在上篇 Day16 淬鍊之章-Glue 實作篇-1 中,我們實作了 Glue 所需的 IAM Role 建立和指派,以及實際建立一支 Glue PySpark Job。
本篇我們要來建立另一支 Glue PySpark Job 來處理 Silver animes 與 ratings 的 Table Join,並使用 Glue Workflow 將 silver Job 與 gold job 串接成一個 Pipeline。
首先,我們先來確認當我們在 Glue + Iceberg 中建立表格時,S3 會產生的兩個主要目錄,例如:
s3://anime-lake/gold.db/animes_summary/
├── data/ # 實際資料檔案 (Parquet, ORC, Avro)
└── metadata/ # Iceberg 表的元資料 (JSON, Avro)
data/ 目錄data/year=2021/genres=Action/part-0000-xxxx.parquet
data/year=2021/genres=Comedy/part-0001-yyyy.parquet
data/year=0/genres=Unknown/part-0002-zzzz.parquet
metadata/ 目錄v0001.metadata.jsonsnapshots.avromanifest.avro / manifest-list.avrometadata/,再決定要掃哪些 data/ 檔案。這也是為什麼有時候 Glue Job 寫入失敗會看到 metadata 殘留 → commit abort,因為 Iceberg 在設計上強調 一致性 (Consistency),metadata 一旦不完整,就會中止寫入。
