在 Day17 淬鍊之章-Glue 實作篇-2 中,我們已經介紹了 Glue Workflow,它能將多個 Glue Job 串接成一個完整的資料處理流程。
今天我們要進一步把 S3 事件觸發 EventBridge 與 Lambda 結合,當新檔案上傳到指定的 Bucket 時,就能自動觸發 Glue Workflow 做 ETL。
這樣的設計,能將手動操作完全自動化,實現事件驅動的數據管線 (Event-driven Data Pipeline)。
當我們把所有組件串起來後,完整的流程會長這樣:
使用者 / 系統上傳檔案到 S3
s3://anime-lake/bronze/animes/s3://anime-lake/bronze/ratings/
S3 事件通知 (EventBridge)
Lambda Function
Glue Workflow 執行
了解大概的流程後,我們就來開始改寫 Lambda 讓它可以呼叫昨天建置好的 Glue Workflow。
要讓 Lambda 可以使用 Glue,我們需要幫 Lambda 的 Role 也就是 Full_Lambda_Role 新增 Glue 的 Policy。
Step1:首先登入使用者 Joe,並至 IAM 找到 Full_Lambda_Role,點選「Add permissions」後選擇「Attach Policy」。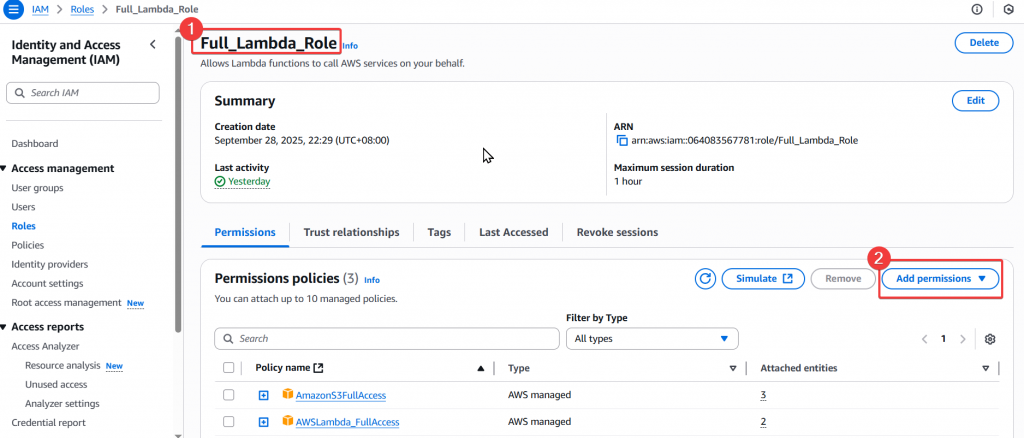
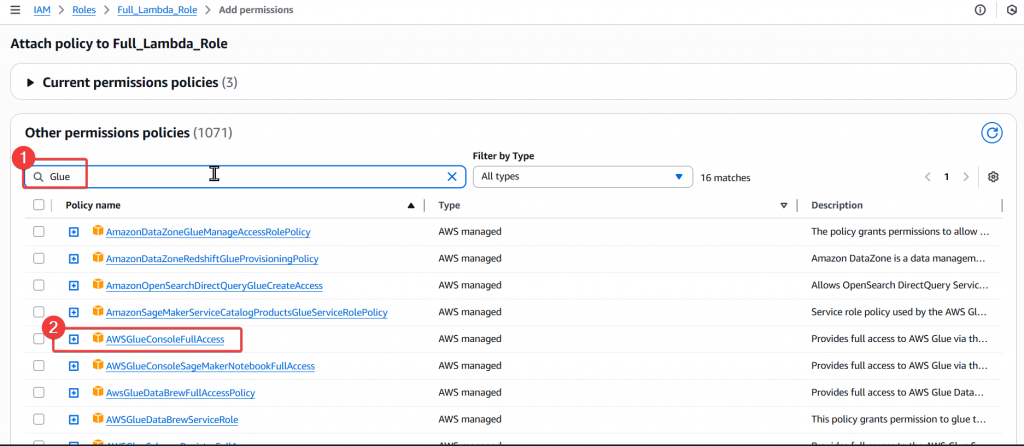
Step2:接著搜尋 Glue 的 Policy,選擇 AWSGlueConsoleFullAccess 後點選右下角 「Add permissions」。
Step3:當頁面跳轉後,確認有正常新增了 AWSGlueConsoleFullAccess Policy,即完成新增 Policy 給 Full_Lambda_Role,這樣 Lambda 就可以透過這個 Role 來呼叫 Glue 了。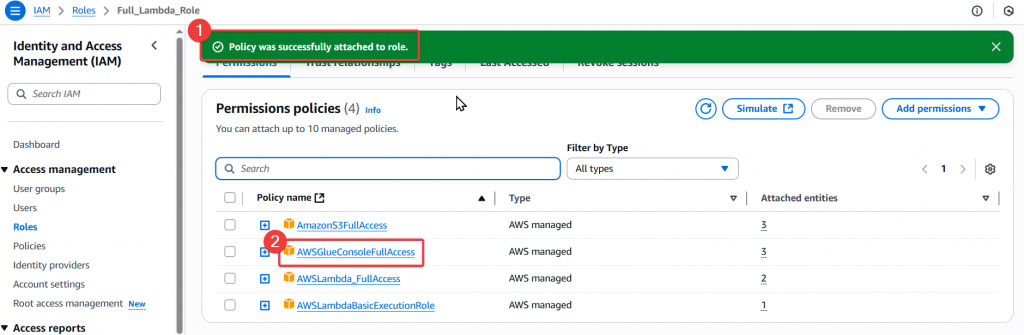
添加完 Role 的 Policy 後,我們首先先切回使用者 Andy,然後我們要來調整 Lambda 的 Python Shell。
