在上篇 Day18 淬鍊之章-使用 Lambda 呼叫 Glue Workflow 中,我們已經把資料寫入到 Iceberg。
本篇要介紹 Amazon Athena 這個 AWS 服務,並且搭配 Glue Data Catalog 來查詢我們 Data Lake 內的資料。
主要目的:
Amazon Athena 是 AWS 提供的一個 Serverless(無伺服器)互動式查詢服務。
它最大的特色是「免基礎設施管理」:
數據驗證與探索 (Data Validation & Exploration)
ETL 工作的輔助工具
下游商業智慧 (BI) 整合
跨來源查詢 (Federated Query)
事件驅動分析
💡 小總結:
接著讓我們看看如何使用 Athena 吧!
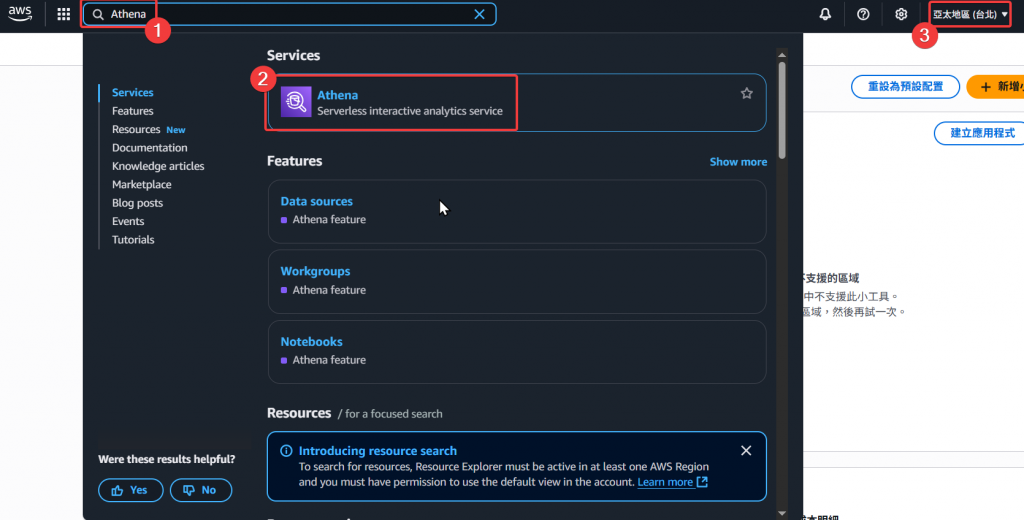
Step1:本次我們登入使用者 Andy,並於查詢 Athena 服務,然後點擊進入 Athena 頁面。
記得也要選擇台北區域,才能正常顯示 Catalog 和相關 DB、Table。
Step2:接著我們點選「探索查詢編輯器」進入查詢頁面。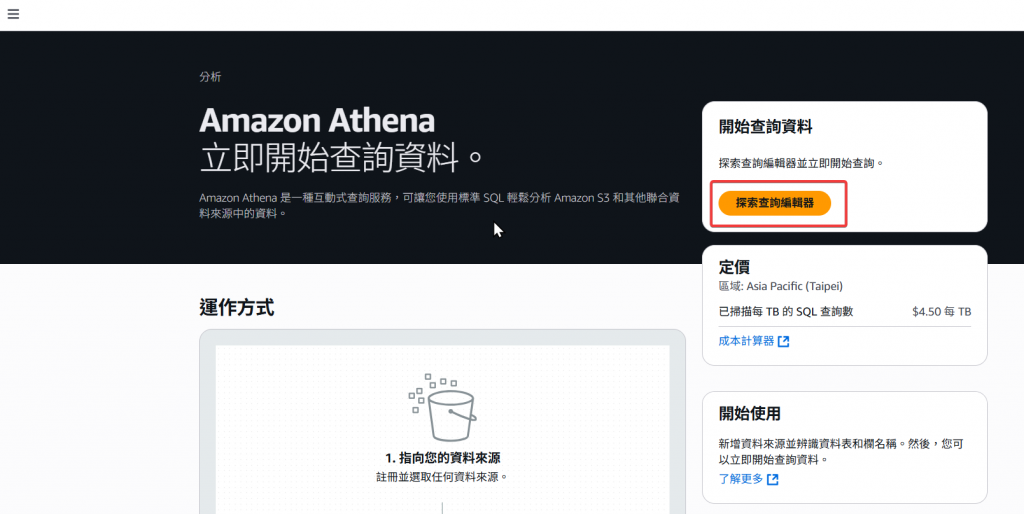
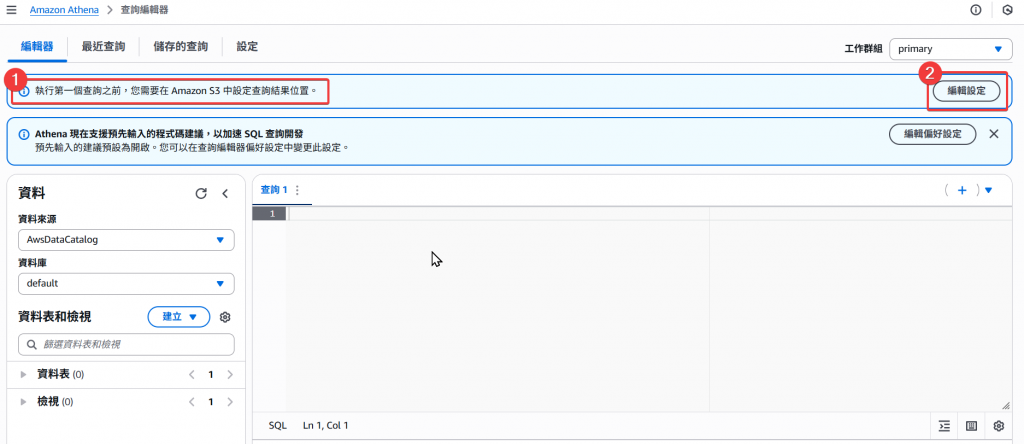
Step3:在使用 Athena 之前,我們要先設定 Athena 查詢後產出檔案的存放位置,所以我們要先點擊「編輯設定」。
