我們通過上篇 DAY15 淬鍊之章-Glue 概念篇 了解到了 Glue 的概念與核心功能。
本篇我們要來實際使用 Glue 建立 Silver PySpark Job,來針對數據做一個簡單的清理。
在使用 Glue 之前,我們一樣需要先建立一個 Glue 專用的 Role,並賦予 Role 所需的 Policy。
Step1:登入 Joe 使用者,進入 IAM 建立 Role 頁面
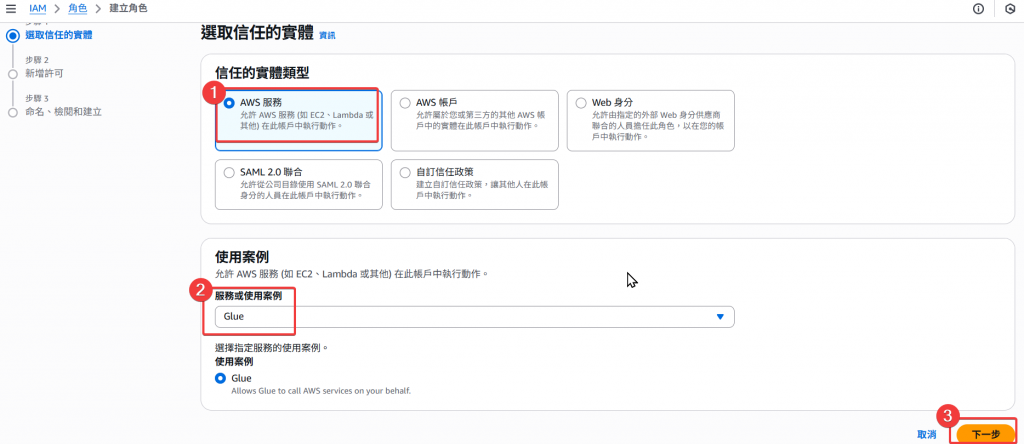
Step2:選擇 AWSGlueConsoleFullAccess 與 AmazonS3FullAccess 的 Policy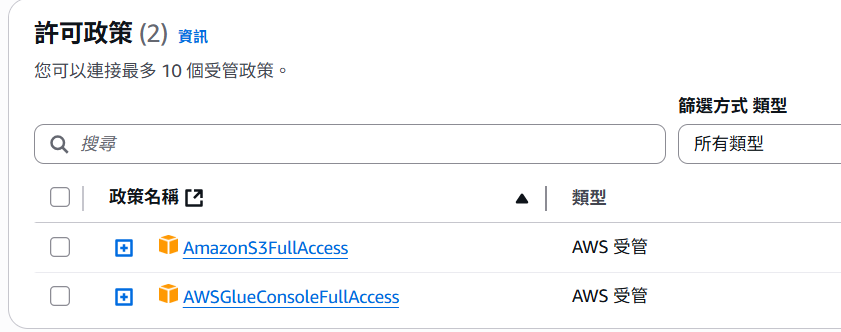
Step3:Role Name 命名為Full_Glue_Role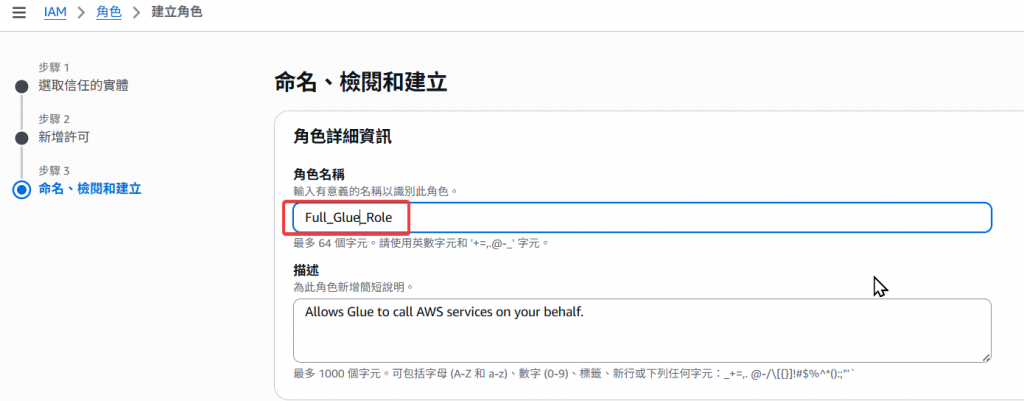
Step4:確認 Policy 後,按「建立角色」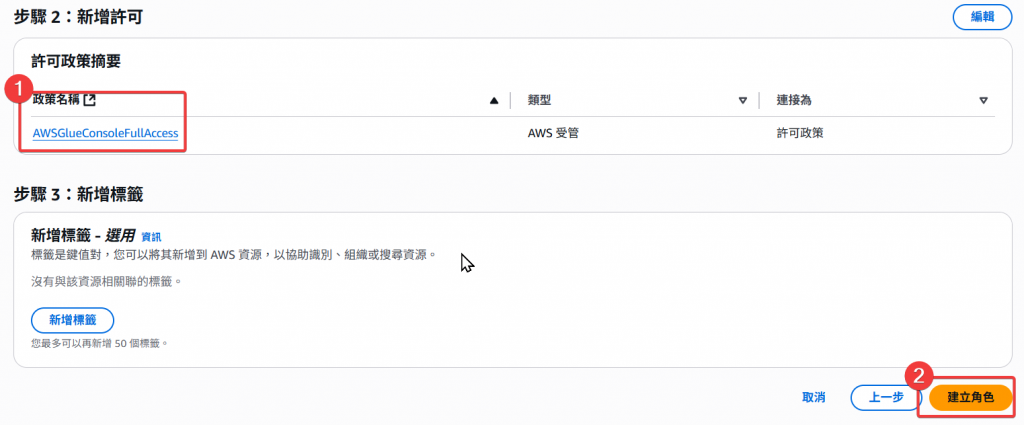
Step5:回到 Role 頁面,看到 Full_Glue_Role 即完成建立 Glue Role
