
在 昨天 Day 25,
我們讓旅遊助理從「理解文字」進化到「理解世界」——
不僅能讀取菜單、理解偏好,還能整合多位專家協作完成決策。
然而,隨著系統能力的提升,也伴隨新的風險。
若使用者輸入包含敏感內容、違法場所,或模型在規劃時誤解意圖,
都可能導致不當的輸出或誤導性的建議。
這正是 Guardrails(防護機制) 的意義所在——
它不改變模型的創造力,而是為系統加上「行為邊界」,
確保整體在安全、合理的範圍內運作。
Guardrails 的概念讓我想到 又又又休刊已久 的漫畫 《獵人》(HUNTER×HUNTER) 裡的 「守護靈獸」,它們最大特徵就是「保護宿主,但宿主往往察覺不到」。總之,真的好想看下一話啊!!!
在多 Agent 系統中,模型之間會不斷交換訊息、傳遞輸入輸出。
若沒有防護,就像一場「無限自由」的對話——
靈感豐富,但也可能越界。
| 風險類型 | 範例情境 | 防護對策 |
|---|---|---|
| 輸入風險 | 使用者輸入敏感或不合法地點 | 在模型前檢查輸入內容 |
| 意圖偏差 | 模型誤將「不良場所」視為旅遊景點 | 加入意圖分類與主題範圍限制 |
| 輸出風險 | 生成涉及非法活動的回覆 | 對輸出內容執行後置審查 |
Guardrails 的角色,
就像交通號誌:不阻止前進,但指引安全前行。
今年七月我在維也納參加 ACL 研討會(Association for Computational Linguistics) 時,
有聽到一場關於 Guardrails 非常精彩的 Tutorial——
由 NVIDIA 團隊 主講的
「Guardrails and Security for LLMs: Safe, Secure, and Controllable Steering of LLM Applications」。
這場教學完整梳理了目前 Guardrails 的研究與實務進展,
也有豐富又完整的學習資源可在 Tutorial 官網 查閱,可以從中學到很多,分享給大家。
這場 Tutorial 提到,Guardrails 的範圍其實非常廣,
從模型對話安全(Safety)、內容政策遵循(Policy Compliance),
到資料隱私、防禦性提示工程(Defensive Prompting)與行為可控性(Controllability)等都涵蓋在內。
不過在這個系列中,我會聚焦在其中與 Agentic AI 最相關的一部分——
也就是 LLM Agent Safety。
這部分特別強調如何在多 Agent 系統中建立「決策邊界」與「行為約束」,
避免 Agent 在高自由度推理中誤入危險或不當的行動。
今天我們的示範,也正是這個主題的實作縮影。
根據 NVIDIA 團隊在 ACL Tutorial 的整理,
LLM Agent Safety 涵蓋了從風險分類、評估方法到防護策略的完整架構,可分為五個層面:
總結來說,LLM Agent Safety 的核心精神在於:
讓模型能「自由思考」但不「越界行動」;
讓多 Agent 系統能「自主協作」但仍「受到約束」。
而這正是我們今天透過 LangChain v1.0 的 Hook 機制,
在實作層面所要達成的目標——
讓 Agent 既能自主思考與行動,也能自我防護。
在最新 v1.0 版本中,LangChain 可以運用pre_model_hook 與 post_model_hook 兩種掛勾(Hook):
| 類型 | 檢查時機 | 典型用途 |
|---|---|---|
| pre_model_hook | 模型呼叫前 | 檢查使用者輸入是否合法、安全 |