Athena 每次在查詢時,都會自動儲存一個查詢的產出檔案 .csv 到儲存路徑下。
Step4:既然是儲存,當然就會運用到我們的 S3 服務,但此時還尚未有建立 Athena 查詢輸出檔案的儲存路徑。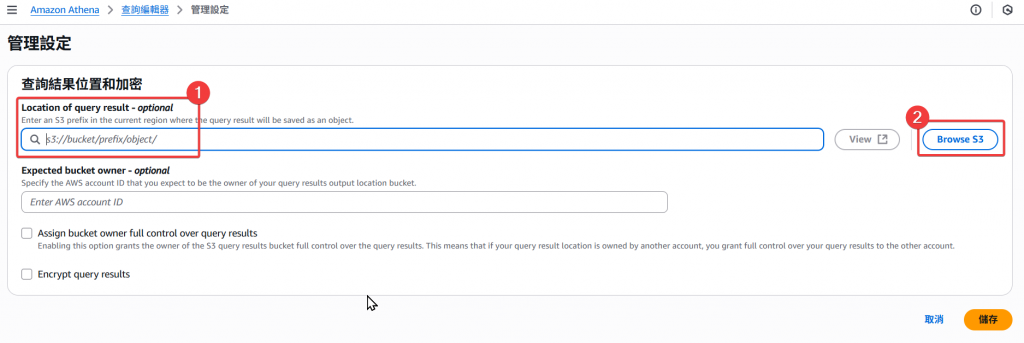
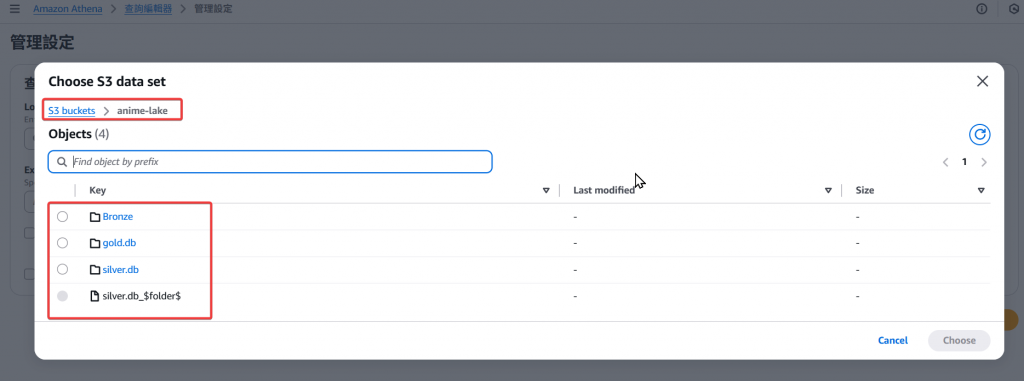
Step5:接下來我們需要於 S3 建立一個 Athena 專用的儲存 Folder
Athena (可自行命名)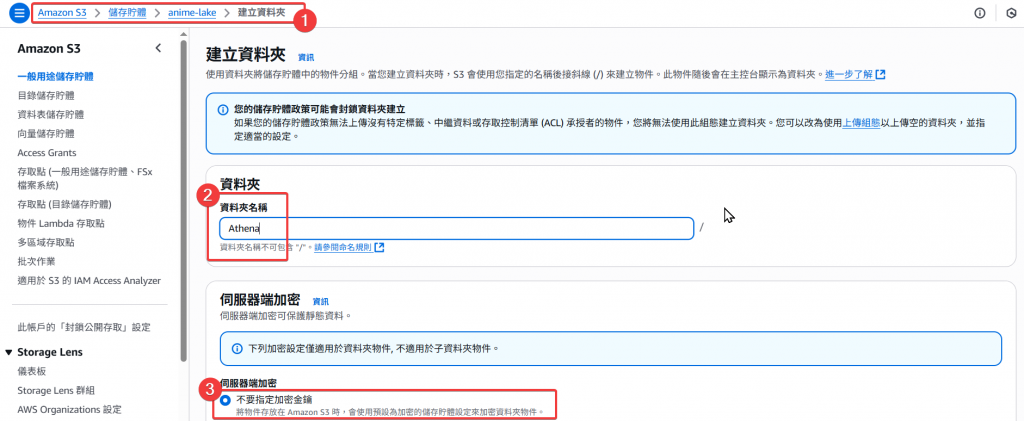