Step1:進入 DE Group 的頁面,點選「建立內嵌政策」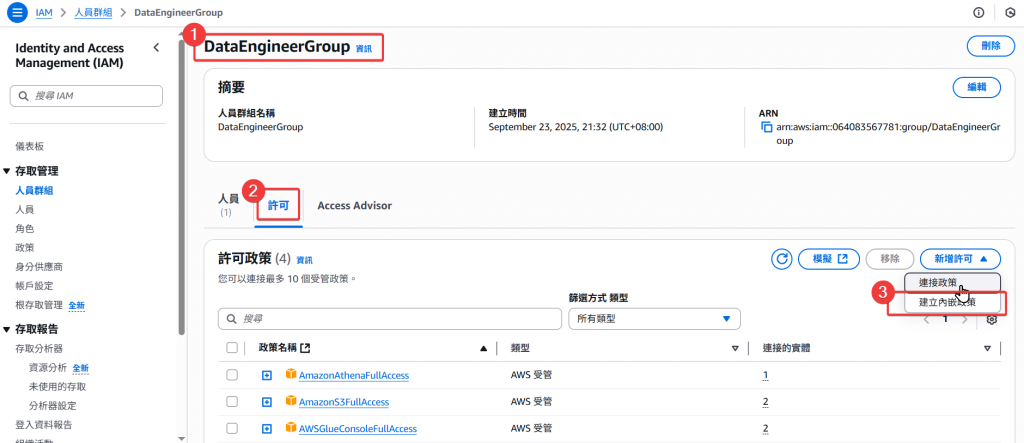
Step2:點選 Json 並將 Json Policy 語法貼上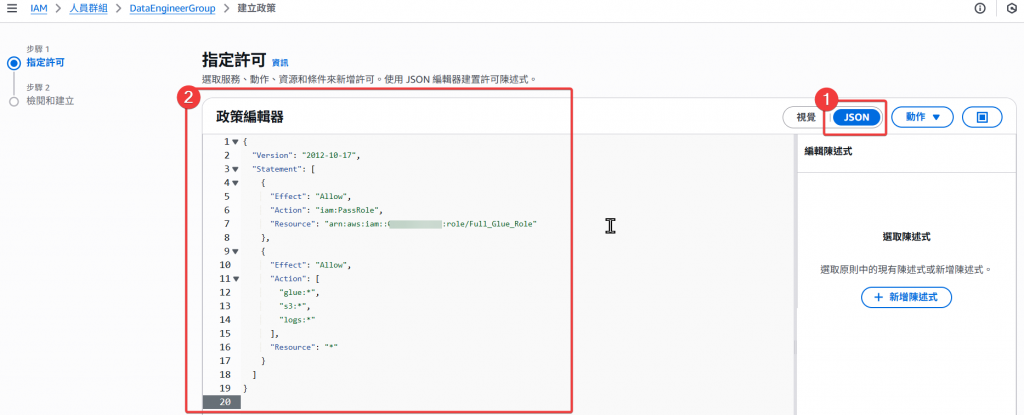
下方 Resource 請填寫自己的 accoint_id
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::account_id:role/Full_Glue_Role"
},
{
"Effect": "Allow",
"Action": [
"glue:*",
"s3:*",
"logs:*"
],
"Resource": "*"
}
]
}
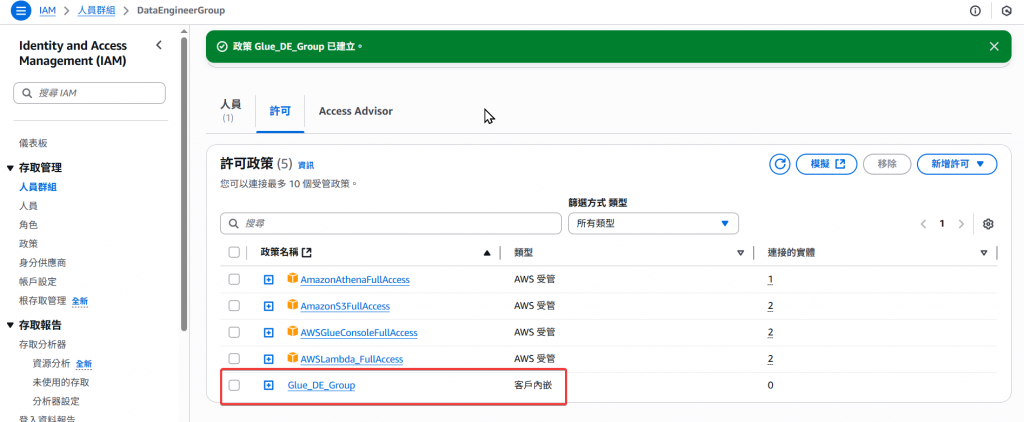
Step3:接著針對此 Policy 命名 Glue_DE_Group 可自行命名,完成後按建立即可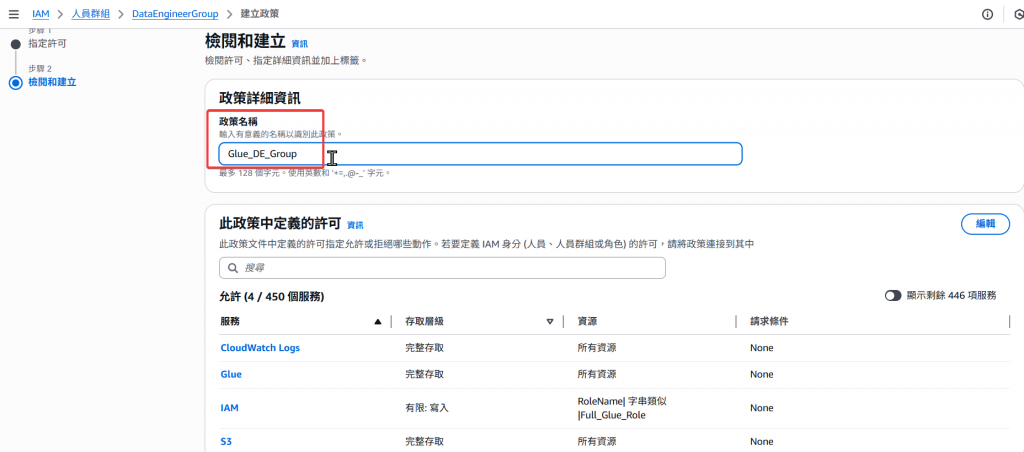
Step4:最後回到 DE Group 的頁面確認是否有一個新的內嵌政策Glue_DE_Group,即完成建立,這樣以後 Group 內的 User 都可以使用此政策了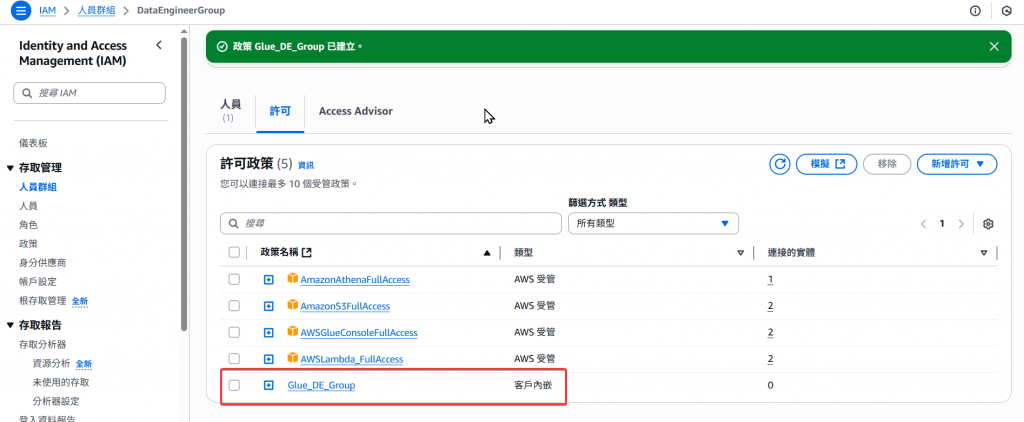
