text-embedding-3-small 和 text-embedding-ada-002) 在我們資料集上的表現SemanticSimilarityEvaluator
evaluator 的效果,所以這次的實驗本質上是 Evaluating Evaluator
# small-3 result:
{'precision': 0.9032258064516129, 'recall': 0.9655172413793104}
# ada result:
{'precision': 0.9333333333333333, 'recall': 0.9655172413793104}
ada-002 的 precision 還略高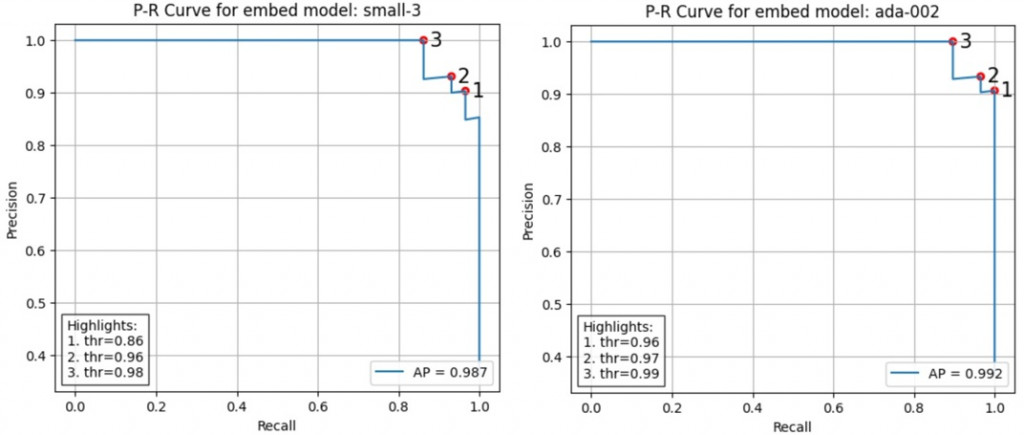
我們接下來就來看看這是怎麼做的吧
python semantic_similarity.py
SemanticSimilarityEvaluator 不熟悉,可以參考我們在 day19 的介紹qid 來獲取每筆資料的內容ispass,指出 reference_answer 與 response 是否 match
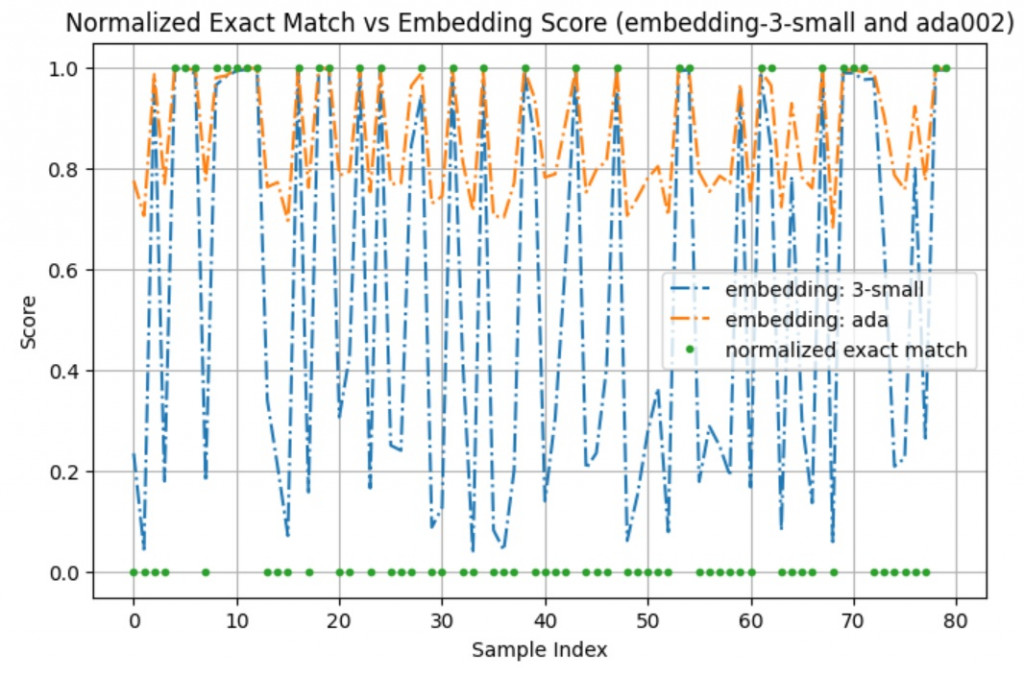
reference_answer 與 llm_prediction 的 similarity score
text-embedding-ada-002 跑出來的結果text-embedding-3-small 跑出來的結果這邊我們試用看看 huggingface 的 evaluate
import evaluate # pip install evaluate
def _get_binary_prediction(pred, thr):
return [0.0 if p <= thr else 1. for p in pred]
def _get_precision_recall(pred, label):
precision_metric = evaluate.load("precision")
recall_metric = evaluate.load("recall")
combined = evaluate.combine([precision_metric, recall_metric])
results = combined.compute(predictions=pred, references=label)
return results # dict
def get_precision_recall(pred, label, thr):
binary_pred = _get_binary_prediction(pred, thr)
result = _get_precision_recall(binary_pred, label)
return result # dict
在 threshold = 0.8557835443653601 下:
# small-3 result:
{'precision': 0.9032258064516129, 'recall': 0.9655172413793104}
# ada result:
{'precision': 0.7631578947368421, 'recall': 1.0}
在 threshold = 0.9676289405210952
# small-3 result:
{'precision': 0.9285714285714286, 'recall': 0.896551724137931}
# ada result:
{'precision': 0.9333333333333333, 'recall': 0.9655172413793104}
這邊其實呼應了我們前面的觀測,ada002 的 similarity score 在我們的任務上看起來分布比較窄
所以其實像這種只有 similarity score 的任務,我們需要給每個 model 不同的 threshold
那問題就來了,這邊的這兩個 threshold 是怎麼得到的?