Step6:再來我們就可以回到剛剛 Athena 選擇儲存路徑的畫面,選擇我們剛剛建立好的 Folder 路徑作為後續的Athena 查詢檔案存放位置。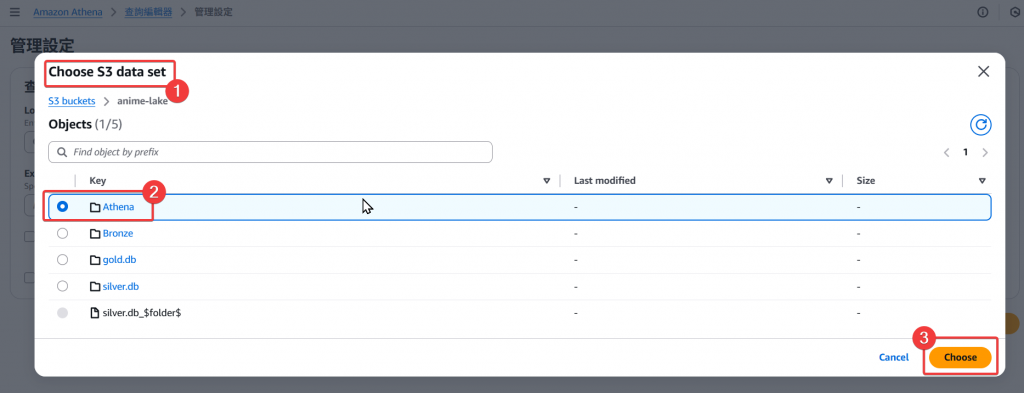
Step7:接著確認儲存路徑無誤後,就可以儲存設定了。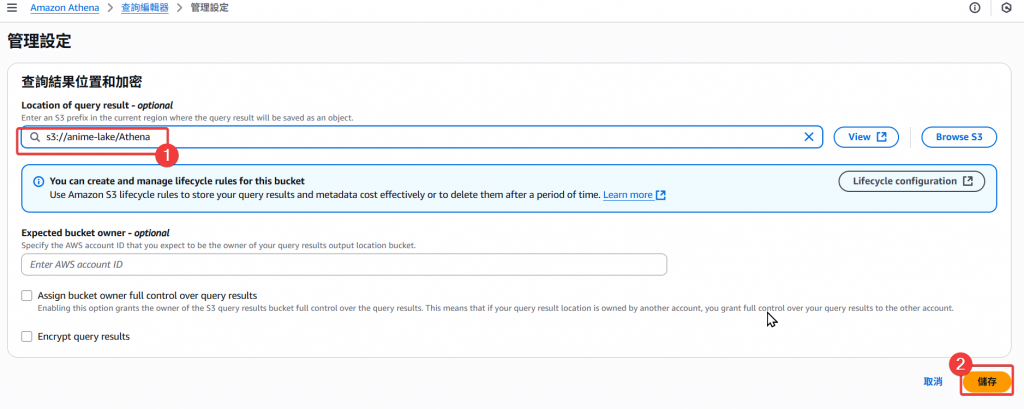
Step8:跳轉後我們就可以看到該 Athena 的工作群組,查詢產出檔的儲存位置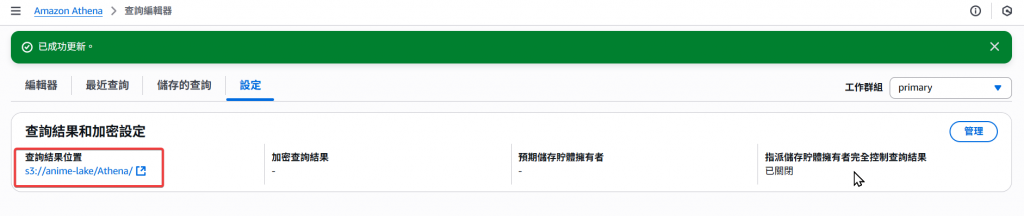
Step9:接著我們回到編輯器的地方
AwsDataCatalog,這是此帳號在台北區域唯一的 Catalog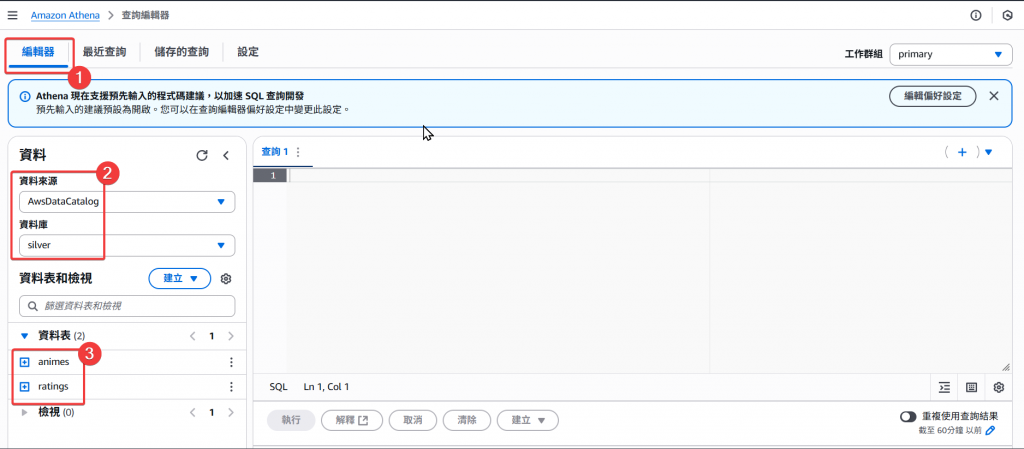