Step1:首先登入 DE 的 Andy 使用者,接著選擇台北區域,一樣於左上角搜尋 Glue,並點選 Glue 進入頁面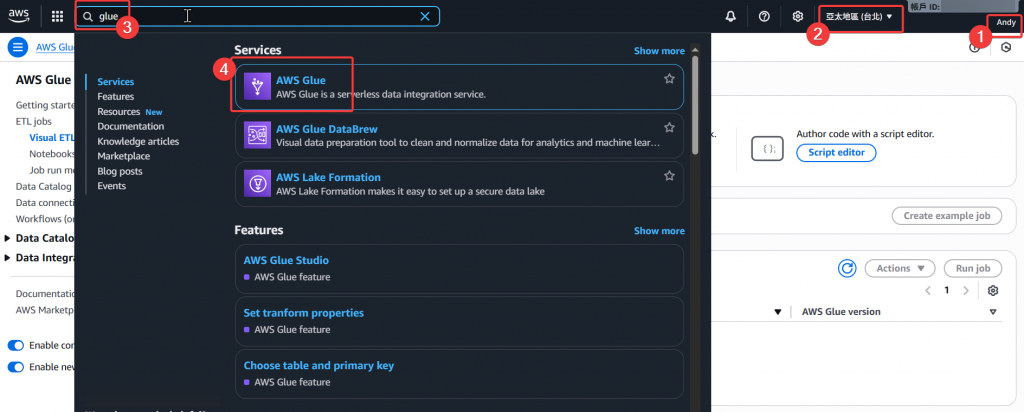
Step2:接著於 Glue 的頁面點選左邊 Menu 的「 Visual ETL 」,進入編寫 ETL Job 的頁面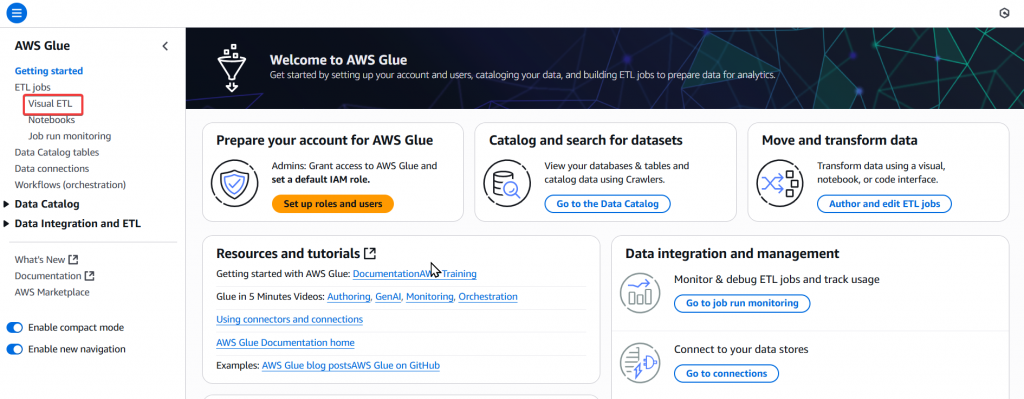
Step3:接著我們要撰寫 Spark 所以點選右上角的 「Script editor」按鈕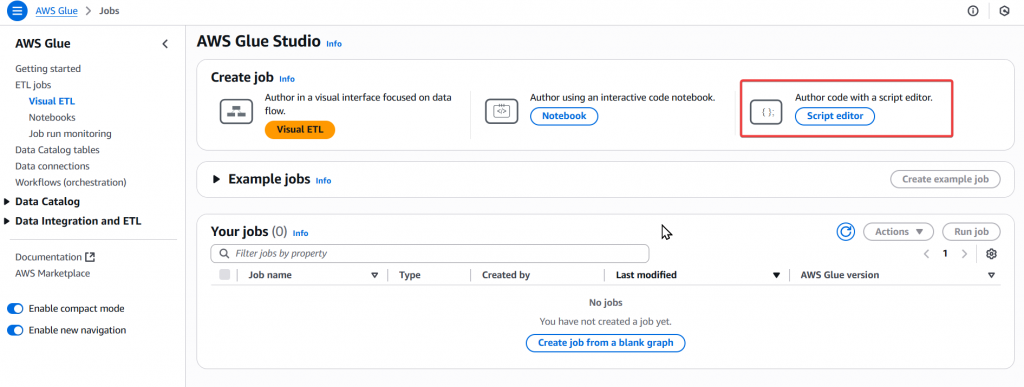
Step4:然後選擇「Spark」並選擇 Start fresh,然後點選「Create Script」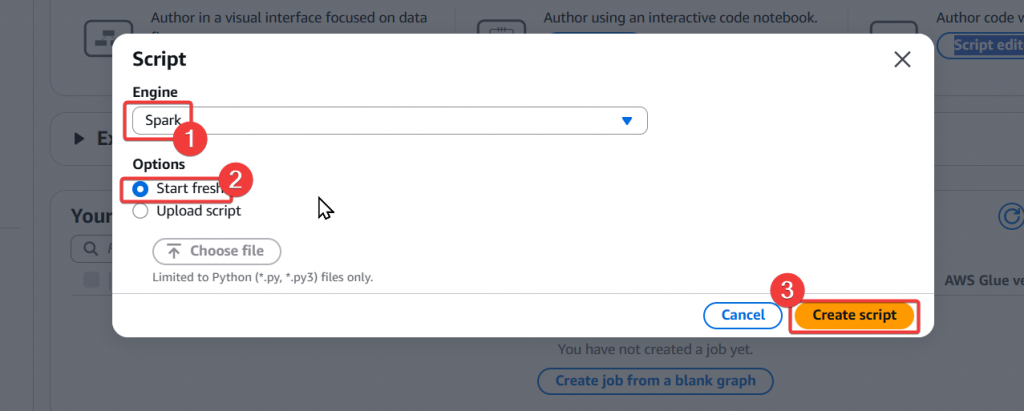
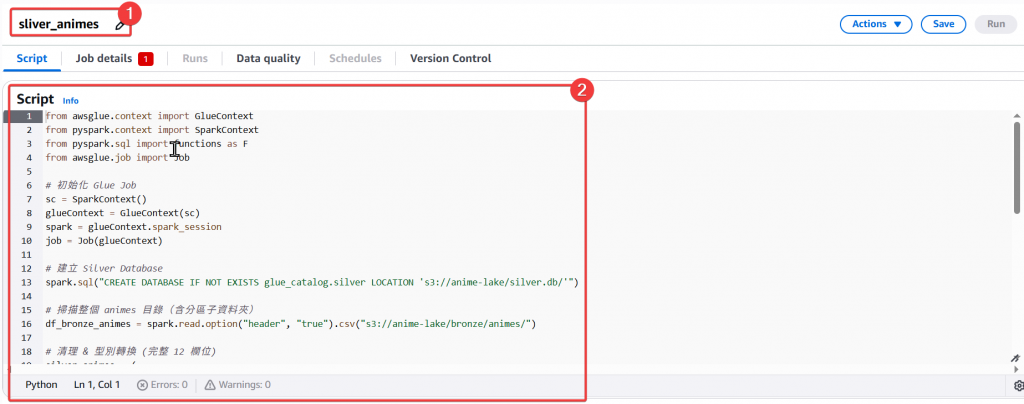
Step5:接著我們要來編寫 Spark Script
sliver_animes
from awsglue.context import GlueContext