我們可以基於 PR-Curve 來選擇
我們這邊直接基於 sklearn 的 precision_recall_curve 來得到 precision, recall 與 threshold
此外我們順勢把 ap 也算出來, ap 表示的就是 precision_recall_curve 的曲線下面積
import numpy as np
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
precisions, recalls, thresholds = precision_recall_curve(labels, ada_scores)
print(type(precisions), precisions.shape, type(recalls), recalls.shape, type(thresholds), thresholds.shape)
ap = average_precision_score(labels, ada_scores)
highlight
def get_f1_score(precisions, recalls):
# from precision and recall
f1_scores = np.where(
(precisions + recalls) > 0,
2 * precisions * recalls / (precisions + recalls),
0.0,
)
return f1_scores
def get_topk_highlight(precisions, recalls, k=3):
f1_scores = get_f1_score(precisions, recalls)
topk_idx = np.argsort(-f1_scores)[:k]
highlights = []
for idx in topk_idx:
thr = None if idx == 0 else thresholds[idx - 1]
highlights.append({
"f1": float(f1_scores[idx]),
"precision": float(precisions[idx]),
"recall": float(recalls[idx]),
"threshold": None if thr is None else float(thr),
"idx": int(idx),
})
return highlights
[{'f1': 0.9508196721311475,
'precision': 0.90625,
'recall': 1.0,
'threshold': 0.9642988120688676,
'idx': 48},
{'f1': 0.9491525423728815,
'precision': 0.9333333333333333,
'recall': 0.9655172413793104,
'threshold': 0.9676289405210952,
'idx': 50},
{'f1': 0.9454545454545454,
'precision': 1.0,
'recall': 0.896551724137931,
'threshold': 0.9899387683709545,
'idx': 54}]
```
import matplotlib.pyplot as plt
from matplotlib.offsetbox import AnchoredText
plt.figure(figsize=(6, 5))
plt.plot(recalls, precisions, label=f"AP = {ap:.3f}")
# highlight 點只標號碼
for i, h in enumerate(highlights, 1):
plt.scatter(h["recall"], h["precision"],
s=20, facecolors="none", edgecolors="red", linewidths=2)
plt.text(h["recall"], h["precision"], f" {i}",
fontsize=15, ha="center", va="center", color="black")
# thresholds 說明,放左下角
thr_lines = [f"{i}. thr={h['threshold']:.2f}" for i, h in enumerate(highlights, 1)]
txt = "Highlights:\n" + "\n".join(thr_lines)
at = AnchoredText(txt, prop=dict(size=10), frameon=True, loc="lower left")
at.patch.set_alpha(0.8)
plt.gca().add_artist(at)
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.title(f"P-R Curve for embed model: {model_base_name}")
plt.legend(loc="lower right", framealpha=0.9) # 這裡只放 AP
plt.grid(True)
plt.show()
```
我們今天的首要目標是驗證兩個 embedding model (text-embedding-3-small、ada-002) 作為 evaluator 的表現
數值上來說最好的結果是:
{'precision': 0.9333333333333333, 'recall': 0.9655172413793104}
這刷新了兩層我們的認知:
在這中間我們遇到了 threshold 要怎麼選的問題
我們實際比較了 新版本的 embedding-small-3 與 舊版的 ada-002
ada-002 似乎是比較差的結果今天介紹的方法最大的缺點在於: 一定要先有 ground-truth 這些計算才能成立


 iThome鐵人賽
iThome鐵人賽