Step10:再來我們來實際查詢 silver 內的 animes Table
SQL:
SELECT * FROM "silver"."animes" limit 10;
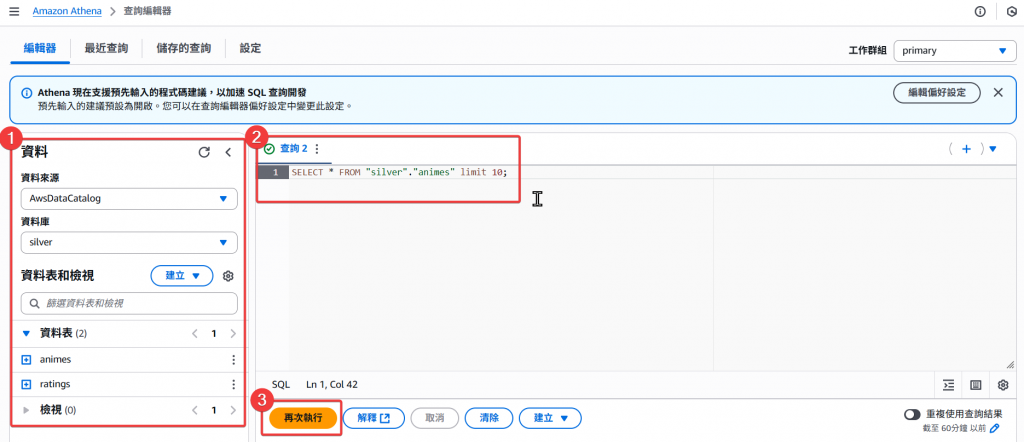
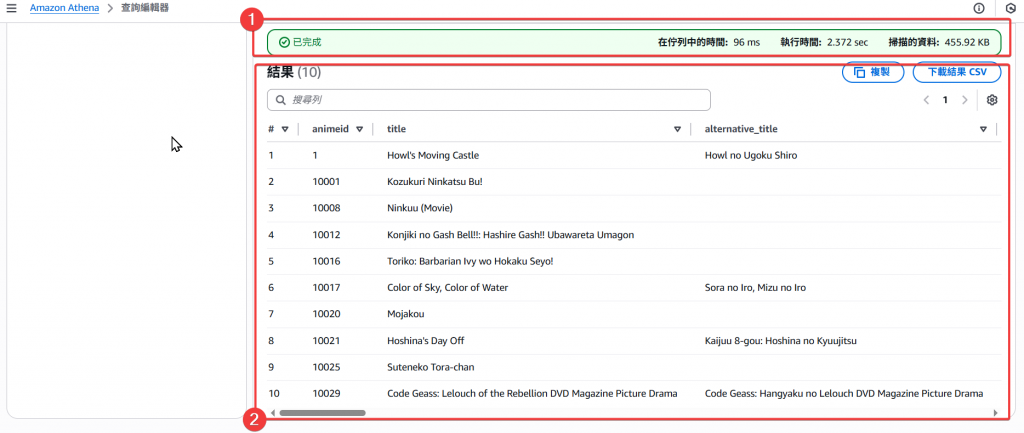
Step11:接著我們回到 S3 Athena 的路徑下,查看有無正常建立查詢儲存檔
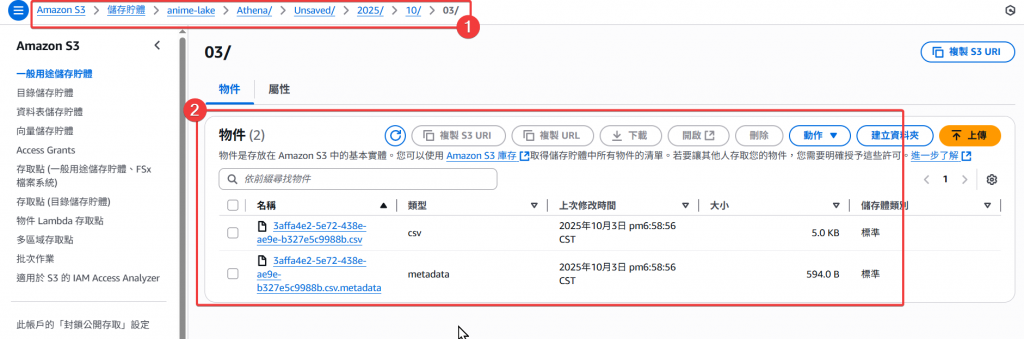
Step12:除了 silver Table 以外,我們也來看一下 gold Table