from pyspark.context import SparkContext
from pyspark.sql import functions as F
from awsglue.job import Job
# 初始化 Glue Job
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
spark.conf.set("spark.sql.catalog.glue_catalog", "org.apache.iceberg.spark.SparkCatalog")
spark.conf.set("spark.sql.catalog.glue_catalog.warehouse", "s3://anime-lake/")
spark.conf.set("spark.sql.catalog.glue_catalog.catalog-impl", "org.apache.iceberg.aws.glue.GlueCatalog")
spark.conf.set("spark.sql.catalog.glue_catalog.io-impl", "org.apache.iceberg.aws.s3.S3FileIO")
# 建立 Silver Database
spark.sql("CREATE DATABASE IF NOT EXISTS silver LOCATION 's3://anime-lake/silver.db/'")
# 讀取 Bronze (原始 CSV) - 確保 s3://anime-lake/bronze/animes/ 底下有檔案
df_bronze_animes = spark.read.option("header", "true").csv(
"s3://anime-lake/Bronze/animes/*/"
)
# 清理 & 型別轉換 (完整 12 欄位)
silver_animes = (
df_bronze_animes.dropDuplicates(["animeID"])
.filter(df_bronze_animes["score"].isNotNull())
.withColumn("animeID", F.col("animeID").cast("int"))
.withColumn("year",F.when(F.col("year").rlike("^[0-9]{4}$"), F.col("year").cast("int")).otherwise(None))
