
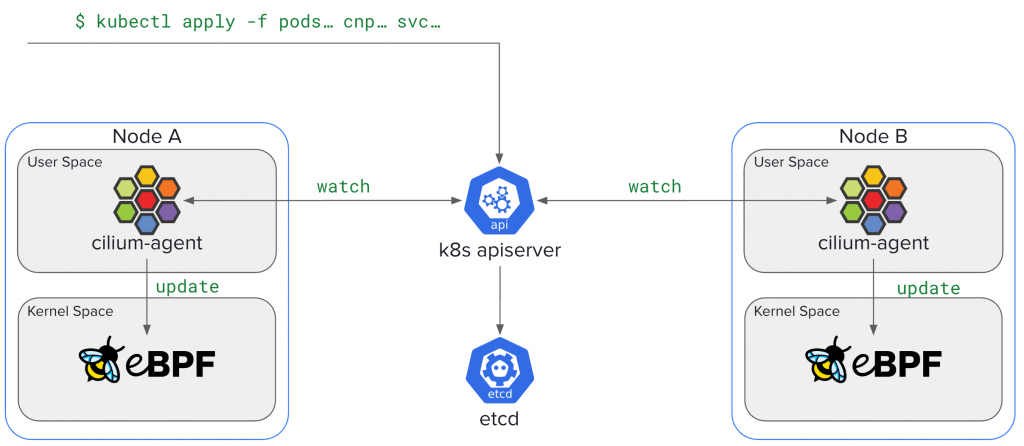
在昨天的文章中,我們透過 Pod-to-Service datapath 的流程,親眼看到 Cilium 是怎麼在 Socket connect() 執行 BPF Program、查詢 BPF Maps,最後完成 Service 負載平衡的。
加上我們本次系列文也討論的 Scope 也從單一 Node 跨足到多個 Node 的行為,深刻了解到封包是怎麼流動的,Network Policy 是在何時決策的,不過我不知道讀者是否會有一個疑問可能會浮現在腦海裡:
👉 這些 BPF Maps 不是 node-local 的嗎?
那 Node A 的 cilium-agent 怎麼會知道 Node B 上某個 Pod 的 IP 與 Security Identity 的對應關係?
再進一步想,如果我們套用一條基於 Label 的 CiliumNetworkPolicy,為什麼它能在整個 cluster 的每個節點都「同步生效」?
Cilium 的祕密不在 datapath,而是在 控制平面 (control-plane) — 它如何把 Kubernetes 的狀態(Pod、Service、Policy、Node 資訊),分發並轉譯到每個節點的 BPF Maps,讓整個 cluster 保持 最終一致性 (eventual consistency)。
今天,我們就要來解開 Cilium 背後的同步機制!
Cilium 的 datapath 完全依賴 eBPF 程式 + BPF Maps。但有個限制:
這意味著,每個 node 只知道自己 local 的資訊,天生沒有辦法直接得知「其他 node 上的 Pod、Service、Policy」狀態
但 Kubernetes 的設計卻是 cluster-wide 全域狀態:
換句話說,沒有控制平面,datapath 根本玩不下去
如果我上面這樣講還是沒有感覺的話,那我列舉幾個情境,實際感受一下「各 Cilium Agents 沒有同步狀態」會怎樣:
當你在 K8s Cluster 中創建兩個 Pod,並且套用了 Network Policy 給 Pod A,現在 Pod A → Pod B
Identity 模型要能正常運作,其核心前提是:對於任意一個給定的 Labels 組合,其對應的數字 Identiy 在整個 Cluster 中必須是絕對一致的。如果 Node A 將 app=backend, tier=db 的 Labels 組合分配給 Identity 1001,而 Node B 卻將其分配給 1002,那麼一條旨在允許 app=frontend 訪問 app=backend 的 Policy 將會徹底失效。Node A 上的 frontend Pod 發出的封包,其 egress Policy 會允許流向 Identity 1001,但當封包到達 Node B 時,Node B 的 ingress Policy 會認為目標 Pod 的 Identity 是 1002,從而可能導致連線被錯誤地拒絕。
當一個位於 Node A 的 Pod 試圖與位於 Node B 的 Pod 通訊時,Node A 上的 cilium-agent 必須能夠根據 Node B 上目標 Pod 的 IP 位址,查詢到其對應的 Identity ,以便正確地執行 egress Policy 。反之,當封包到達 Node B 時,Node B 的 cilium-agent 也需要知道來源 IP 位址對應的 Identity ,以執行 ingress Policy 。因此, Cluster 中每一個 Pod 的 IP 位址到其安全 Identity 的對應關係,都必須被傳播到所有其他節點。
我們可以直接用昨天 (Day 20) 的情境來觀察,當我們在 K8s Cluster 創建了 Service,以及對應的 Backend Pods,接著進去任一個 Cilium Agent 內查看 Service Map:
# worker-1 cilium-agent 視角
root@worker-1:/home/cilium# cilium-dbg service list | grep -A1 "10.104.210.239"
18 10.104.210.239:80/TCP ClusterIP 1 => 10.244.1.234:80/TCP (active)
2 => 10.244.2.60:80/TCP (active)
# worker-2 cilium-agent 視角
root@ip-10-13-1-129:/home/cilium# cilium-dbg service list | grep -A1 "10.104.210.239"
18 10.104.210.239:80/TCP ClusterIP 1 => 10.244.1.234:80/TCP (active)
2 => 10.244.2.60:80/TCP (active)
你注意到了嗎?無論是在哪個 Cilium Agent,他們的 service BPF Map 裡面儲存的 Entries 是一模一樣的,這是非常重要的!!想像今天我們又創建新的 Pod,該 Pod 會被調度到某一節點上,例如在 worker-3,接著該 Pod 對 NGINX Service 發出請求,從我們昨天 (Day 20) 的文章已經知道:「決策會送到 Service 背後的哪個 Backend Pod 是在 application 調用 connect() 就決定了」,換句話說,決策過程完全是在 worker-3 上完成,假如當初的 Service 資料沒有同步到這個節點上的 BPF Map,那該 Pod 就會找不到 Service 的 Backend Pods IP,最後導致請求無法成功送到 Backend Pods
讀者們可以試著想想看,如果是你會如何同步狀態?