SELECT * FROM "gold"."animes_summary" limit 10;
Step13:除了基本的 Select 語法,我們也可以在做一些根據 Column Order By 的操作
SELECT
*
FROM "gold"."animes_summary"
ORDER BY avg_anime_score
limit 10
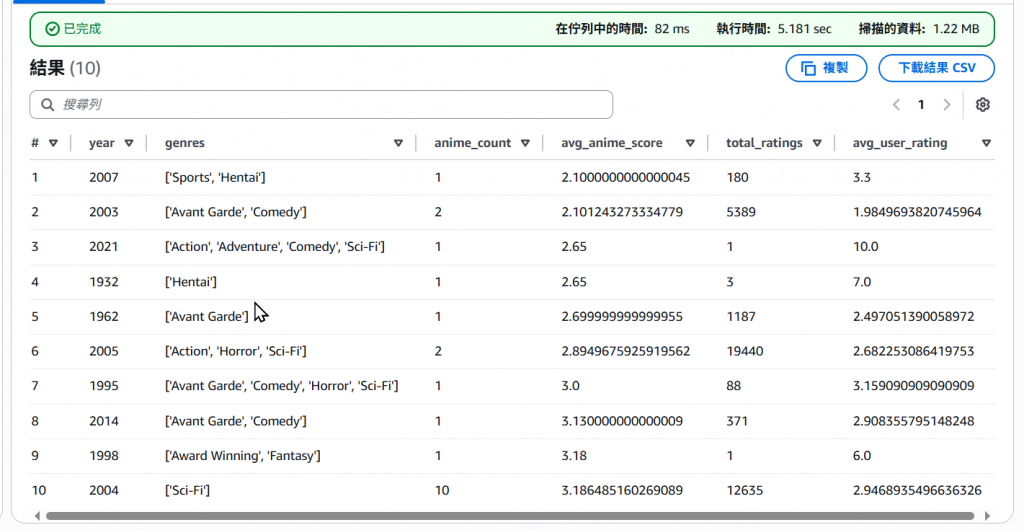
總而言之就是一般的 SQL 用法,你可以自己做分類、篩選、排序等操作,但請注意查詢量的耗用。