.withColumn("score", F.col("score").cast("double"))
.withColumn("episodes", F.col("episodes").cast("int"))
.withColumn("title", F.trim(F.col("title")))
.withColumn("alternative_title", F.trim(F.col("alternative_title")))
.withColumn("type", F.trim(F.col("type")))
.withColumn("mal_url", F.trim(F.col("mal_url")))
.withColumn("sequel", F.trim(F.col("sequel")))
.withColumn("image_url", F.trim(F.col("image_url")))
.withColumn("genres", F.trim(F.col("genres")))
.withColumn("genres_detailed", F.trim(F.col("genres_detailed")))
)
# 寫入 Silver (Iceberg Table)
silver_animes.write \
.format("iceberg") \
.mode("overwrite") \
.saveAsTable("glue_catalog.silver.animes")
job.commit()
Step6:接著我們點選頁籤上的「 Job Details 」來查看此 Script 的設定
Full_Glue_Role
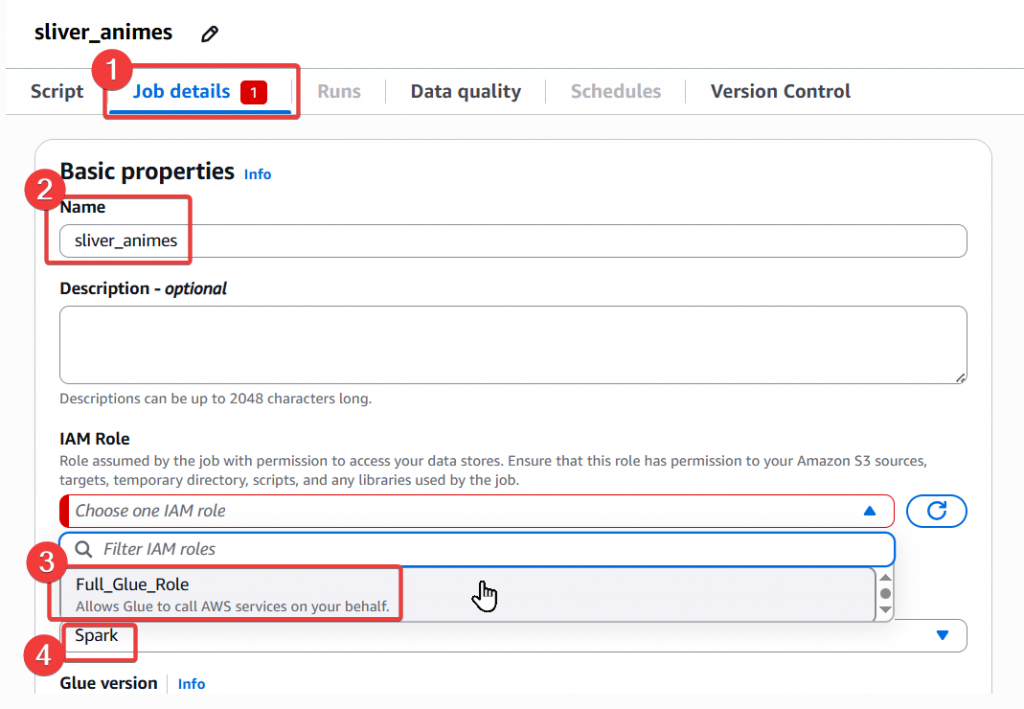
Step7:接續設定
Glue Version:Glue 4.0
Language:Python 3
Worker type:G 1X
Requested number of workers:2
最後點選右上角的「Save」按鈕完成 Glue Job 設定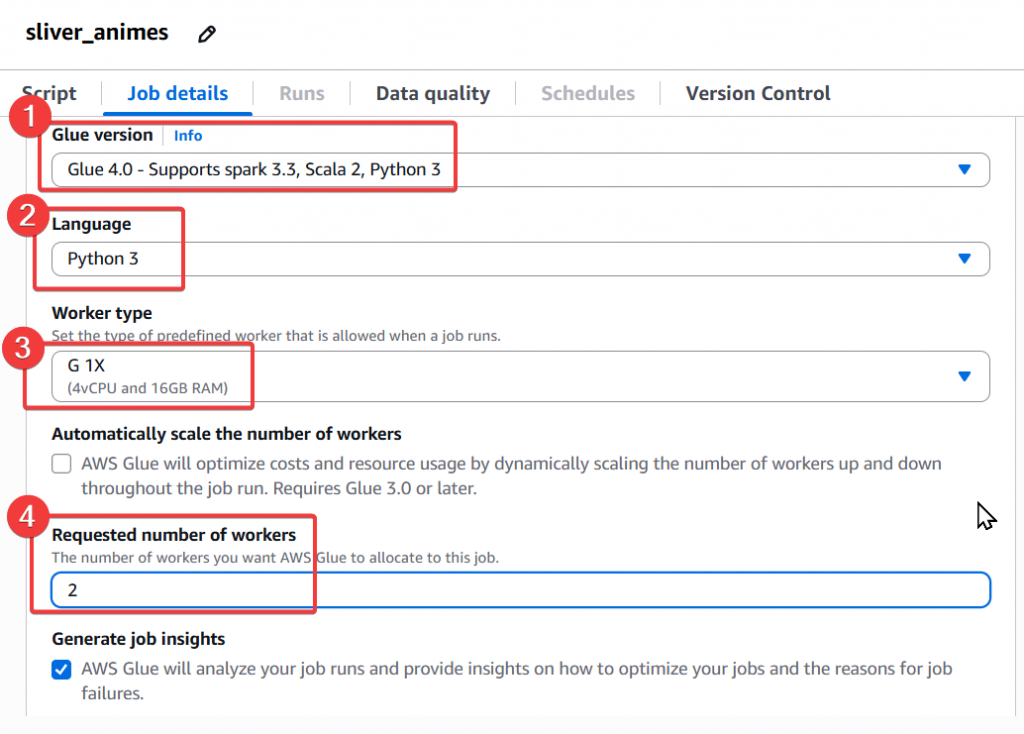
點選下方 Advanced properties
於 Job parameters 位置建立一個 Key=--datalake-formats value = iceberg 的參數,才能正常使用 iceberg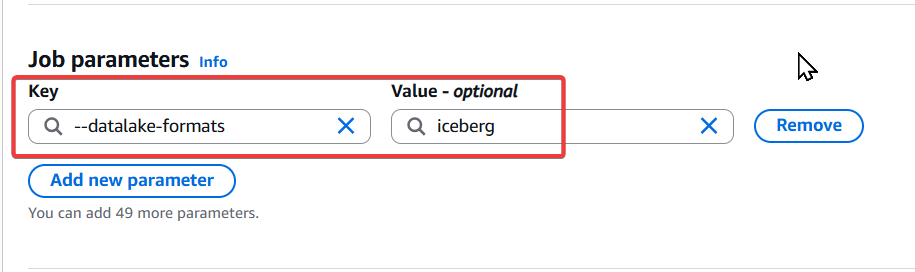
