
在 昨天 Day 22,我們透過 LangGraph 讓 Agent 的推理過程可視化,
清楚看見模型如何思考、呼叫工具、以及如何逐步決策。
然而,雖然我們能追蹤 Agent 的「思考」,它卻仍不會記取教訓。
每次任務結束後,Agent 都像重新開始——沒有反思,也沒有學習。
其實在 基礎篇 Day 9,
我們曾介紹過「Reflection」的核心概念:
讓模型透過「自我檢討」與「改進原則歸納」來優化未來行為。
但當時的實作仍停留在單回合層級,沒有記憶,也無法真正累積經驗。
若要讓 Agent 真正具備「成長」能力,我們需要兩個關鍵元素:
今天,我們要讓 Agent 不只是完成任務,而是「從經驗中學習」——
透過 LangChain v1.0 的新架構,結合 Reflection × Memory,
打造能思考、能反省、也能持續成長的智慧助理。
ReAct 與 Planning 型 Agent 雖能根據情境做出即時判斷,但它們沒有長期記憶。
每次互動都從零開始,缺乏累積與改善能力。
這會導致以下問題:
| 問題 | 原因 | 改進策略 |
|---|---|---|
| 每次任務都重新推理 | 缺乏狀態保存 | 建立短期記憶保存上下文 |
| 回覆缺乏一致性 | 沒有反思階段 | 加入反思節點,歸納改進準則 |
| 無法根據經驗優化決策 | 任務無學習機制 | 將反思摘要轉為可重用記憶 |

圖:Agent 在執行任務後,先推理與行動,再透過反思提煉改進準則並更新記憶。這個循環讓模型能在不斷任務中持續自我優化,逐步累積可重用的經驗知識。
LangChain v1.0 引入全新的 記憶機制(Memory System):
記憶不再是外部物件,而是整合於 Agent 狀態(State)。
透過 checkpointer,Agent 可在對話線程(thread)中保存上下文,
並持續學習、改善自己的策略。
新版的記憶系統由三個核心元件組成:
| 元件 | 功能 |
|---|---|
| AgentState | 管理狀態與訊息,取代傳統的記憶物件 |
| checkpointer | 控制記憶儲存方式(如 InMemorySaver 或資料庫) |
| thread_id | 用於識別對話線程,保留上下文連續性 |
這使得 Agent 不僅能完成任務,還能隨著每次互動「學習與改進」。
我們延續前篇的維也納旅遊規劃案例,這次要讓助理具備「反思與記憶」功能。
整個流程如下:

圖:Reflection × Memory 流程示意。Agent 先依使用者請求規劃行程,接著查詢天氣並分析影響,再進行反思以提煉決策準則,將結果整理為短期記憶摘要,最後依據記憶重新輸出改良行程。整個過程讓模型能在任務中逐步學習與優化決策邏輯。
import asyncio
import os
from langchain.chat_models import init_chat_model
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver
from langchain_mcp_adapters.client import MultiServerMCPClient
from langgraph.graph import StateGraph, END
# 共享狀態
class TripState(dict):
plan: str | None = None
weather: str | None = None
reflection: str | None = None
memory_summary: str | None = None
output: str | None = None
# 初始化 MCP 工具
async def init_tools():
accuweather_api_key = os.getenv("ACCUWEATHER_API_KEY")
if not accuweather_api_key:
raise ValueError("請設定 ACCUWEATHER_API_KEY 環境變數")
client = MultiServerMCPClient(
{
"accuweather": {
"transport": "stdio",
"command": "uv",
"args": [
"--directory",
"{MCP 程式路徑}",
"run",
"weather_mcp_server.py"
],
"env": {"ACCUWEATHER_API_KEY": accuweather_api_key}
},
"attractions": {
"transport": "stdio",
"command": "uv",
"args": [
"--directory",
"{MCP 程式路徑}",
"run",
"attractions_mcp_server.py"
]
}
}
)
tools = await client.get_tools()
return tools
# 建立 Agent(啟用短期記憶)
async def build_agent(tools):
llm = init_chat_model("gemini-2.5-flash", model_provider="google_genai")
checkpointer = InMemorySaver()
return create_agent(
model=llm,
tools=tools,
checkpointer=checkpointer,
system_prompt=(
"你是一位智慧旅遊助理。可透過 MCP 工具查天氣、查景點、檢查營業時段,"
"並能根據反思結果更新決策。回覆時請先思考所需資訊,再選擇適當工具與參數。"
)
)
# 主程式:LangGraph 串接各節點
async def main():
tools = await init_tools()
agent = await build_agent(tools)
# 規劃行程
async def step_plan(state: TripState):
print("[PLAN] 規劃初步行程")
res = await agent.ainvoke({
"messages": [{
"role": "user",
"content": "請規劃維也納一日行程(上午、下午、晚上),並在需要時自行查詢景點。"
}]
}, {"configurable": {"thread_id": "1"}})
state["plan"] = res["messages"][-1].content
return state
# 查天氣
async def step_weather(state: TripState):
print("[WEATHER] 查天氣並檢視影響")
res = await agent.ainvoke({
"messages": [{
"role": "user",
"content": f"以下是目前行程:\n{state['plan']}\n"
"請查維也納今天天氣,並分析是否需要調整行程。"
}]
}, {"configurable": {"thread_id": "1"}})
state["weather"] = res["messages"][-1].content
return state
# 反思
async def step_reflect(state: TripState):
print("[REFLECT] 檢討並提出改進準則")
res = await agent.ainvoke({
"messages": [{
"role": "user",
"content": (
"請基於行程與天氣、營業時段等可得資訊,指出不合理之處並提出改進準則。"
"輸出請包含:問題點、原因、改進原則三項。"
)
}]
}, {"configurable": {"thread_id": "1"}})
state["reflection"] = res["messages"][-1].content
print("[REFLECT] 結果:")
print(state["reflection"])
return state
# 記憶摘要
async def step_memory_update(state: TripState):
print("[MEMORY] 將反思摘要為記憶")
res = await agent.ainvoke({
"messages": [{
"role": "user",
"content": f"請將以下反思整理成可重用的決策準則摘要:\n{state['reflection']}"
}]
}, {"configurable": {"thread_id": "1"}})
state["memory_summary"] = res["messages"][-1].content
print("[MEMORY] 摘要:")
print(state["memory_summary"])
return state
# 重新生成行程
async def summarize(state: TripState):
print("[SUMMARY] 基於記憶輸出改良行程")
res = await agent.ainvoke({
"messages": [{
"role": "user",
"content": (
"請基於本次的決策準則摘要,重新輸出更合適的維也納一日行程。"
"若需要,請自行再次查詢景點或營業時段。"
)
}]
}, {"configurable": {"thread_id": "1"}})
state["output"] = res["messages"][-1].content
print("[SUMMARY] 最終輸出:")
print(state["output"])
return state
# LangGraph 流程設定
graph = StateGraph(TripState)
graph.add_node("plan", step_plan)
graph.add_node("weather", step_weather)
graph.add_node("reflect", step_reflect)
graph.add_node("memory", step_memory_update)
graph.add_node("summary", summarize)
graph.set_entry_point("plan")
graph.add_edge("plan", "weather")
graph.add_edge("weather", "reflect")
graph.add_edge("reflect", "memory")
graph.add_edge("memory", "summary")
graph.add_edge("summary", END)
app = graph.compile()
result = await app.ainvoke(TripState())
print("\n========== 最終結果 ==========")
for step, content in result.items():
print(f"[{step}]:{content}")
if __name__ == "__main__":
asyncio.run(main())

