
看完了 ToolHop 與 BFCL 兩個用在 multi-step 的 dataset
今天開始來嘗試跑 toolhop 的 dataset。
先介紹一下,每一題題目大概長怎樣
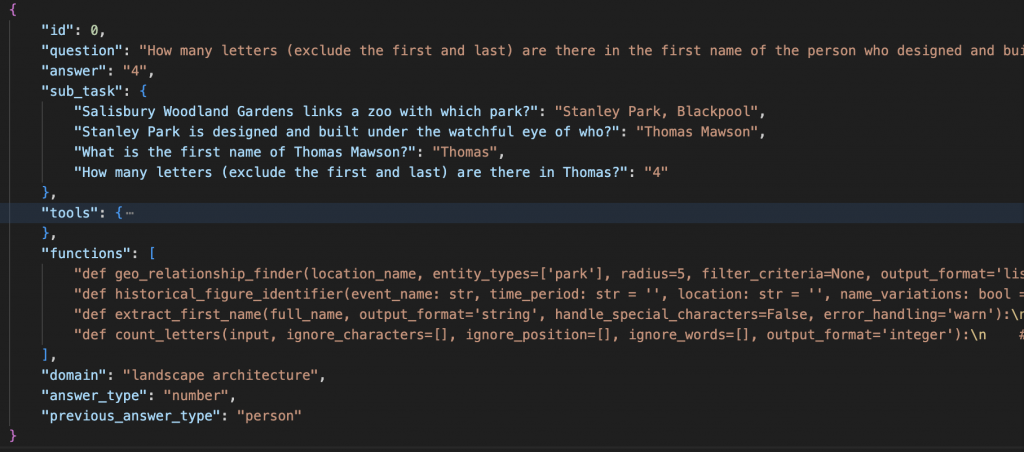
ToolHop 很貼心的提供了 json 檔,裡面包含了 995 題。上面是其中一題
每題我們最主要會用到的 components 有
question : 就是問題answer : 正解tools : 用到的工具 有詳細定義一堆參數functions : 對應 tools 的實際 function,用 string 表示,可以再透過 parse 的方式轉成可執行的 function我們原本在 Reasoning state 的設計是透過 prompt 的方式讓 gpt 輸出 action 的 json 格式後,再自己 parse action 出來使用
但遇到了一個難題,如果用相對較弱的 model,e.g., gpt-4.1-mini
在不仔細調整 prompt 的情況下,即使我們已經用了 json_repair 這個 package,能夠在 gpt 少生成逗號, / 括號{} / string 的 “” 時幫忙修復。
但很殘念的還是 瘋 狂 出 錯,要吐血了。
看了一下測試的 tool 到底多複雜 請看...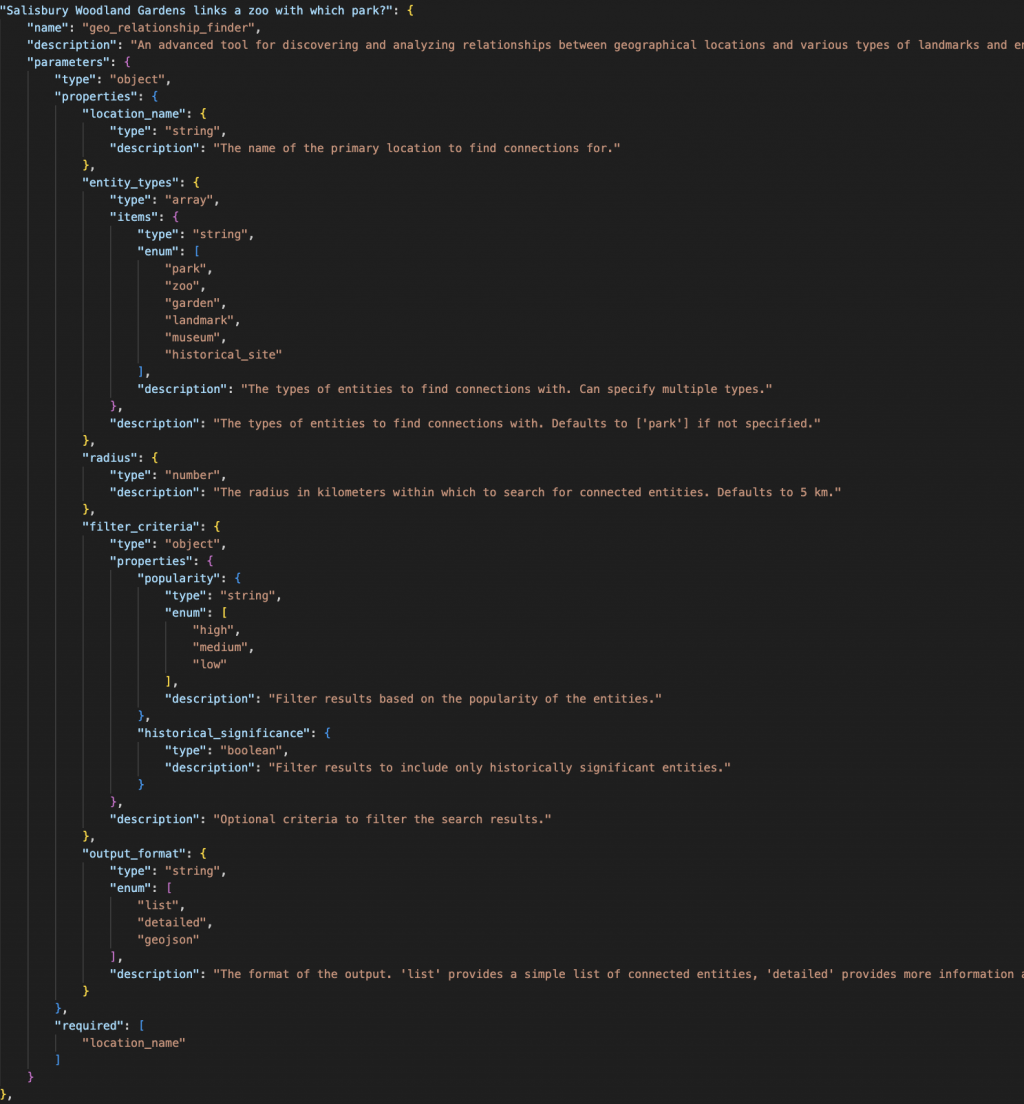
原來上面是一個 tool 的詳細定義,然後每題平均會有 4 個 tools
... 恩,難怪一直 gpt 一直生錯
其實我們有幾種解法
那什麼是 FC ?
