self, ctx: Context, ev: QueryEvent) -> AnswerEvent:
# initial
tavily_tool = TavilyToolSpec(
api_key=TAVILY_API_KEY,
)
tavily_tool_list = tavily_tool.to_tool_list()
llm = OpenAI(model="gpt-5-mini", temperature=0, is_streaming=False) # streaming False for non-verified organisations
agent = ReActAgent(tools=tavily_tool_list, llm=llm, streaming=False, verbose=False)
agent.update_prompts({"react_header": AGENT_PROMPT})
# call
results, response = await run_agent_with_stream(agent, ev.question)
answer = response.response.blocks[0].text
return AnswerEvent(question=ev.question, answer=answer)
@step
async def combine_answers(
self, ctx: Context, ev: AnswerEvent
) -> StopEvent | None:
num_question = await ctx.store.get("num_question")
exam_question = await ctx.store.get("exam_question")
# wait until we receive all events
result = ctx.collect_events(ev, [AnswerEvent] * num_question)
if result is None:
print('combine_answers waite None')
return None
# combine sub_question and sub_answer
sub_qa = "\n\n".join([
f"Question: {qa.question}: \n Answer: {qa.answer}"
for qa in result
])
llm = OpenAI(model="gpt-5-mini", temperature=0, is_streaming=False)
response = llm.complete(COMBINE_ANSWER_PROMPT.format(sub_qa=sub_qa, exam_question=exam_question))
return StopEvent(result=response.text)
draw_all_possible_flows(
SubQuestionQueryEngine, filename="day13_sub_question_query_engine.html"
)
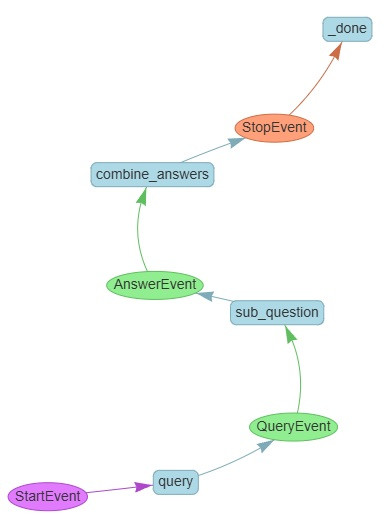
w = SubQuestionQueryEngine(timeout=600, verbose=False)
handler = w.run(start_event=StartEvent(question=exam_question))
response = await handler
首先是整體題目的 response,可以看到答案是正確的
接著是更新 prompt 後的 subquestion,可以與前天對照,在 不需要上下文就能看懂,以及 不要一個子問題裡又問了好幾個問題 的方面確實有改善
修改前:


我們今天補上了最後 combine_answers 的部分
並且嘗試修改了 子問題 生成部分,以及 ReActAgent 部分的 prompt
最後搭建出了完整的 SubQuestionQueryEngine as Workflow
熬了三天我們終於結束 SubQuestionQueryEngine 的部分,明天要來把 CitationQueryEngine 也整進來,造出我們主題 1-2 的 Dataset