圖:模型根據使用者需求生成維也納一日行程,初步安排皇宮、美景宮與美泉宮等主要景點。此階段著重於推理與規劃能力,尚未考量天氣與外部條件,作為後續修正的基礎方案。
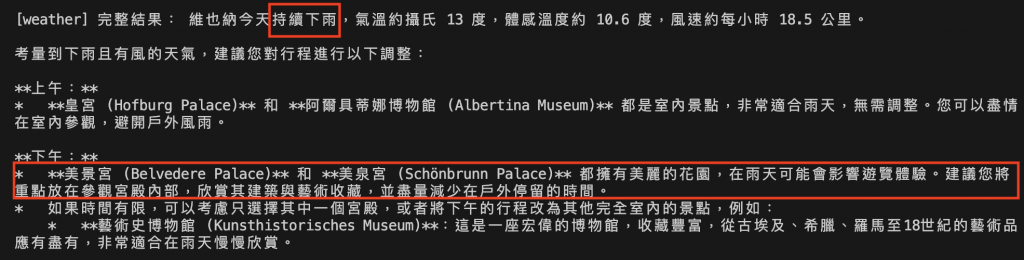
圖:Agent 透過 Weather MCP 取得天氣資料(持續下雨、低溫有風),並自動評估行程受氣候影響的程度。模型建議將戶外景點改為室內參觀,展現 ReAct 策略下的環境感知與即時判斷能力。

圖:模型檢討前一階段的行程與天氣條件,歸納出三項主要問題:時間過於緊湊、天氣造成體驗下降、景點距離過遠。接著提出改進準則,例如「惡劣天氣下應優先選擇室內活動」,展現初步的自我修正思考能力。

圖:模型將反思結果轉化為可重用的決策規則,例如「雨天時應將戶外行程調整為室內參觀,並重新排序景點」。這些內容被保存為短期記憶摘要,使後續任務能引用過往經驗,不再重複犯錯。

圖:Agent 應用先前生成的記憶摘要,重新輸出「雨天室內精華版行程」。新行程避開戶外活動、整合天氣與開放時間資訊,內容更具彈性與一致性,象徵 Agent 完成從推理到學習的進化。
模型依序執行五個階段——
這五步驟展現了 Agent 從「推理 → 反思 → 記憶 → 改進」的完整學習循環,
不再只是執行任務,而能真正從經驗中成長。
回顧最近幾天的進化路徑:
| 節點 | 能力 | 技術核心 |
|---|---|---|
| Day 20 | 使用多工具完成任務 | ReAct 策略 |
| Day 21 | 多步規劃與動態反應 | Planning × ReAct |
| Day 22 | 可視化決策過程 | LangGraph |
| Day 23 | 反思與記憶 | Reflection × Memory |
這正是 Agent 演化的關鍵階段:
從「能執行」到「能理解」,再到「能學習」。
它不再只是暫時上下文,而是能真實保存與應用經驗的思考系統。
今天,我們讓 Agent 從「能推理」進化為「能學習」。
透過 Reflection × Memory,模型不再只是執行指令的工具,
而是能主動檢討、歸納經驗、並在下一次任務中實際運用所學。
整個過程中:
這不只是技術的進步,而是 Agent 演化的起點——
從『會思考』到『會學習』,Agent 正逐步邁向真正的自我成長。

圖:布拉格查理大橋(Charles Bridge)上的浮雕《王后懺悔圖》(The Queen’s Confession)。銅雕中,騎士腳邊的狗狗因長年被人觸摸,銅面被磨得光亮,形成溫潤的金色光澤。那份歷經時間打磨後的痕跡,如同 Agent 的記憶機制——在不斷的互動與反思中,逐漸被拋光、深化,成為智慧成長的印記。(攝影:作者自攝)

 iThome鐵人賽
iThome鐵人賽