了解完 Iceberg 的分區儲存設計後,我們來實際建立 Glue Job
Step1:
gold_anime_summary
anime_count、avg_anime_score、total_ratings、avg_user_rating 等指標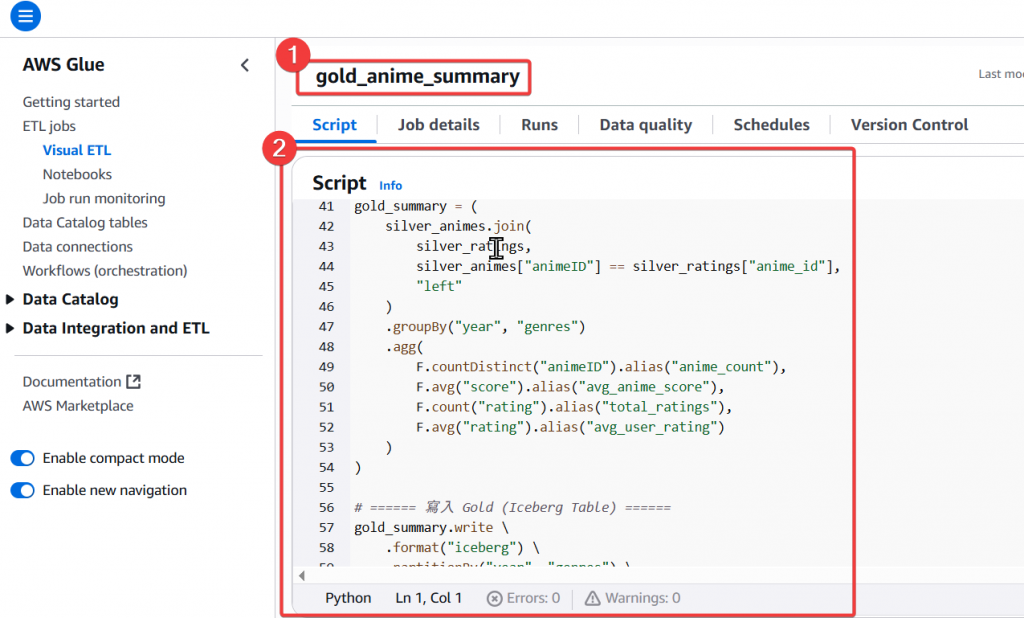
from awsglue.context import GlueContext
from pyspark.context import SparkContext
from pyspark.sql import functions as F
from awsglue.job import Job
# 初始化 Glue Job
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
# Iceberg Catalog 設定
spark.conf.set("spark.sql.catalog.glue_catalog", "org.apache.iceberg.spark.SparkCatalog")
spark.conf.set("spark.sql.catalog.glue_catalog.warehouse", "s3://anime-lake/")
spark.conf.set("spark.sql.catalog.glue_catalog.catalog-impl", "org.apache.iceberg.aws.glue.GlueCatalog")