試想現在有 3 個 Node,有一些資訊你要確保這 3 台 Node 都要知道,並且資訊都要一致不可以 Node A 和 Node B 得到的資訊不一致。
我自己在思考「如何實現同步資訊」,其實我腦海第一個浮現的是 BGP (Border Gateway Protocol) 的概念,等於要建立出一個鄰居網路,但是我想了想又覺得不可能,因為 Cluster 規模一大起來,當我要更新資訊,豈不是等傳播到整個 Cluster 的時間會變很長!換句話說集群越大收斂速度會越慢
另一種我想到的是 Pub/Sub 的概念, 所有 cilium-agent 都是 subscriber,而 cilium-agent、 cilium-operator、k8s apiserver 是 publisher,etcd 是儲存事件的地方,所以今天有任何事件發生,publisher 就是發布事件到 etcd,而 subscribers 接收到事件之後就更新狀態!這個模型看起來可行
Cilium 的同步機制核心概念就是:
👉 所有 agent 不直接互傳,而是透過一個「集中式狀態存放區」(K8s API Server 或外部 kvstore)去 watch 與更新,確保整個 cluster 最終一致。
有一點類似 Pub/Sub 的模型,但是仍有稍微不同,Pub/Sub 系統通常有「訊息歷史 / queue」概念(晚來的 subscriber 還能補讀消息),但是 Cilium 用的 API Server / etcd 其實是 狀態存放區 (state store),不是事件 queue,所以要更精確來說,我會說這是一個 「集中式 State Store + 分散式 reconciliation」
現在我來實際翻翻官方文件,Cilium 提供以下主要模式來同步這些狀態:
為了實際感受同步的流程,這裡我們追蹤一個新 Pod 從建立到其網路狀態在整個 Cluster 生效的完整生命週期:
事件觸發(Pod 建立):Kubernetes scheduler 將一個新的 Pod 調度到某個節點上。該節點上的 kubelet 隨即調用 container runtime 接著 runtime 調用 CNI plugin 來為這個 Pod 設定
與本地 Agent 互動:Cilium 的 cilium-cn) 會透過本地 API 與執行在同一節點上的 cilium-agent 進行通訊。
cilium-agent 此時執行初始的本地設定工作,包括:
狀態發佈:完成本地設定後,cilium-agent 會讀取該 Pod 的 Labels ,並將其存在「廣播」給 Cluster 中的其他成員。這個「廣播」是透過向中央狀態儲存庫寫入資訊來實現的。具體來說,agent 會建立一個 CiliumEndpoint 資源或一個對應的 key-value 對(在 kvstore 模式下),並確保該 Pod Labels 組合對應的 CiliumIdentity 已經存在(如果不存在則先建立)
狀態消費與協調:這裡是最關鍵的一步。剛剛發佈了這個新 Pod 狀態的 cilium-agent,它自己同時也是一個狀態的消費者。它和其他所有節點上的 cilium-agent 一樣,都在 watch 著中央儲存庫的變化。因此,它(以及 Cluster 中所有其他的 agent)都會收到關於這個新的 CiliumEndpoint 和 CiliumIdentity 的更新通知
BPF Map 更新:一旦收到這個更新,每個 cilium-agent 內部的 controller 就會開始工作。它會將接收到的抽象資訊(如 IP、Identity、Policy 規則)轉譯為 BPF datapath 能夠直接使用的格式,並更新至本地的 BPF maps
cilium_ipcache map 中加一條 entry,將新 Pod 的 IP 映射到其 Identity。同時,它會重新計算並更新 Policy 相關的 BPF maps (也就是 Regeneration,如果忘記 Regeneration 是什麼的話可以複習 Day 10 的文章),以反映適用於這個新 Identity 的所有 Network Policy 規則。只有當這個最終步驟完成後,全域的狀態變更才真正在該節點的 datapath 上生效。讀者們不知道是否也有跟我同樣的疑惑,如果我正在遭受攻擊,所以打算用 NetworkPolicy 來阻擋惡意流量,以此保護我的 Pod,當 NetworkPolicy 創建下去了,但是還沒有即時同步到各 Cilium Agent,那豈不是會導致「惡意流量」仍可以進去尚未成功同步的 Cilium Agent? 也就是說會有某個瞬間「部分 Allow 部分 Drop」
