Day 21 我們用 快取 把重複查詢變快、變省;
Day 22 有了 Registry,管理不同模型與知識版本;
Day 23 談了 再訓練與持續學習,讓模型能力與知識庫具備正確性。
但現實世界還有另一個挑戰:
因此,今天我們要介紹的是:模型路由(Routing)。
核心精神是:讓不同任務分流到合適的模型,達成成本、延遲與品質的平衡。
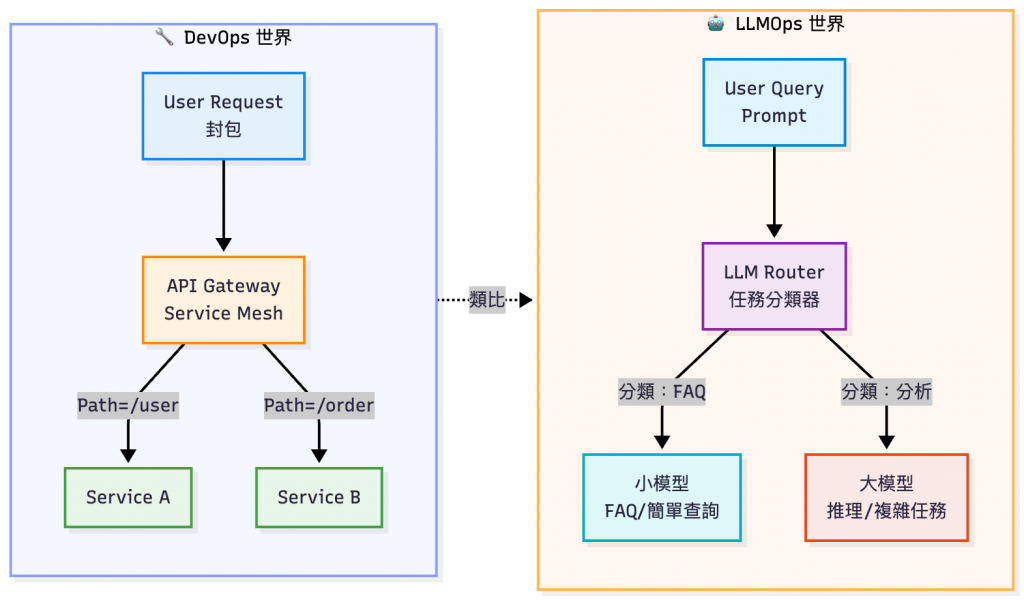
在 DevOps 世界,Routing 是日常:
API Gateway 會根據路徑或規則,將使用者的請求導向正確的後端服務;Service Mesh(如 Istio、Linkerd)則能在服務之間控管流量,支援金絲雀發布、A/B 測試或故障回退。
場景來到 LLMOps,我們做的事其實非常相似:
只是 「封包/請求」換成了「任務/Prompt」,而 「後端服務」則換成了「模型」。 同樣需要透過 Routing 機制,把任務分流到最合適的模型,以在 成本、延遲與品質 之間取得平衡。
企業客服場景
內部文件檢索
高峰流量下的查詢分流
安全與合規需求
[註1] An air traffic controller for LLMs. - 設計 LLM Router,將 FAQ 導向小模型,能讓推理成本降低 85%,同時維持接近大模型的回答品質。
[註2] Multi-LLM routing strategies for generative AI applications on AWS - AWS 提出 Multi-LLM Routing,利用 embedding 判斷意圖:簡單文件摘要交小模型,複雜推理交大模型。
[註3] How to Reduce LLM Costs: 10 Proven Strategies for Budget-Friendly AI - 成本改善策略:將 70% 簡單查詢交小模型,30% 複雜查詢升級大模型,可顯著降低成本與延遲。
[註4] "I Always Felt that SomethingWasWrong.": Understanding Compliance Risks and Mitigation Strategies when Highly-Skilled Compliance Knowledge Workers Use Large Language Models - 研究顯示,專業人士在法務/醫療等高風險領域使用 LLM 時,低成本模型可能帶來嚴重風險;高風險任務必須由可靠度更高的大模型處理。
| 策略類型 | 實作 / 維護成本 | 推理開銷 | 延遲影響 | 適用場景 |
|---|---|---|---|---|
| 規則式路由(Rule-based) | 低:只需人工設定規則(關鍵字、長度等),維護簡單 | 幾乎 0,比對字串即可 | 極低,毫秒級 | FAQ 分流、固定格式任務 |
| 分類器路由(Classifier-based) | 中:需要設計分類器(小模型 / embedding),偶爾再訓練 | 低–中:小模型或 embedding 計算[註1] | 低,毫秒–數百毫秒 | 意圖分類、難度判斷 |
| 成本感知路由(Cost-aware) | 中–高:需要建置監控(延遲、成本、SLA)與動態決策邏輯 | 中:多一步決策運算 | 中:需觀察狀態再分流 | 高峰流量控管、SLA 場景 |
| Agent 工具選擇(Agent-based) | 高:需要完整框架、工具選擇邏輯與保護欄 | 高:Agent 本身是小推理任務 | 高:多步推理,延遲最明顯 | 複雜多步任務、自主工作流 |
不同 Routing 策略雖然能節省 API 成本,但本身也會引入額外開銷。規則式最便宜,Agent 最靈活但延遲最高;分類器與成本感知則是許多企業實務中的折衷選項。
[註1] MixLLM: Dynamic Routing in Mixed Large Language Models - 提供了一個動態路由系統,對 query 做 cost/quality/latency 的權衡。這篇能直接支撐「高峰流量分流」案例,以及「分類器 + 成本感知路由」的成本與效益分析。實驗中在保品質前提下,用大約 24.18% 的成本 達到接近 GPT-4 的品質。
實作面可以參考 [[Day19 - 掌握 LLM 應用可觀測性:監控延遲、Token 與成本(含工具選型)]]
| 維度 | 指標 | 說明 |