spark.conf.set("spark.sql.catalog.glue_catalog.io-impl", "org.apache.iceberg.aws.s3.S3FileIO")
# 建立 Gold Database
spark.sql("CREATE DATABASE IF NOT EXISTS gold LOCATION 's3://anime-lake/gold.db/'")
# 讀取 Silver 層資料
silver_animes = spark.table("glue_catalog.silver.animes")
silver_ratings = spark.table("glue_catalog.silver.ratings")
# ====== year 欄位清理:確保 partition 安全 ======
# year:非 4 位數 → 0
silver_animes = silver_animes.withColumn(
"year",
F.when(F.col("year").rlike("^[0-9]{4}$"), F.col("year").cast("int"))
.otherwise(F.lit(0))
)
# genres:NULL 或空字串 → 'Unknown'
silver_animes = silver_animes.withColumn(
"genres",
F.when(F.col("genres").isNull() | (F.trim(F.col("genres")) == ""), F.lit("Unknown"))
.otherwise(F.trim(F.col("genres")))
)
# ====== Join + 聚合 ======
gold_summary = (
silver_animes.join(
silver_ratings,
silver_animes["animeID"] == silver_ratings["anime_id"],
"left"
)
.groupBy("year", "genres")
.agg(
F.countDistinct("animeID").alias("anime_count"),
F.avg("score").alias("avg_anime_score"),
F.count("rating").alias("total_ratings"),
F.avg("rating").alias("avg_user_rating")
)
)
# ====== 寫入 Gold (Iceberg Table) ======
gold_summary.write \
.format("iceberg") \
.partitionBy("year", "genres") \
.mode("overwrite") \
.saveAsTable("glue_catalog.gold.animes_summary")
job.commit()
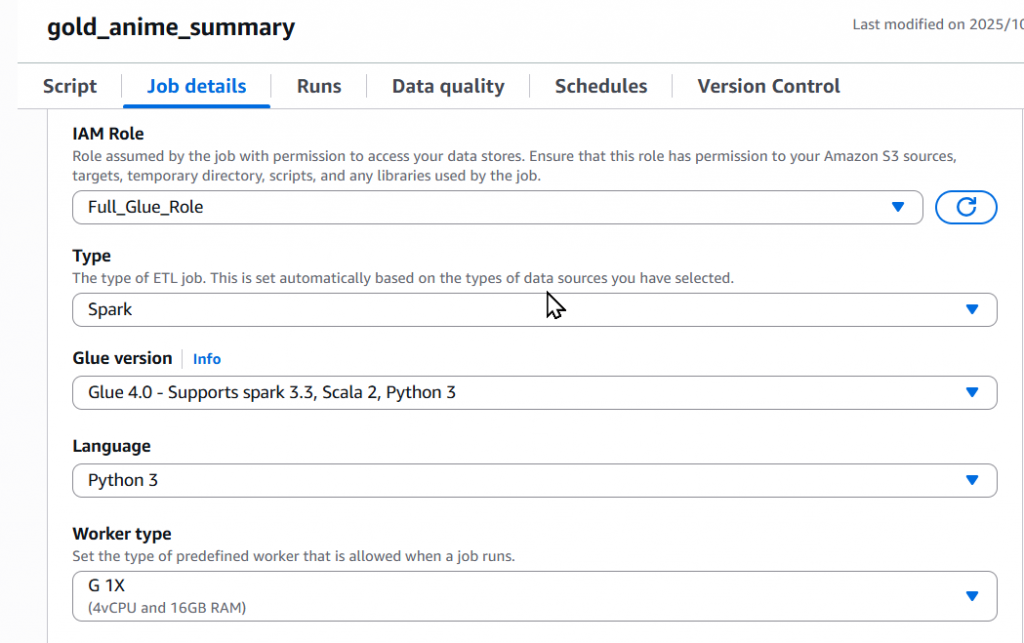
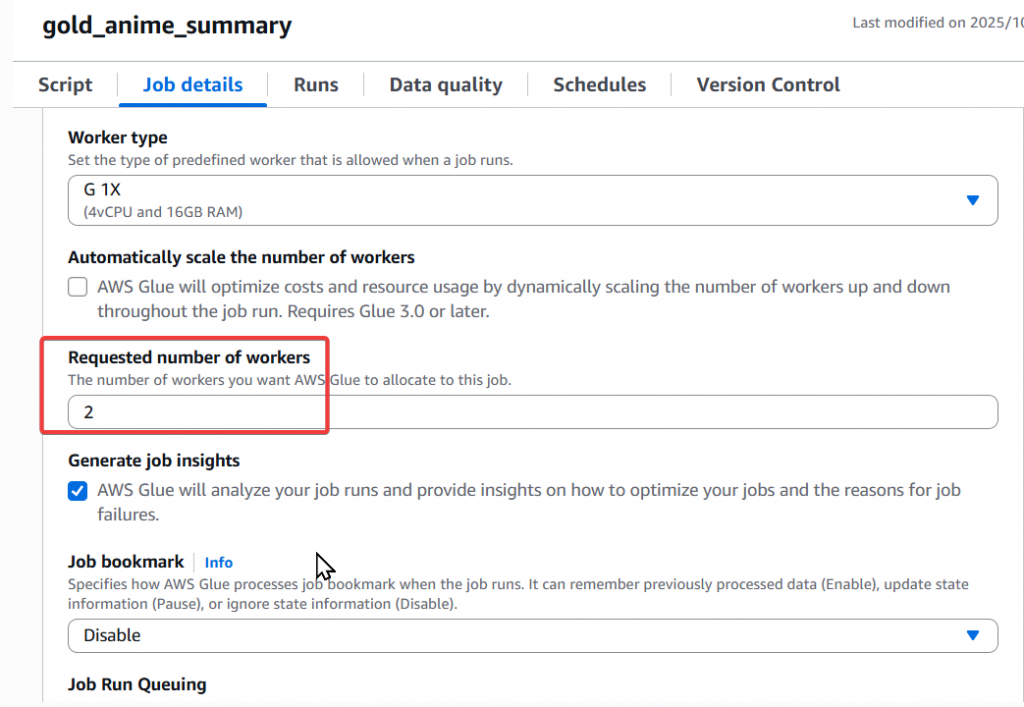