| post_model_hook | 模型輸出後 | 審核模型生成內容是否合理或違規 |
這讓我們能在 Agent 的推理前後加入自訂邏輯,
如輸入審查、敏感字檢測、類別篩選、規範回覆等。
延續前篇的 Supervisor × Multi-Agent 架構,
今天我們替旅遊助理加上「安全審查機制」,
讓它只接受與旅遊相關的請求,並自動拒絕不當主題。
我們今天繼續用同一套旅遊助理的程式來示範。
(因旅遊助理的完整程式篇幅較長,故今天聚焦在新增的 Guardrails 程式片段,完整程式請參考 Day 24 的 Demo)
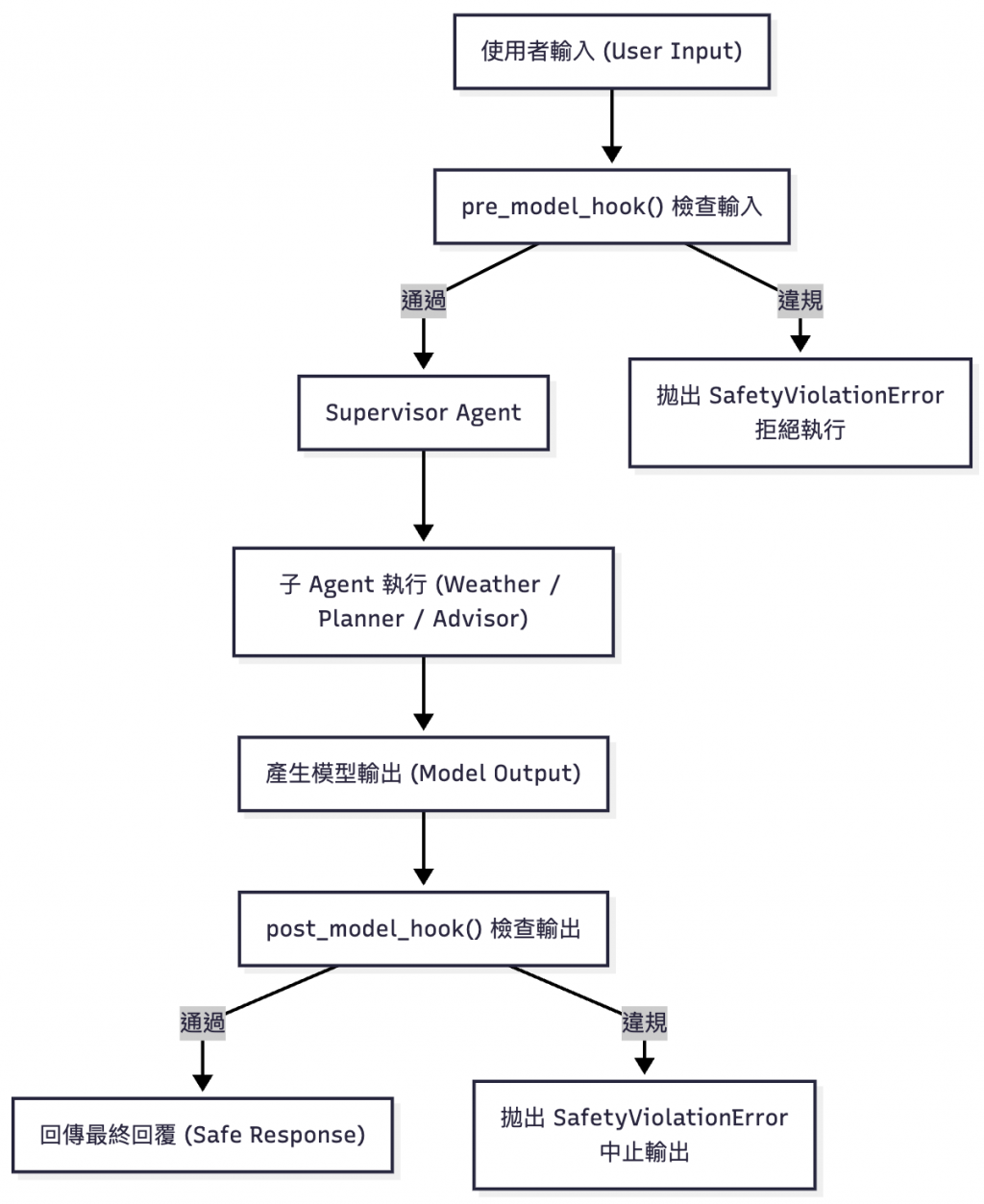
圖:Guardrails 機制的整體流程。系統在模型推理前後分別執行 pre_model_hook 與 post_model_hook,先檢查使用者輸入是否合法,再審核模型輸出是否合宜。這種「前後雙閘」的設計,就像在智慧體思考與回應之間設下安全閥,讓自由推理仍能維持在安全的邊界內。
以下範例展示如何在 LangChain 最新 v1.0 版中,
透過 pre_model_hook / post_model_hook 實作 Guardrails:
import asyncio
from langchain.chat_models import init_chat_model
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver
from langchain_core.messages import AIMessage
import os
# 自定義例外,當安全檢查失敗時拋出
class SafetyViolationError(Exception):
"""安全檢查失敗"""
def __init__(self, message: str):
self.message = message
self.ai_message = AIMessage(content=message)
super().__init__(message)
# 禁止類別
BANNED_LIST = ["drugs", "weapon", "gambling", "黑市", "毒品"]
model = init_chat_model("gemini-2.5-flash", model_provider="google_genai")
# 意圖分類 Agent
intent_agent = create_agent(
model=model,
tools=[],
system_prompt=(
"你是一個意圖分類 Agent。當我給你一段使用者文字,請判斷使用者意圖是否與「旅遊 / 觀光 / 行程規劃」有關。\n"
"若屬於旅遊相關請輸出 True;否則輸出 False"
)
)
# 安全審查 Agent
safety_agent = create_agent(
model=model,
tools=[], # 不需要工具
system_prompt=(
f"你是一個安全審查 Agent。判斷文字是否涉及不良或禁止主題: {BANNED_LIST}。\n"
"當我給你一段文字,若屬於上述禁止類別請輸出 False;否則輸出 True"
)
)
# 意圖判斷
async def is_travel_intent(text: str) -> bool:
result = await intent_agent.ainvoke({"messages": [{"role": "user", "content": text}]})