Step1:找到 Lambda 函式 anime-lake-bronze-partition,並點擊進入該函式頁面。
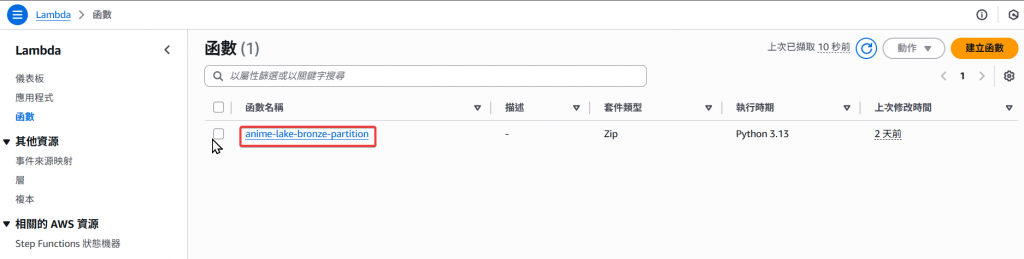
Step2:接著來改寫該 Lambda 新增呼叫 Glue Workflow wf_animes_summary 的程式,接著做 Deploy。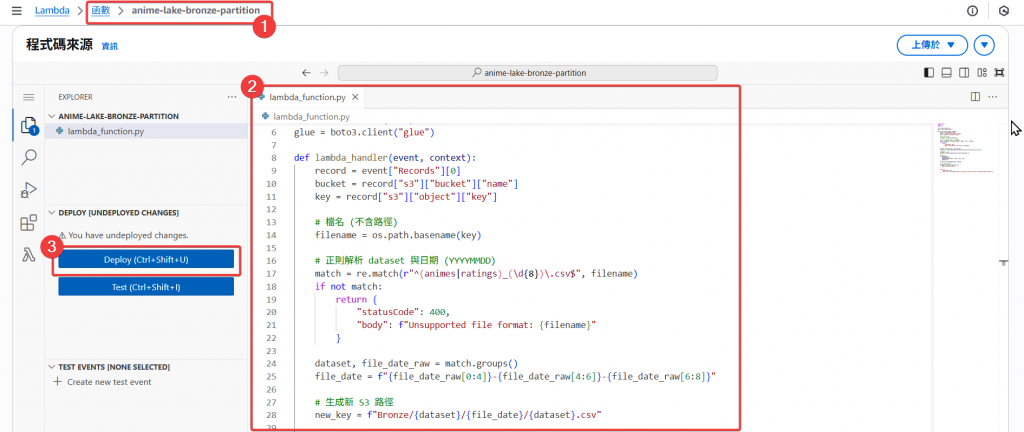
import boto3
import os
import re
s3 = boto3.client("s3")
glue = boto3.client("glue")
def lambda_handler(event, context):
record = event["Records"][0]
bucket = record["s3"]["bucket"]["name"]
key = record["s3"]["object"]["key"]
# 檔名 (不含路徑)
filename = os.path.basename(key)
# 正則解析 dataset 與日期 (YYYYMMDD)
match = re.match(r"^(animes|ratings)_(\d{8})\.csv$", filename)
if not match:
return {
"statusCode": 400,
"body": f"Unsupported file format: {filename}"
}
dataset, file_date_raw = match.groups()
file_date = f"{file_date_raw[0:4]}-{file_date_raw[4:6]}-{file_date_raw[6:8]}"
# 生成新 S3 路徑
new_key = f"Bronze/{dataset}/{file_date}/{dataset}.csv"
# 搬移檔案
s3.copy_object(
Bucket=bucket,
CopySource={"Bucket": bucket, "Key": key},
Key=new_key