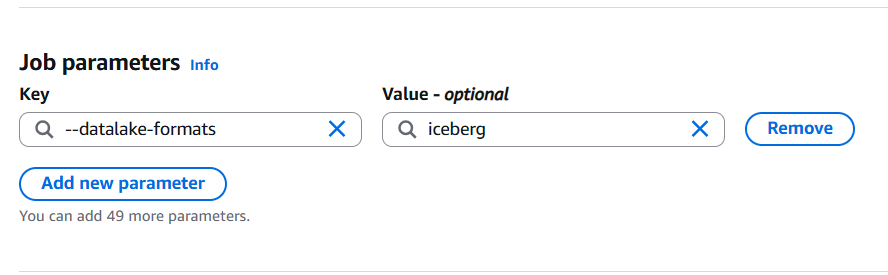
Step2:設定 Job detials
Step3:接著於右上角執行 gold_anime_summary Job,然後確定是否執行成功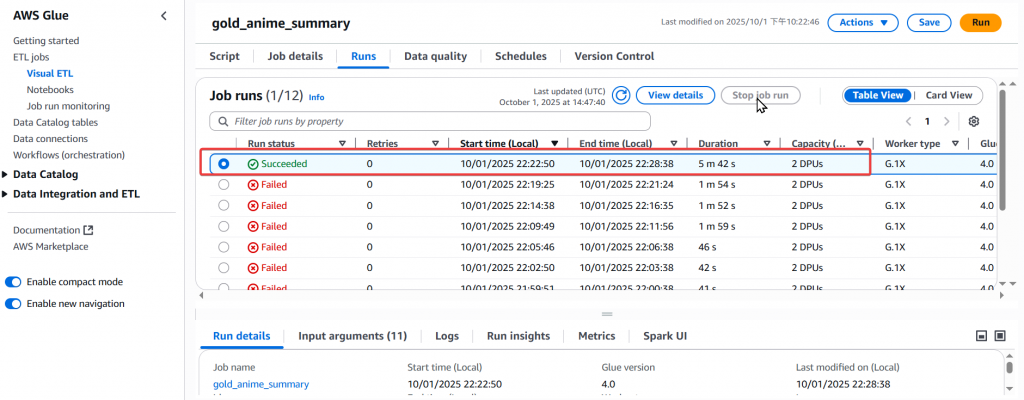
Step4:當 Job 成功後,我們去 Glue Database 與 Table 確認是否有正常建立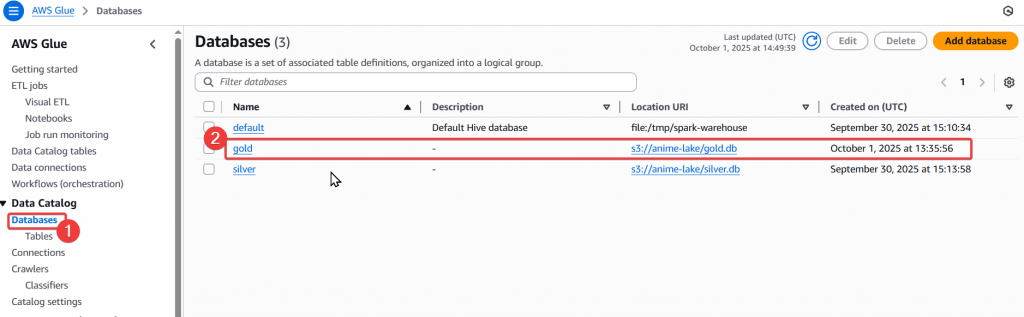
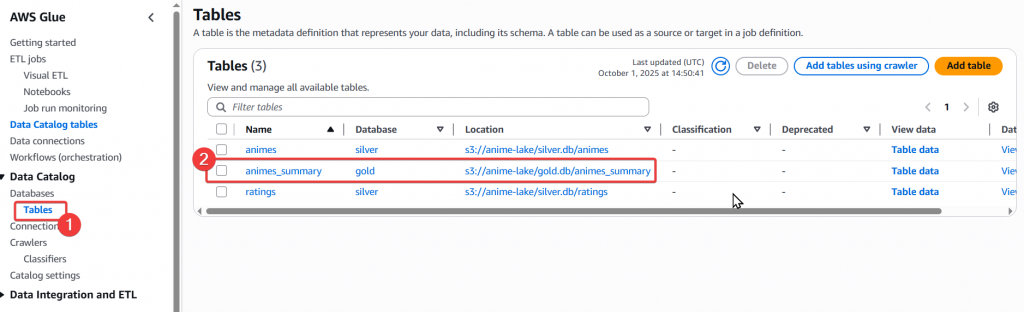
Step5:接著確認一下建立好的 Table Schema 是否為我們所需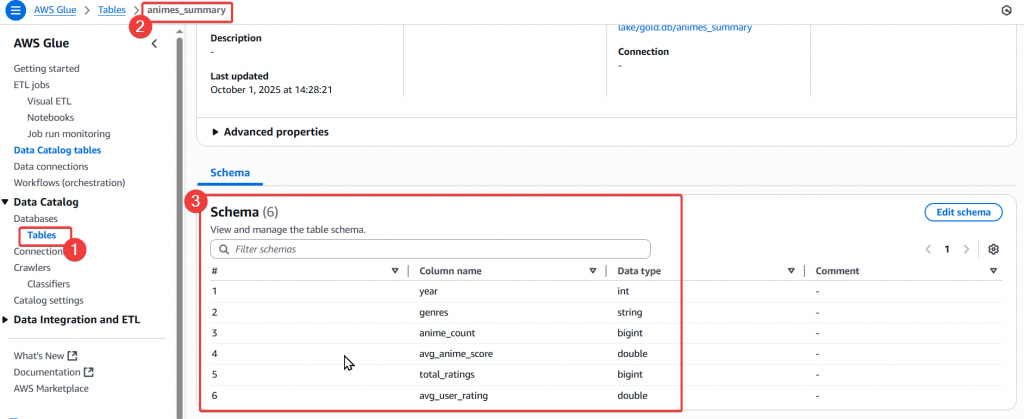
Step6:確認無誤後,我們來確認一下 S3 Data Lake 的儲存結構,首先我們先來確認一下 iceberg 的設計
可以看到 anime-lake 內多了一個 gold.db 的資料夾
進入 gold.db 可以看到剛剛使用 Glue 建立的 animes_summary 資料夾
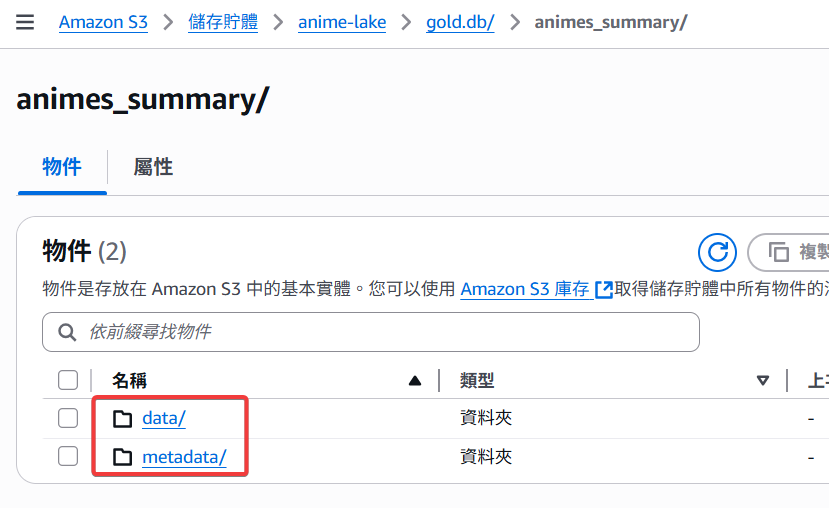
接著進入 animes_summary 我們可以看到:
/data 與 metadata/
/data 內的子資料夾第一層是根據動漫的發行年份 year 做分區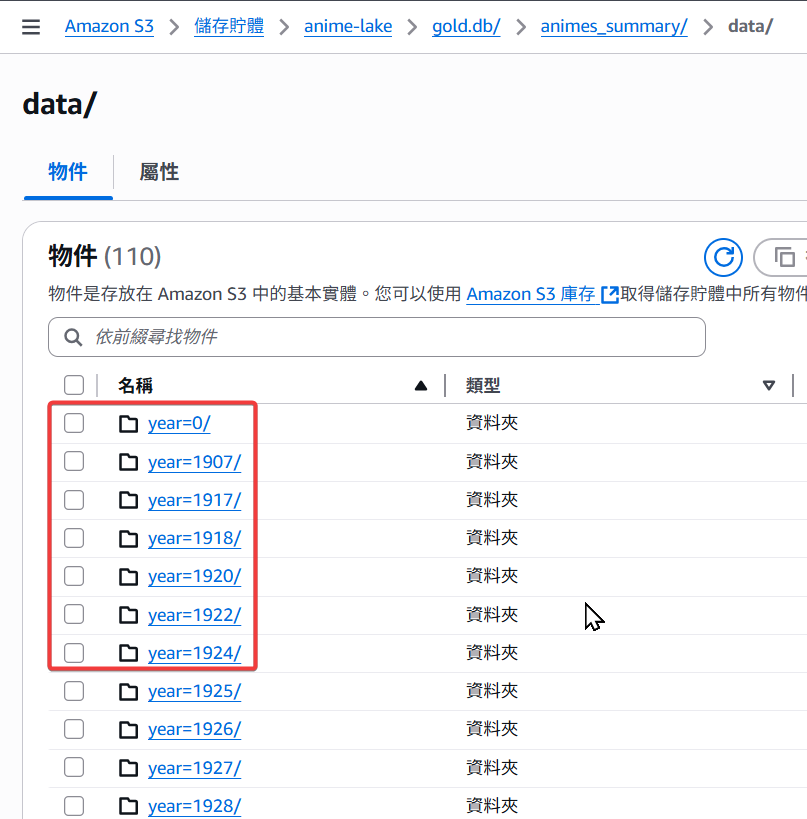