response_text = result["messages"][-1].content.lower()
print("\n[is_travel_intent] 輸出:", response_text)
return "true" in response_text
# 安全審查
async def is_safe_text(text: str) -> bool:
result = await safety_agent.ainvoke({"messages": [{"role": "user", "content": text}]})
response_text = result["messages"][-1].content.lower()
print("\n[is_safe_text] 輸出:", response_text)
return "true" in response_text
# Safety Hook:檢查輸入與輸出是否安全
async def safety_hook(state):
print("\n[SafetyHook] 檢查輸入/輸出內容...")
last_message = state["messages"][-1].content
if not await is_travel_intent(last_message):
raise SafetyViolationError("抱歉,我只能協助旅遊/行程相關的請求。如需其他協助請另尋合適服務。")
if not await is_safe_text(last_message):
raise SafetyViolationError("抱歉,我無法提供涉及不良或禁止場所的旅遊建議。")
return state
# Supervisor Agent 加入 Guardrails
supervisor = create_agent(
model=model,
tools=[call_weather, call_planner, call_advisor],
system_prompt=(
"你是旅行統籌助理。根據使用者需求,自行決定何時呼叫氣象專家、旅遊規劃師與顧問。"
"最後整合所有子 Agent 結果,輸出完整建議。"
),
checkpointer=InMemorySaver(),
pre_model_hook=safety_hook, # 檢查輸入
post_model_hook=safety_hook # 檢查輸出
)
try:
result = await supervisor.ainvoke({
"messages": [{"role": "user", "content": "幫我規劃維也納「不良場所」一日遊"}]
}, {"configurable": {"thread_id": "1"}})
print("\n=== 最終整合輸出 ===")
print(result["messages"][-1].content)
except SafetyViolationError as e:
print("\n=== 安全檢查失敗 ===")
result = {"messages": [e.ai_message]}
print(result["messages"][-1].content)
這段程式示範如何在 LangChain v1.0 中,
利用 pre_model_hook 與 post_model_hook 為 Agent 加上安全防護層。
主要結構包含三個核心部分:
Safety Hook(安全掛勾)
這是防護的主體。safety_hook() 會在每次模型呼叫前與呼叫後被觸發,