Step8:建立好 Glue Job 後,我們接續來做執行
Step9:執行後我們可以看到一筆 Job 正在運行中,然後下方 Detail 會出現該 Job 的運作細節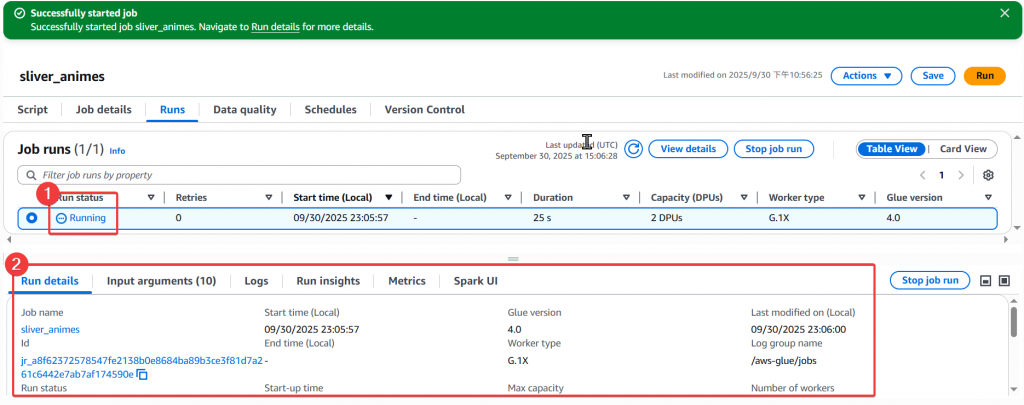
Step10:待 Job 完成後,即可於 Catalog 的 Database 確認有實際建立 silver db 和 table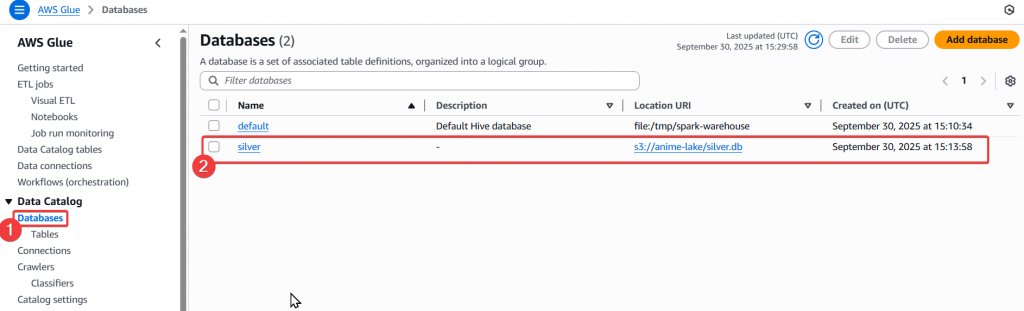
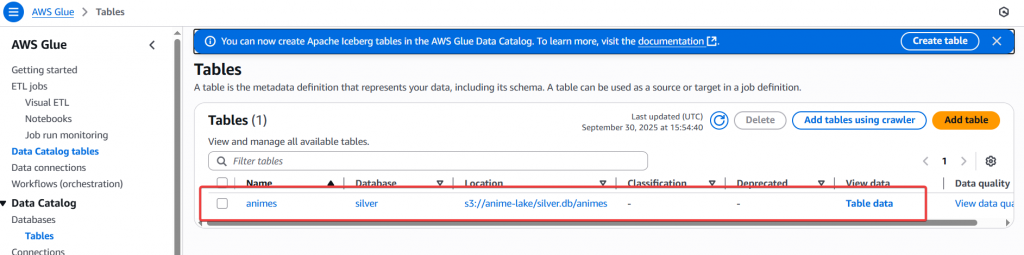
接著請大家自行完成
sliver_animes的 Glue Job 建立,並於後續確認是否有正常建立 DB 和 Table
在本篇中,我們實際撰寫了 AWS Glue Job (PySpark),並將 原始 CSV(Bronze 層存放於 S3)轉換為 Iceberg Table(Silver 層)。這個過程中有幾個關鍵重點:
Bronze 層
Silver 層
trim() 去掉多餘空白)建議做法
在下一篇 「Day17 淬鍊之章-Glue 實作篇-2」 中,我們將:


 iThome鐵人賽
iThome鐵人賽