進入 year 子資料夾後,可以看到第二層是使用 genres 來做分區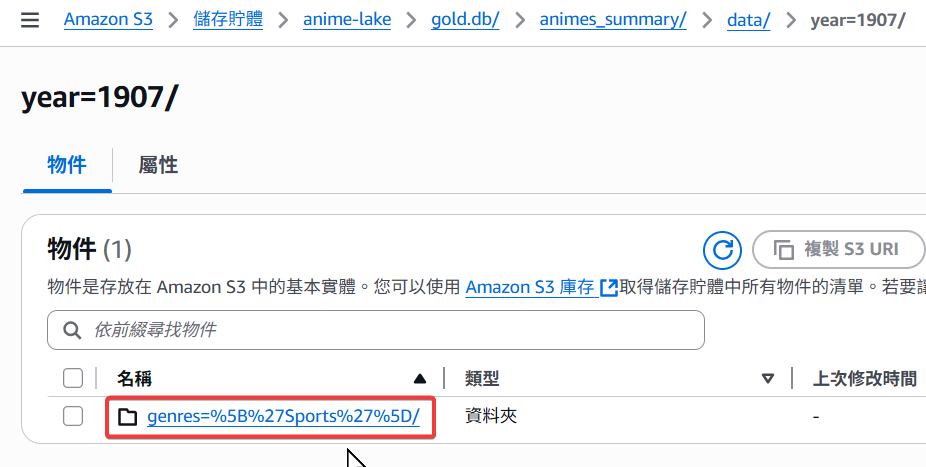
接著不同 genres 會分別有一個 parquet 彙總檔案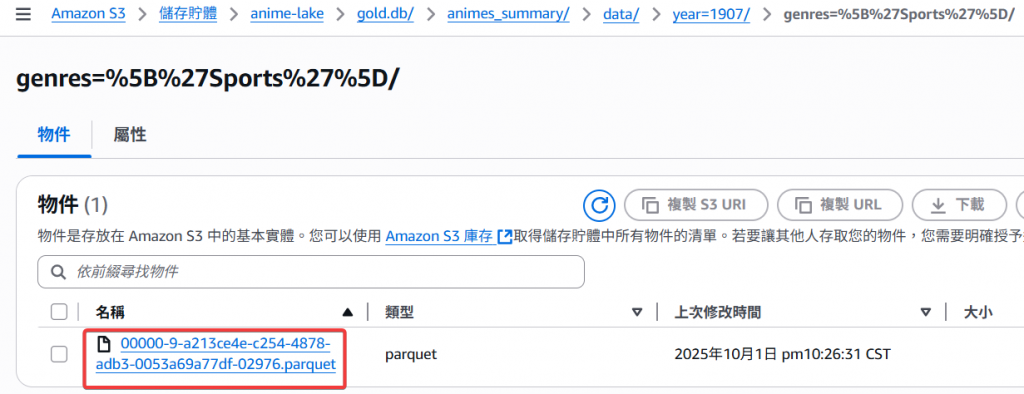
再來是 metadata/,有正常建立 metadata.json 與相關的 .avro 檔案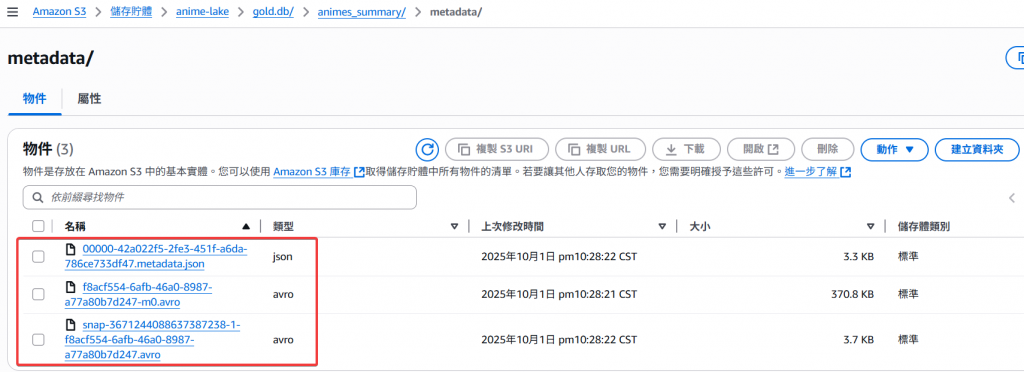
以上即完成 Gold Glue Job 搭配 iceberg 的設計
接下來我們要把 silver job 和 gold job 使用 Glue Workflow 做串接建置成一個 pipeline
Step1:首先我們找到 Glue Workflow,並點選右上角的「Add Workflow」按鈕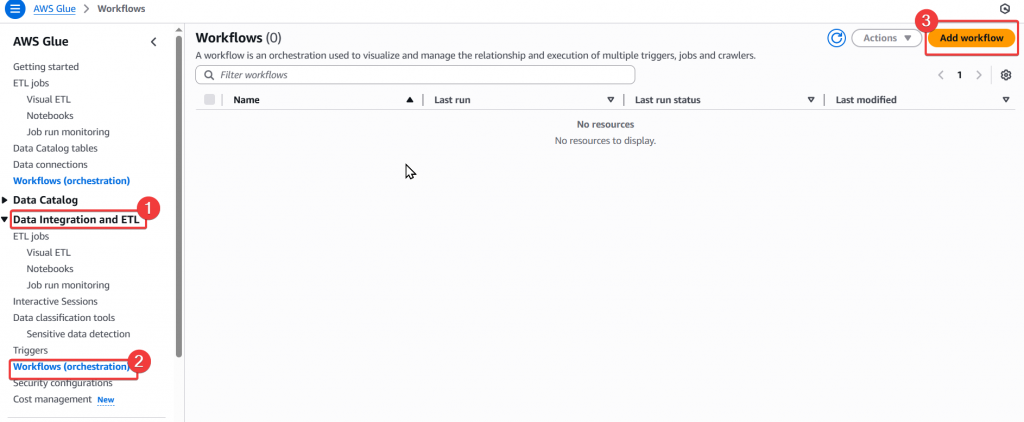
Step2:建置 Workflow 並命名為 wf_animes_summary
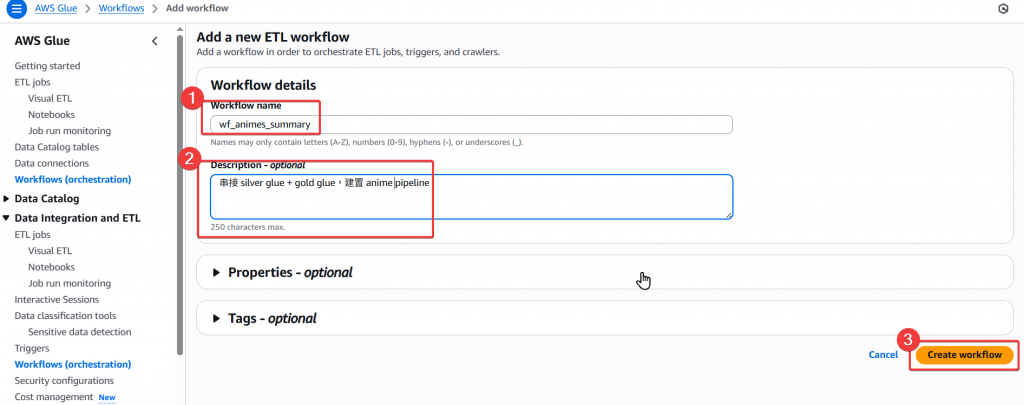
Step3:待跳轉後,確認有實際成功建立 wf_animes_summary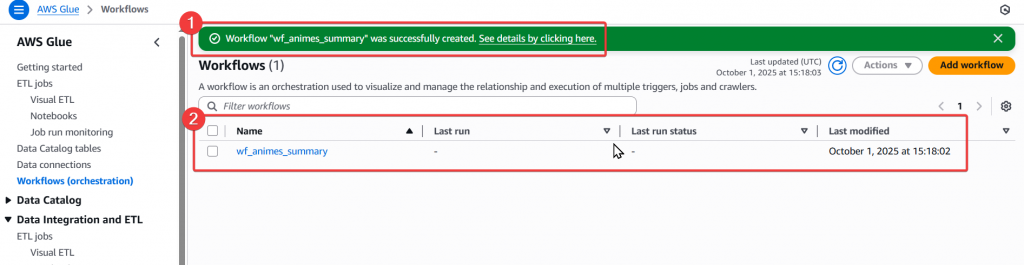
Step4:進入 wf_animes_summary 後,點選下方的 Trigger 按鈕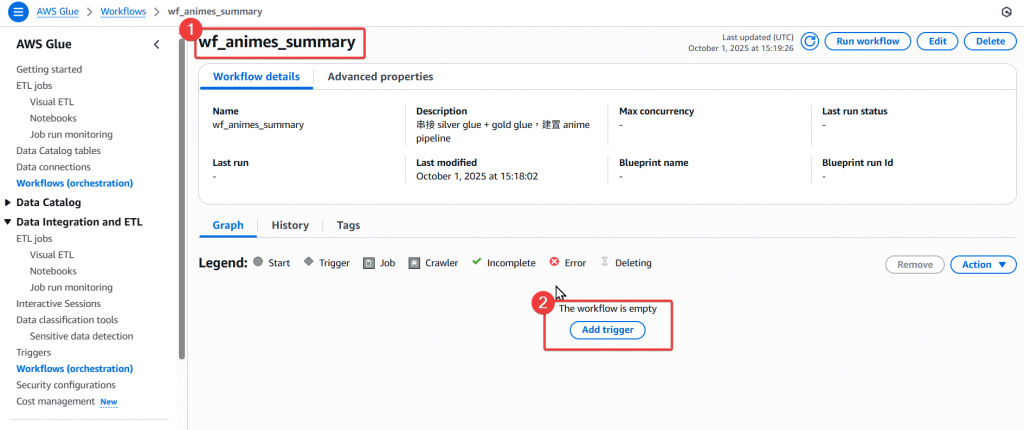
Step5:接著我們來實際建立 Trigger 條件