其實是昨天 survey BFCL 看到的東東,以下是他們的定義FC = native support for function/tool calling.Prompt = walk-around for function calling, using model's normal text generation capability.
昨天看到這個時,不以為然。想說都是同一個 model,走 native 的 function calling 還是透過 prompt 的方式請 gpt 生成 action schema 應該不會差那麼多吧 ==
仔細一看排名,整個 overall 的分數 prompt 是被 FC 暴打的。
但 再仔細看了一下不同領域的分數,其實除了 agentic 領域之外,感覺 performance 的上限 是更高的
(下圖是 Hallucination Measurement 感覺寫錯了,如果用上面的分數來看,應該是 agentic domain 輸慘)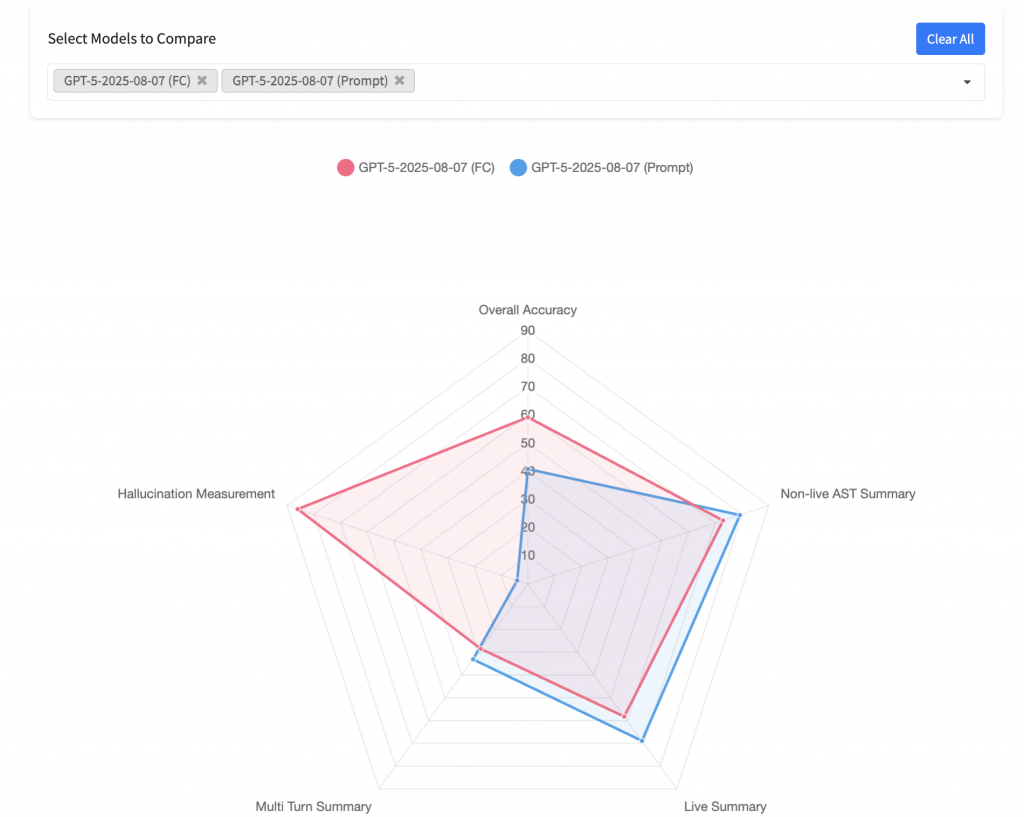
但不知道他們 prompt turn 了多久,但應該有 release prompt 可以再去偷一下
看到這,就決定先走 FC 了。
今天時間有點不夠,明天繼續研究一下 openai 的 FC 怎麼使用再與大家分享