沒錯,從我們分析的同步流程來說,「部分 Allow 部分 Drop」的情境確實可能發生,因為 Cilium 沒有保證「即時一致」,而是 eventual consistency。這中間會有「收斂時間 (convergence time)」,在這段時間 cluster 狀態是暫時不一致的
以上面的情境來說,真的要解決,我只能建議把 Policy Enforcement Modes 改成 always ,這樣做可以確保:
若忘記 Policy Enforcement Modes 是什麼,可以回顧 [Day 16] Cilium Network Policy 與 Identity-based 入門
至於為什麼做不到「即時一致」,我想這裡就該拿出 CAP 定理 來說明:
👉 在有分區的情況下,不可能同時拿到強一致 + 高可用
硬是要做即時一致可能會讓傳播的 Latency 更高,我認為現在這種模式已經是最棒的設計,因此請妥妥地接受 Cilium 的設計:接受短暫失敗,換取可擴展性。
接著來想一個情境,你的 Cluser 裡面有很多 Nodes,結果 Node A 的機房突然停電了,重點是你有一個 NGINX Service 的 Backend Pod 住在 Node A 上,那完蛋了,別的 Pod 如果剛好要打 NGINX Service 又很剛好選中 Node A 上的 Backend Pod,就會進入黑洞…
👉 這裡你該知道的一個關鍵是「沒有人知道 Node A 死掉了,Node A 的資訊也無法同步出去,所以其他節點上的 Service BPF Map 裡面還有 Backend Pod IP 」,所以產生了 stale state
在 CRD Mode 其實蠻好解決的,因為 Cilium 是透過 **Kubernetes API Server → etcd,**狀態儲存的地方是 CRDs (CiliumEndpoint, CiliumIdentity),這些物件是 Kubernetes 原生物件,在 Node 突然死掉的狀況下 Node 上的 kubelet 停止心跳 → API server 判斷 Node NotReady,後續 Node Controller 會幫你驅逐 Pod,自然而然 stale state 就會被清除
但是在 kvstore mode,就會需要一個東西叫做 Lease
👉 Lease = 一種「帶有效期的承諾」,要解決的問題就是:避免「死掉的 agent」留下垃圾狀態,誤導其他節點
我用以下比喻讓你實際感受一下 Lease:
cilium-agent@node1 跟 etcd 說:
「幫我保留這些資料,但只要我每隔幾分鐘沒有來報到,就當我死掉,把我的資料刪掉。」
etcd 就像一個房東,會檢查:
所以:
👉 這樣可以保證 整個 cluster 不會因為某個 node 掛掉而殭屍化
實際上會還有其他資訊 Cilium 需要同步,詳細內容可以看這份官方文件,我將裡面的內容整理起來如下:
其實 Cilium 在 Kubernetes 環境裡面,最大的巧思就是它怎麼用 node-local 的 eBPF datapath 來跑全域的網路 Policy 。乍聽之下很矛盾,但它是靠一個 分層的控制平面 去解決,所有 Global 宣告式的狀態(像是 Pod identity、Service Backend Pod、Policy)最後都會透過 sync loop 被轉譯成 本地 BPF map 規則,讓每個 Node 的 datapath 都能一致行為。
幾個我覺得最關鍵的 takeaway:
共享狀態是根本
不管是 Security Identity、Endpoint mapping、Service backend 還是 Node info,都要確保全 Cluster 一致。這些東西就是 Cilium 高階功能能不能 work 的基石。
Control plane 架構決定效能
Eventual Consistency 特性
Cilium 沒有保證強一致性(strong consistency),而是走 eventual consistency。意思是狀態從寫進 central store,到真正下放到所有 Node datapath 中間會有一個 convergence window。在這段時間內,流量的判斷可能會有差異。這是設計取捨,換來的是更好的 scalability 和 resilience。
最後我自己的理解是:要在生產環境好好跑 Cilium,除了知道 eBPF 本身的威力,更要懂背後的狀態管理哲學。你要選對適合自己 cluster 規模的控制平面架構,監控和除錯要能接受 eventual consistency 的特性,並且 Troubleshooting 時知道這些特性會帶來哪些 Error。

 iThome鐵人賽
iThome鐵人賽