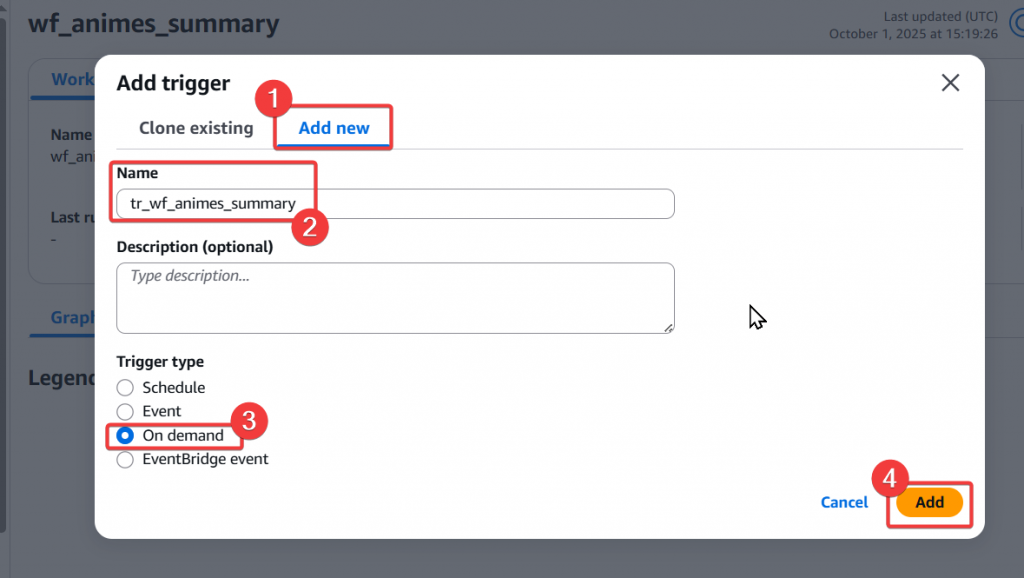
Step6:建立完 Trigger 後,我們要來設定 Pipeline,點選下方的「Add node」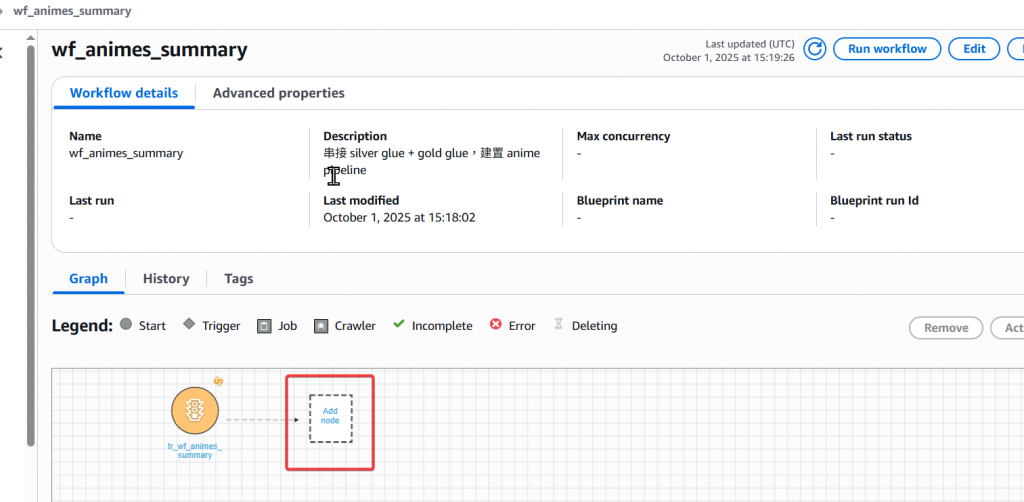
Step7:點進去後會跳出可以選擇前面建立好的 Glue Job 作為 node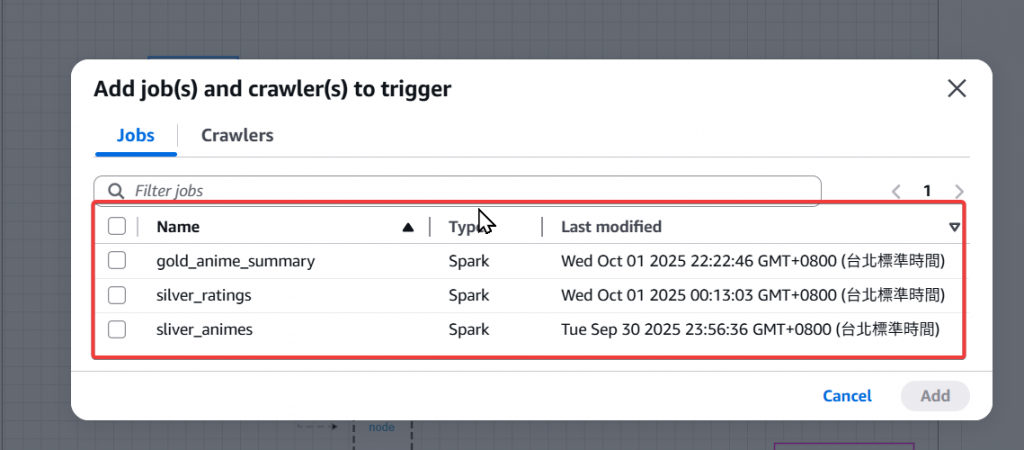
Step8:我們首先先選擇兩個 silver Job 作為前面的 node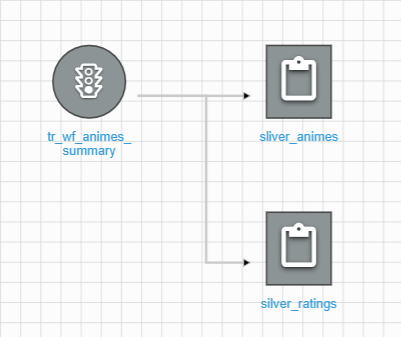
Step9:接著當兩個 silver 都完成後,我要們接續執行 gold job
Step10:點選 Add Trigger 圖形,進入 Trigger 的設定
tr_job_event_all
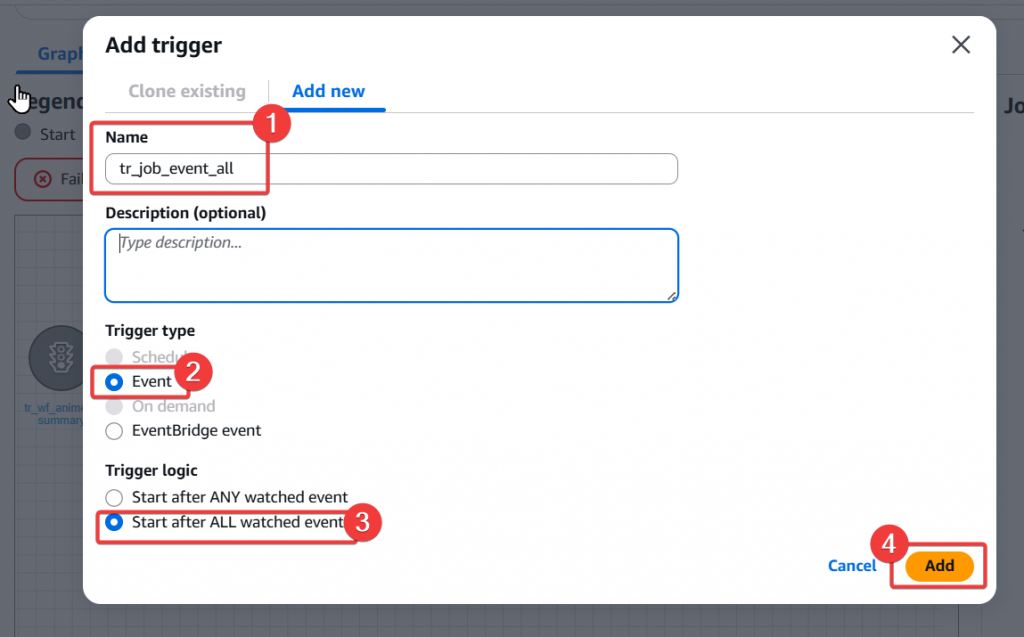
Step11:成功建立新的 trigger 後,我們接續建立 gold job 的 node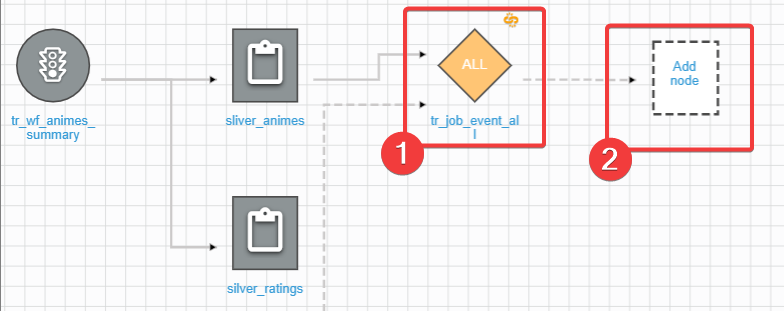
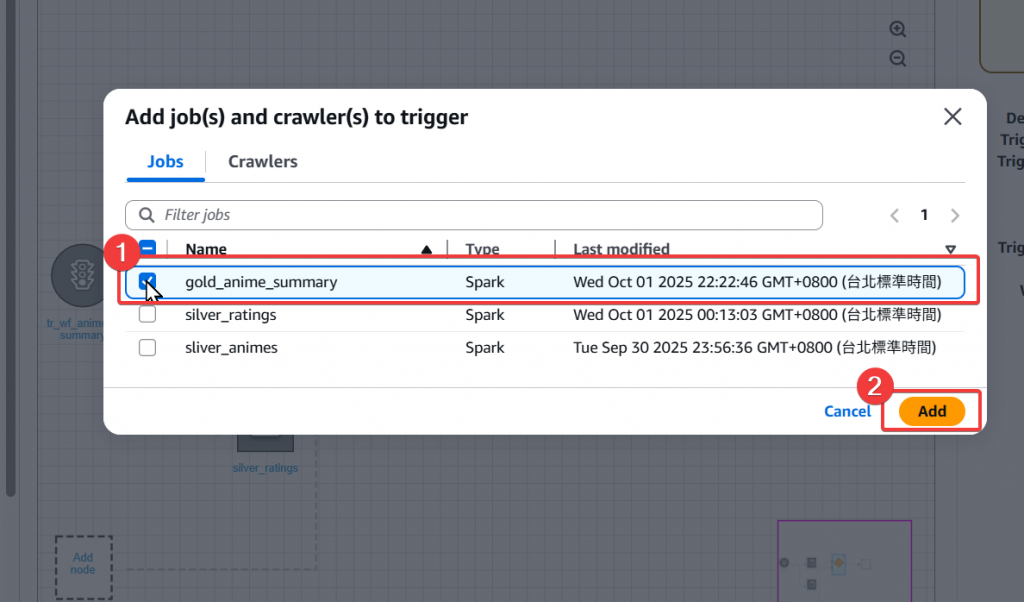
Step12:調整 Trigger Event
tr_job_event_all
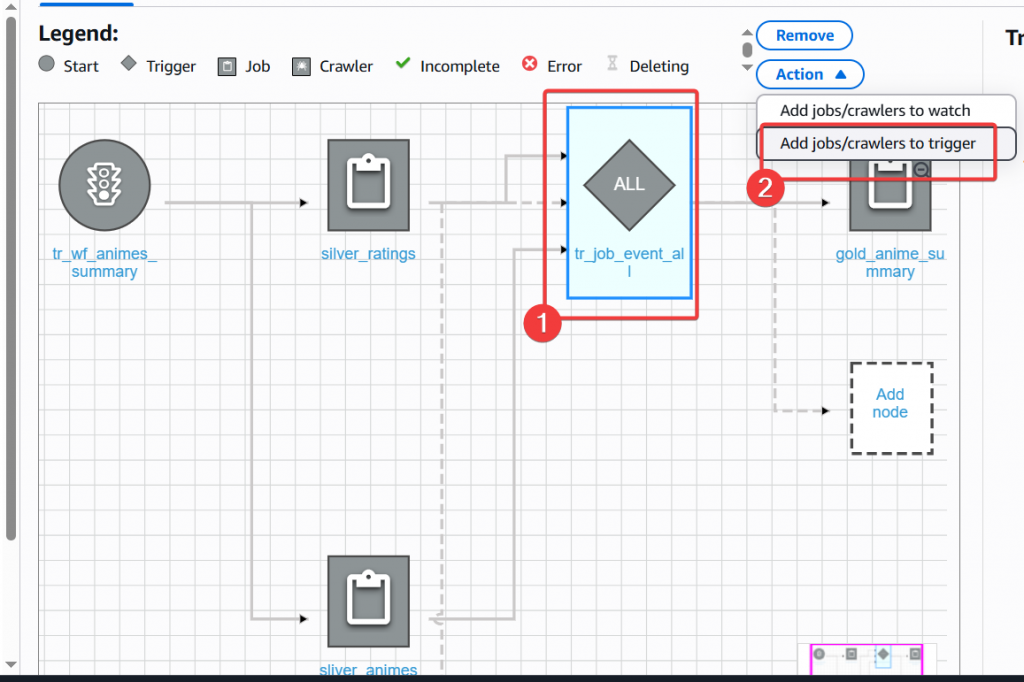
Step13:將 silver animes job 也新增進觸發的 Event 條件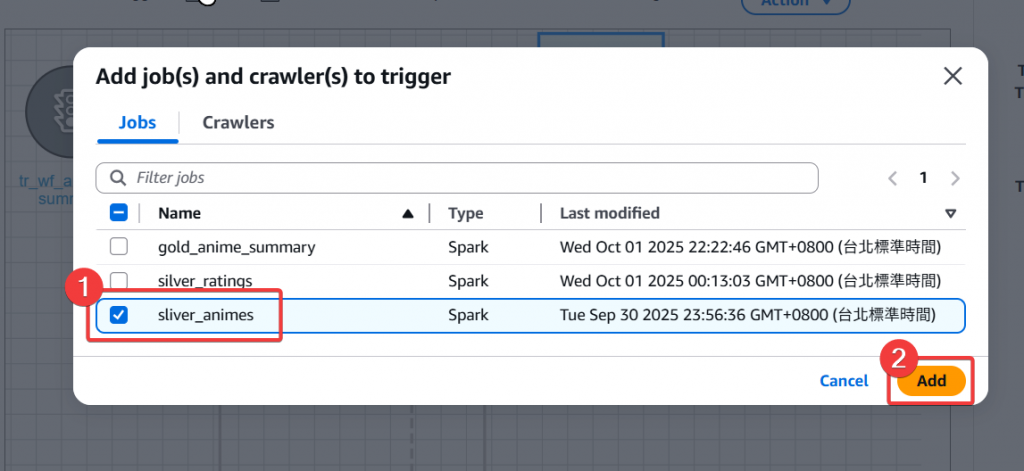
