我們今天要來實作 RAG baseline,當然,用的是 llama-index 的 workflow
如果你對 llama-index 的 workflow 不熟悉,可以:
這是我們的 RAG baseline workflow 的長相: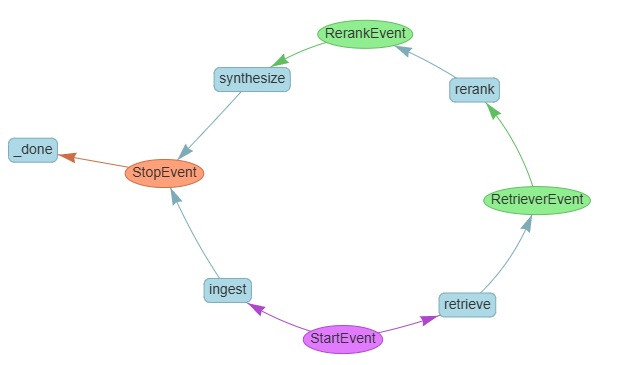
圓圈是 event,放的是資料;方塊是 step,放的是處理步驟
整體來說就兩條路徑:
那我們就來看一下這個是怎麼做出來的吧
我們的 steps 包含:
ingest step: 用來建立本地文檔的 index
FaissVectorStore 來完成retrieve step: 用來檢索文檔
VectorStoreIndex.as_retriever,它會幫我們處理 embedding 還有算 similarity 回傳 top_k 給我們rerank step: 用來重排檢索到的文檔
LLMRerank
synthesize step: 用來合成最後的回答
CompactAndRefine
StartEvent
RetrieverEvent
nodes 屬性,就是帶 Score 的文本塊RerankEvent
nodes 屬性,就是帶 Score 的文本塊StopEvent
首先是建 index 然後存出去,這邊有三個角色:
FaissVectorStore
StorageContext
VectorStoreIndex
documents = SimpleDirectoryReader(document_dir).load_data()
d = 1536
faiss_index = faiss.IndexFlatL2(d)
vector_store = FaissVectorStore(faiss_index=faiss_index)
storage_context = StorageContext.from_defaults(
vector_store=vector_store
)
index = VectorStoreIndex.from_documents(
documents=documents,
embed_model=OpenAIEmbedding(model_name="text-embedding-3-small"),
storage_context=storage_context,
)
index.storage_context.persist(persist_dir=index_dir)
print("Index built and persisted to:", index_dir)
這邊可以與官方的最小可行範例做對比
documents = SimpleDirectoryReader(dirname).load_data()
index = VectorStoreIndex.from_documents(
documents=documents,
embed_model=OpenAIEmbedding(model_name="text-embedding-3-small"),
)
vector_store = FaissVectorStore.from_persist_dir(index_dir)
storage_context = StorageContext.from_defaults(
vector_store=vector_store, persist_dir=index_dir
)
index = load_index_from_storage(storage_context=storage_context)
這邊要看兩個:
retriever,並且 retrievequery = ev.get("query")
index = ev.get("index")
if not query:
return None
print(f"Query the database with: {query}")
retriever = index.as_retriever(similarity_top_k=SIM_TOP_K)
nodes = await retriever.aretrieve(query)
print(f"Retrieved {len(nodes)} nodes.")
choice_batch_size
top_n 用來選擇重排後要回傳多少個 noderanker = LLMRerank(
choice_batch_size=5, top_n=3, llm=OpenAI(model="gpt-4o-mini")
)
new_nodes = ranker.postprocess_nodes(
ev.nodes, query_str=await ctx.store.get("query", default=None)
)
print(f"Reranked nodes to {len(new_nodes)}")
return RerankEvent(nodes=new_nodes)
針對 rerank 我們有進行一個小測試,完整的記錄在: 這裡
query=什麼是深度學習的醍醐味?
8 個 node8 個 node 被排到了第 1 位top 8,而是常見的 top 5 rerank 將沒有用武之地此外關於 rerank 的預設 prompt,可以在這裡 的 deep dive 找到 DEFAULT_CHOICE_SELECT_PROMPT_TMPL
llm = OpenAI(model="gpt-4o-mini")
summarizer = CompactAndRefine(llm=llm, streaming=False, verbose=True)
refine: 一個 node 我就呼叫一次 llm ,第二次以後的呼叫,llm的input 包含了原始問題、上一次的回答、新的 node,llm可以選擇要不要修改compact: 本質上跟 refine 是同一件事,但 refine 有多少 node 就會呼叫多少次 llm ,而 compact 則是會盡可能的合併 node,可以說 compact 就是 更少次 llm 呼叫的 refinetree_summarize,回傳的 node 會先被切塊,然後每一塊都被進行 summary,之後遞迴的 summary 所有的 summary 直到只剩下一個 node,這在總結大篇文章的時候很有用accumulate: 先針對每一個 node 進行一次回答,然後最後拼接回傳所有的回答import asyncio
async def main():
# w = RAGWorkflow(); index = await w.run(index_dir=INDEX_DIR) ...
...
if __name__ == "__main__":
asyncio.run(main())
indexing 的步驟,介紹了


 iThome鐵人賽
iThome鐵人賽