)
s3.delete_object(Bucket=bucket, Key=key)
# 呼叫 Glue Workflow
response = glue.start_workflow_run(
Name="wf_animes_summary"
)
return {
"statusCode": 200,
"body": f"File {filename} moved to {new_key}, workflow started with RunId={response['RunId']}"
}
Step3:Deploy 後,我們來重新上傳 S3 File 到 Bronze 資料夾,看看會不會自動觸發 Event。
animes_20251002.csv 至 animes/
ratings_20251002.csv 至 ratings/
Step4:接著我們可以至 Glue 的 「Job run monitoring」頁面,來確認是否有正確的觸發 Glue Workflow。
sliver_animes、silver_ratings、gold_anime_summary 等 Job 都有被正常觸發。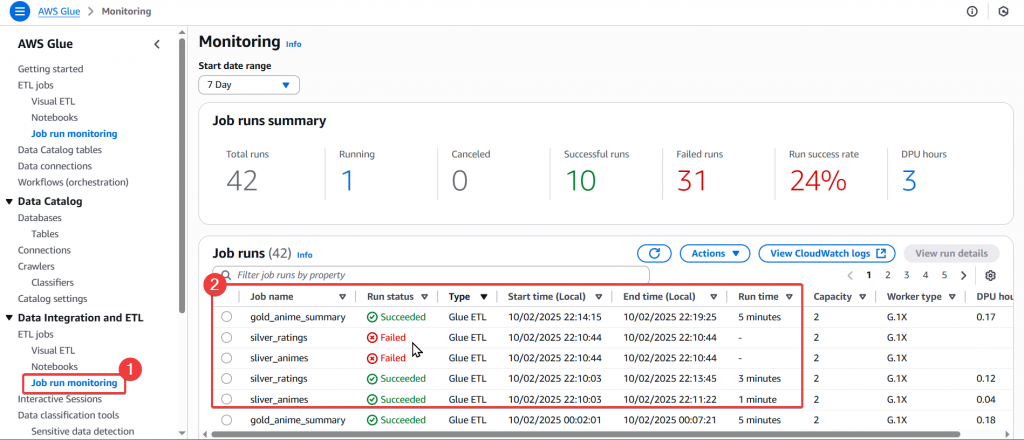
在本篇中,我們完成了 S3 → Lambda → Glue Workflow 的串接流程,讓資料從檔案上傳後即可自動進入 ETL Pipeline。整個過程中,我們將檔案依日期進行 Bronze 分層,並由 Glue Workflow 負責清理、轉換與最終寫入 Silver/Gold 層,達成 事件驅動的資料管線。
然而,在實測中我們也觀察到一個問題:
下篇我們將透過「 Day19 淬鍊之章-使用 Athena 驗證資料 」來介紹 Athena 是什麼,並實際應用此服務結合 Glue Catalog 來對 Data Lake 內的資料做 SQL Query 的操作。
[1] AWS Glue Workflow 官方文件
[2] Using AWS Lambda with Amazon S3
[3] Amazon EventBridge 入門
[4] AWS Glue Job Triggers


 iThome鐵人賽
iThome鐵人賽