Step14:回到 UI 確認兩個 Silver Job 的線都有關連到 tr_job_event_all 上,即完成 Pipeline 的建置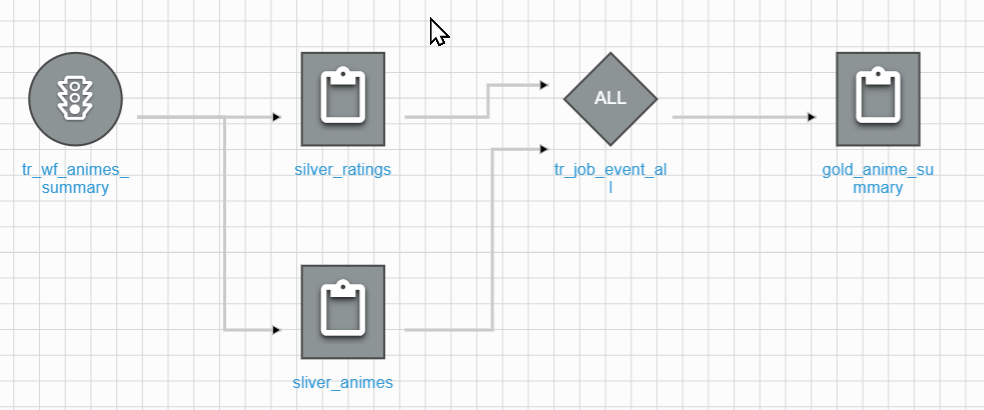
Step15:接著我們來實際執行這個 Workflow,點選頁面右上角的 「Run Workflow」按鈕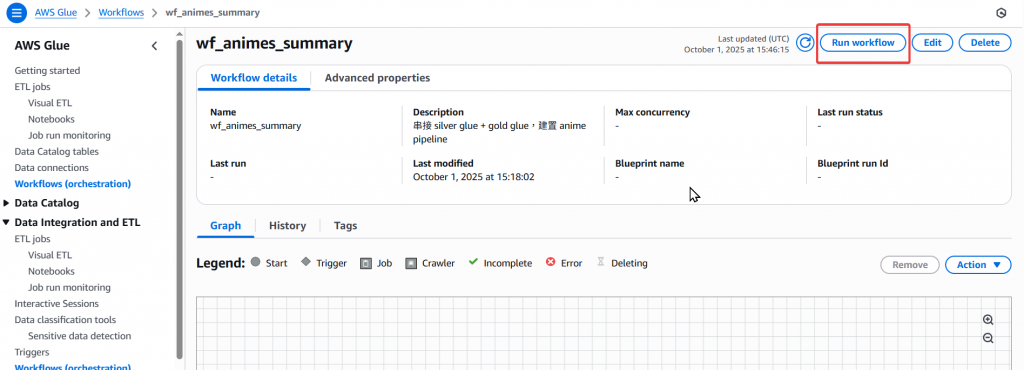
Step16:接著我們可以到「 Job run monitoring 」的頁面,來查看各個 Job 的運行狀況
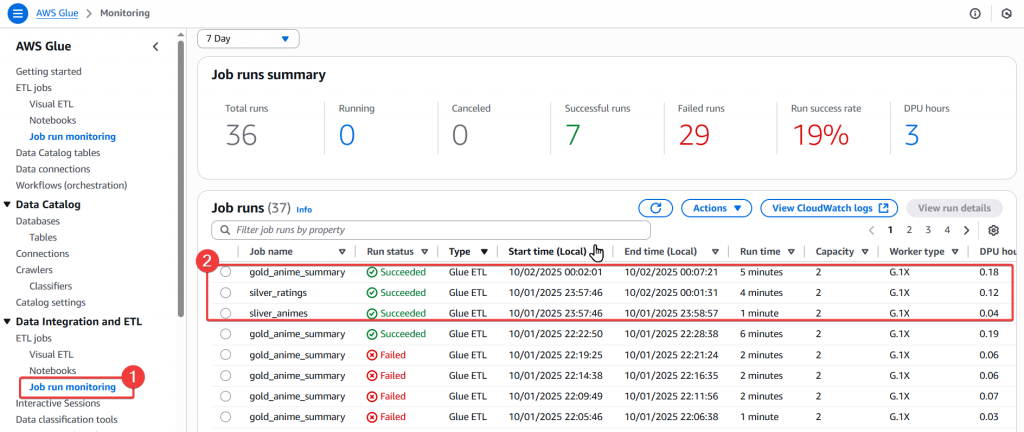
Step17:最後我們回到 Glue Workflow 頁面,來查看排程狀態是否正常完成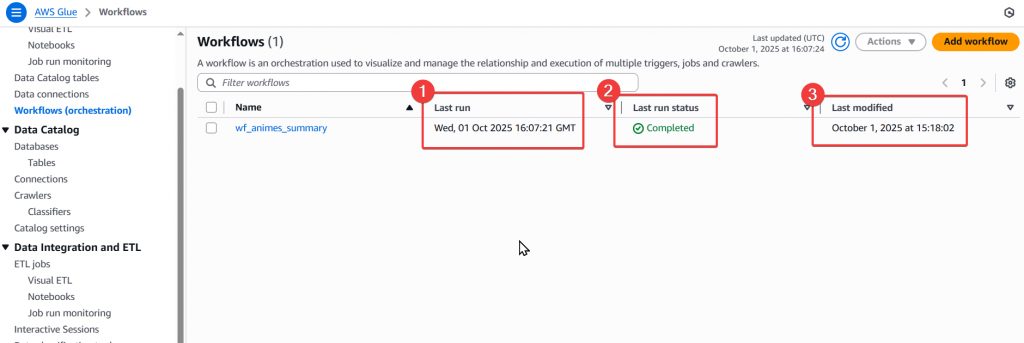
透過以上流程,我們就完成了一個簡易的 Glue Workflow 建置!
今天我們完成了:
gold_anime_summary 的 Glue Job 建立透過以上操作,我們可以手動觸發 Glue Workflow 按照設定好的排程設計,來執行多支 Glue Job
下篇我們將透過「 Day18 淬鍊之章-使用 Lambda 呼叫 Glue Workflow 」來接前面介紹的 S3 Event 觸發和本篇介紹的 Glue Workflow 做串接,變成一個從檔案上傳到 Glue ETL 資料清理並存入 Data Lake 的自動化 Pipeline。


 iThome鐵人賽
iThome鐵人賽