從 995 題中 random 挑了 50 題出來組成 dataset。
這是 ToolHop 的 distribution,在設定一堆東西後跑了一下:
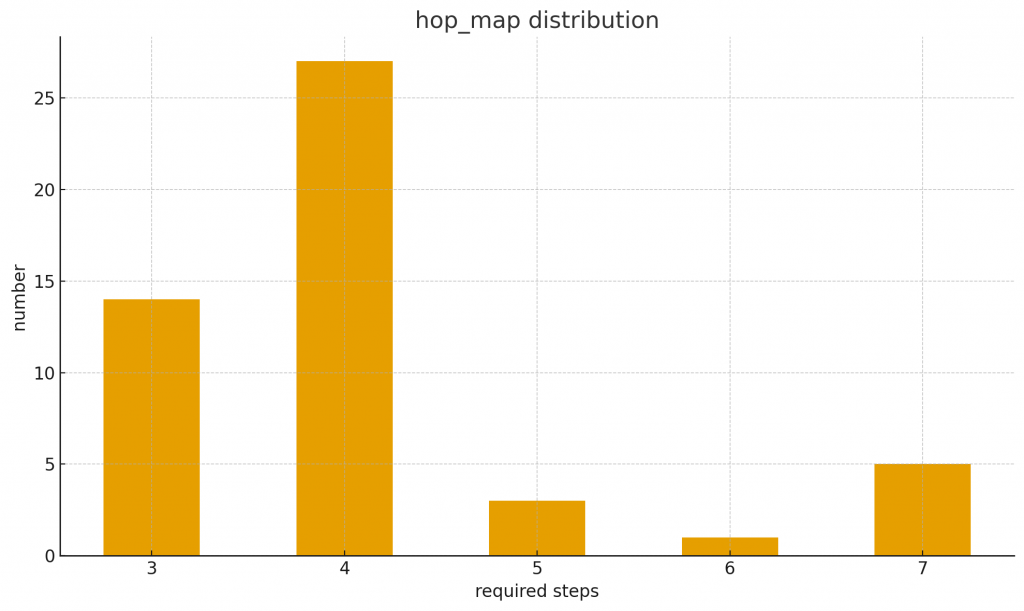
橫軸是解題所需的最少 step(可以看到是多輪的 tool-using task),縱軸則是題數分布。
FC= native support for function/tool calling.Prompt= walk-around for function calling, using model's normal text generation capability.
今天就拿最 naive 的 ReAct 架構來跑跑看吧。
主要比較不同模型、不同呼叫策略(Function Calling vs Prompt )在各種 step requirement 下的平均表現。
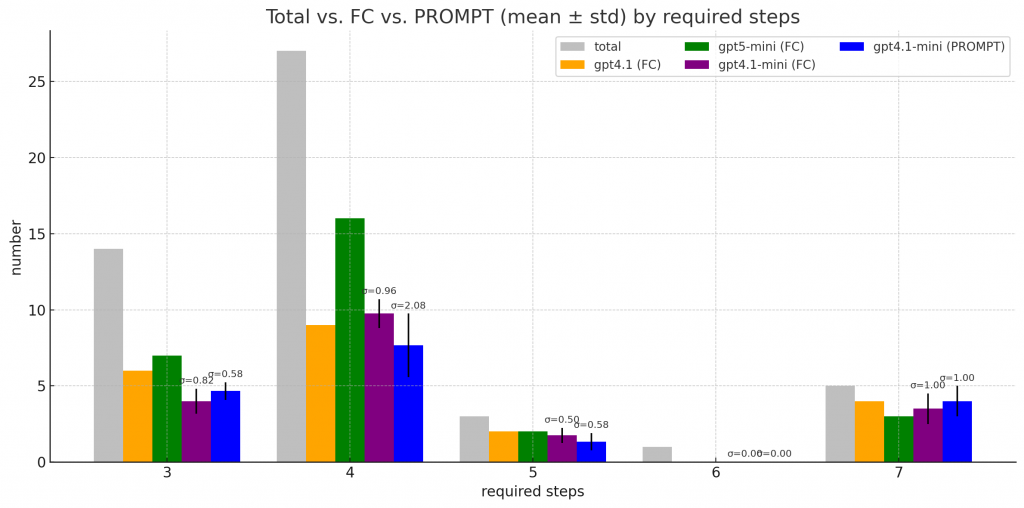
長條圖中有標準差的就代表我實際跑了多次。
可以看到:
題外話
實驗有點小小的瑕疵
FC 模式中,在 reasoning 這步至少有乖乖的產出 (name:, args:),但是實際產出來的參數 還是有瑕疵 e.g., 出現根本不存在的變數,然後到 action state 時就炸裂了 -> 這時候我會讓他回 reasoning state 重新產一次 -> 有機會修正
但 PROMPT 模式,有時候在 reasoning 這步連 (name:, args:) 都會生壞 -> 我就直接讓他去 answer state 了 -> 直接錯了
不過用 FC 的情況下,tool 參數設定錯誤的情況確實比 PROMPT 還低
但整體來看,FC(native function calling) ,效果應該還是比較好一點 (?)
少了 prompt template 的 parsing overhead,也避免了 model 猜測 tool 格式造成的 hallucination。
今天這樣跑了一輪,大概花了 2.5 美元。
這邊簡單比較一下花費:
欸 gpt5-mini 我只有跑一次欸,那個 output token 也太貴了吧! (當作是請 openai 吃月餅)
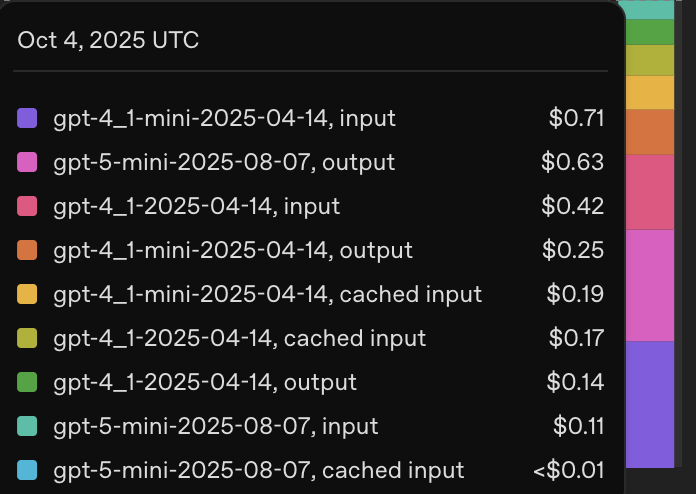
之後應該都用 4.1-mini 跑吧,也省錢
雖然用 5-mini 很貴,但至少我們看到了 4.1-mini 還有一大段的進步空間(不是題目根本就不可能答對)
應該就可以從 net or memory architecture 下手,來提升 4.1-mini 的成績