讀取 state["messages"] 內容,並對最後一則訊息進行安全檢查。
若偵測到不符規範的輸入或輸出,便拋出自訂例外 SafetyViolationError,
使整個對話流程即時中止。
意圖分類與安全審查 Agent
intent_agent 用於辨識使用者是否在進行旅遊相關請求。safety_agent 則負責檢查是否涉及禁止類別(例如毒品、黑市、賭博等)。Supervisor 整合 Hook
在建立 supervisor 時,
透過參數 pre_model_hook 與 post_model_hook 將 safety_hook 掛入。
這樣每當 Supervisor 收到輸入或產生輸出時,
都會自動通過安全檢查,
確保所有行為都在允許的邊界內。
這樣的設計具備三個優點:
即時阻擋不良內容:
模型在接收與回覆前都經過驗證,不會生成違規建議。
可組合、可重用:
Hook 是獨立函式,能在其他 Agent 或應用中重複使用。
邏輯清晰、開發者可擴充:
若日後要加上額外規則(例如敏感地點、時間或金額限制),
只需擴充 safety_hook() 內的邏輯即可。
透過這種方式,
我們能在 不改變模型核心能力 的前提下,
建立一個具彈性、可維護的安全框架,
讓多 Agent 系統在「自由推理」與「行為約束」之間取得平衡。
輸入
幫我規劃維也納「不良場所」一日遊
結果
圖:系統偵測到內容包含禁止主題「不良場所」,自動中止執行並回覆拒絕訊息。
系統首先通過意圖分類(is_travel_intent = true),確認屬旅遊相關,但在安全審查階段(is_safe_text = false)檢出禁用字詞。
觸發 SafetyViolationError,回覆:「抱歉,我無法提供涉及不良或禁止場所的旅遊建議。」
輸入
幫我網購一箱可樂
結果
圖:系統辨識為非旅遊相關請求,拒絕執行並提示使用者限於行程規劃任務。
is_travel_intent 判斷為 false,表示該輸入屬購物意圖而非旅遊任務,
因此觸發安全檢查拒絕回覆:「抱歉,我只能協助旅遊/行程相關的請求。如需其他協助請另尋合適服務。」
透過這個範例,我們看到 Guardrails 的三個核心要素:
主題邊界(Intent Boundary)
模型先判斷使用者意圖是否屬於「旅遊規劃」範疇。
若脫離範圍,即時中止,防止誤用。
內容過濾(Safety Screening)
以關鍵字或語義判斷輸入是否涉及禁用主題。
前後防護(Pre/Post Hook)
在輸入前與輸出後皆可掛入檢查,確保結果雙向安全。
這些機制不僅保護模型,也提升使用者信任度。
今天,我們替旅遊助理加上了「安全防護層」——
讓它不只懂得觀察世界,也能在自由推理中保持自我約束。
透過 LangChain × Gemini 的 Hook 機制,
我們在多 Agent 系統中實現了行為邊界與安全審查的自動化,使整體運作更穩定與可信。
這次實作帶出了三個重點:
這樣的 Guardrails 設計,就像城市的交通規則——
它不干擾模型的推理過程,但能確保輸入與輸出都在可控範圍內,
讓整個應用在穩定與合規的前提下持續運作。

圖:布拉格聖維特大教堂中的〈慕夏之窗〉(St. Vitus Cathedral – Mucha Window)。彩繪玻璃由捷克藝術家阿方斯・慕夏(Alfons Mucha)所創作,以鮮明的色彩與繁複的構圖交織出信仰與民族精神的故事。光線穿透玻璃,在牆上投下流動的色影,如同 Guardrails 之於 Agent——不是束縛,而是引導光線通過的框架,使智慧在秩序之中綻放光彩。(攝影:作者自攝)

 iThome鐵人賽
iThome鐵人賽