Step14:接著我們也可以針對剛剛的查詢語法做儲存。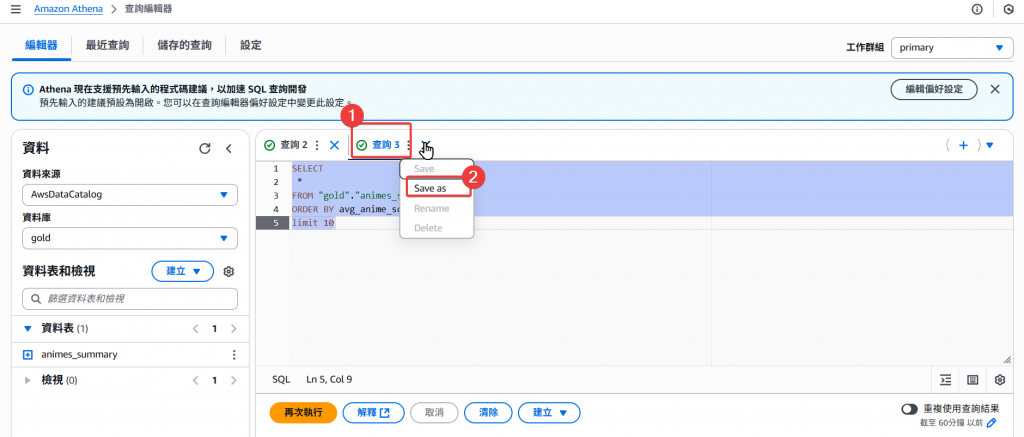
Step15:接著設定 Query 查詢的儲存名稱、描述、預覽後,即可按儲存。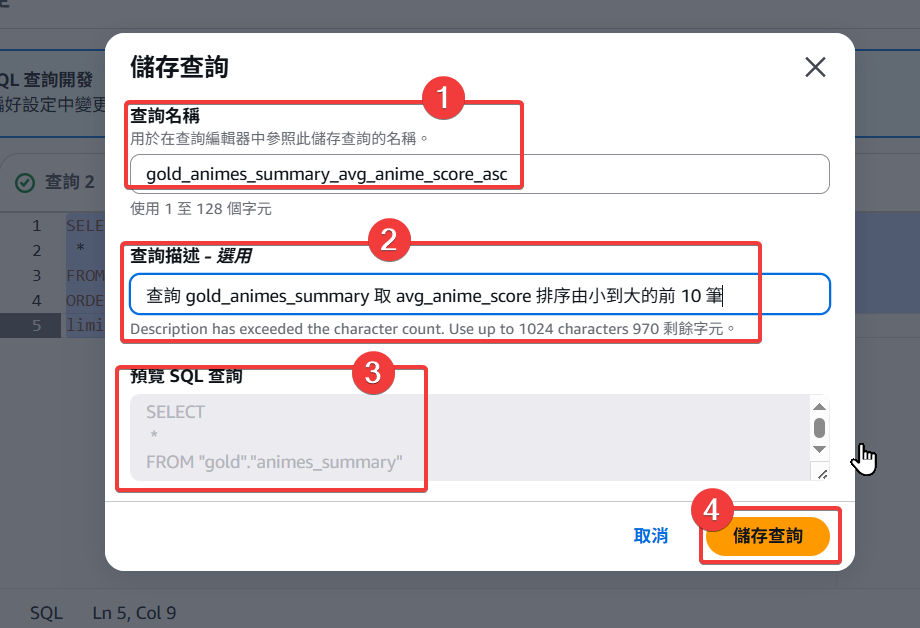
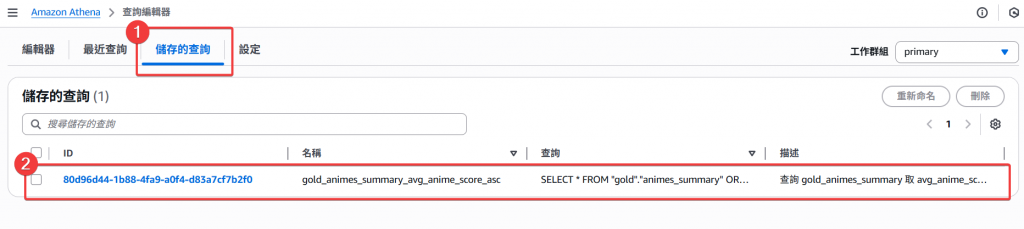
Step16:我們可以至「儲存的查詢」頁籤頁面,找到剛剛儲存的查詢,再選擇該筆查詢後,會直接跳轉到查詢頁面,將常用的查詢做儲存,可以非常便於下次的使用。
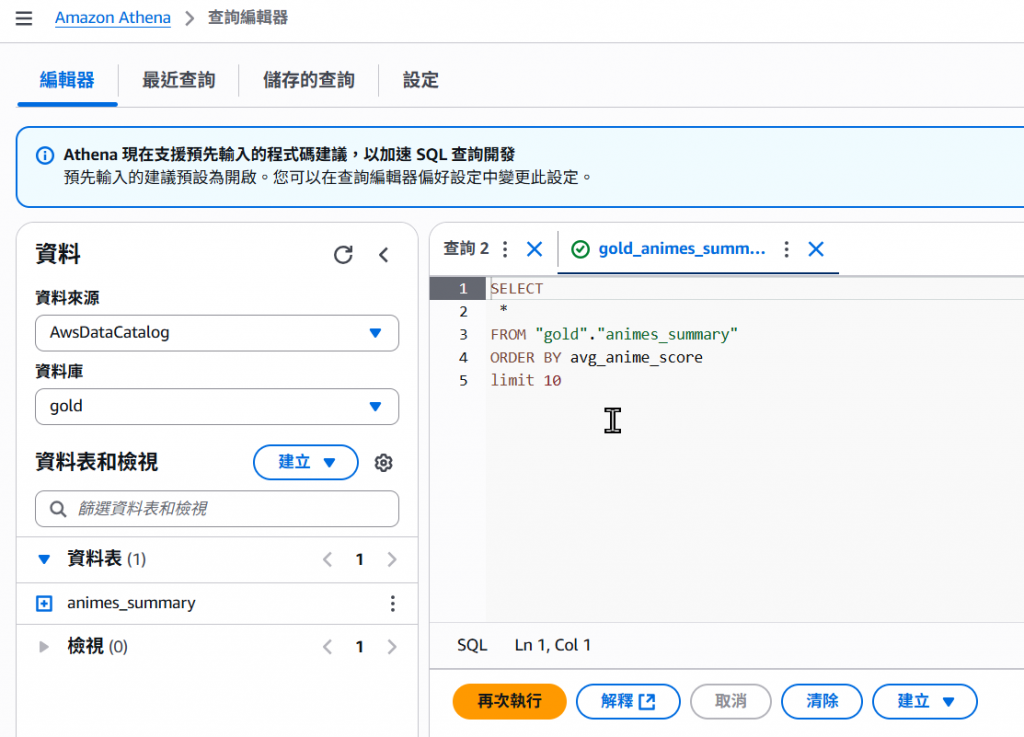
以上即完成 Athena 的查詢應用步驟,想必熟悉 SQL 的你,看到 Athena 這個服務會有別於前面的其他服務,感到特別的親切吧?
透過本篇的實作,我們可以清楚看到 Athena 在 Data Lakehouse 架構中的角色:
低門檻與即用即查
與 Glue Data Catalog 緊密整合
最佳實踐建議
💡 總結來說,Athena 是一個 驗證、探索與輕量分析的利器,讓我們能快速檢視數據處理成果,並成為後續 BI 報表與數據應用的基石。
在完成資料查詢與驗證後,下篇我們回到 「Day20 淬鍊之章-多檔案上傳 ETL 流程-設計篇」 來將 Day18 說的使用場景重新思考,並簡易的說明什麼場景適合用什麼服務來設計 Data Pipeline。


 iThome鐵人賽
iThome鐵人賽