|---|---|---|
| 效能 | latency_p50 / p95 / p99 | 不同百分位的延遲,觀察用戶體感是否穩定 |
| throughput (QPS) | 系統每秒可處理的請求數,衡量可擴展性 | |
| cache_hit_rate | 查詢在升級前被快取命中的比例,越高代表節省成本越多 | |
| 成本 | cost_per_token / cost_per_request | 平均每個請求或每個 Token 的成本 |
| token_usage_distribution | 小模型 vs. 大模型 Token 使用比例,衡量分流是否有效 | |
| budget_burn_rate | 預算消耗速度,幫助團隊控管月度或季度成本 | |
| 品質 | route_success_rate | 任務第一次就被導到正確模型的比例 |
| escalation_rate | 小模型答不動 → 升級到大模型的比例 | |
| reroute_rate | 請求在不同路由之間多次切換的比例,過高代表策略需調整 | |
| answer_acceptance_rate | 使用者對回答的隱性/顯性滿意度(人工標註或追問率) | |
| 風險/可靠性 | fallback_rate | 大模型出錯(429/5xx/超時)後回退的比例 |
| error_rate | API 錯誤比例,含 429、5xx 等 | |
| sensitive_data_block_rate | 被輸入/輸出過濾器攔截的比例(避免資料外洩) | |
| hallucination_alerts | 偵測到幻覺或與知識庫不一致的回答次數 |
這些指標其實就是 「Routing 的 SLO」,用來回答三個問題:
SLO(Service Level Objective):在 DevOps中,SLO 指的是「我們希望服務在效能、成本、品質、可靠性上達到的目標數字」。
今天的文章一樣有 Demo 情境展示,然而實務上不一定要自己從零開始寫 Router。Demo 只是為了幫助初次接觸 LLMOps 概念的讀者對 Router 的功用有個雛形。
| 方案類型 | 代表工具 | 特色 |
|---|---|---|
| 極簡整合 | OpenRouter | 統一 API,自動選模型,可擴展到企業(SaaS) |
| 多雲管理 | LiteLLM | 開源自架,支援 100+ Provider,負載均衡 |
| 企業 Gateway | Portkey | SaaS託管 + 開源Gateway可選,智慧路由 |
| 精準路由 | RouteLLM | 開源自架,可訓練路由模型 |
| 雲端原生 | AWS Bedrock / Azure AI | 雲端整合,自動路由 |
| OpenRouter | LiteLLM | RouteLLM | Portkey | 雲端服務 | |
|---|---|---|---|---|---|
| 路由邏輯 | 自動 | 規則+策略 | ML模型 | 智慧路由 | 自動 |
| 多模型支援 | ✅ 300+ | ✅ 100+ | ✅ 任意 | ✅ 1600+ | ✅ 雲端內 |
| 成本追蹤 | ✅ | ✅ | ❌ | ✅ | ✅ |
| Fallback | ✅ | ✅ | ❌ | ✅ | ✅ |
| A/B 測試 | ❌ | ❌ | ❌ | ✅ | 部分 |
| 可訓練 | ❌ | ❌ | ✅ | ❌ | ❌ |
| 部署模式 | SaaS | 開源自架 | 開源自架 | SaaS託管 + 開源Gateway可選 | 雲端 |
| 學習曲線 | ⭐ 極簡 | ⭐⭐ 中等 | ⭐⭐⭐ 較高 | ⭐ 簡單 (SaaS)⭐⭐ 中等 (開源) | ⭐⭐ 中等 |
| 推薦指數 | ⭐⭐⭐⭐ 通用 | ⭐⭐⭐⭐⭐ 自架首選 | ⭐⭐⭐ 進階 | ⭐⭐⭐⭐ 企業 | ⭐⭐⭐⭐ 雲端 |
| 適用場景 | 快速驗證→企業 | 自架部署,多雲管理 | ML驅動路由 | 企業級完整方案 | 雲端生態 |
💡 閱讀建議: 這張表適合「已經知道要比較哪幾個工具」的讀者,學習曲線和推薦指數為筆者主觀評斷,請以實際環境下最後決策。
[註1]:雲端服務的「自動」多指同產品線或受支援範圍內的智慧選擇;跨供應商路由需看各雲支援情形。
[註2]:RouteLLM 專注於訓練式決策;Fallback/重試通常交由外層網關(如 LiteLLM、Portkey 或自建)處理。
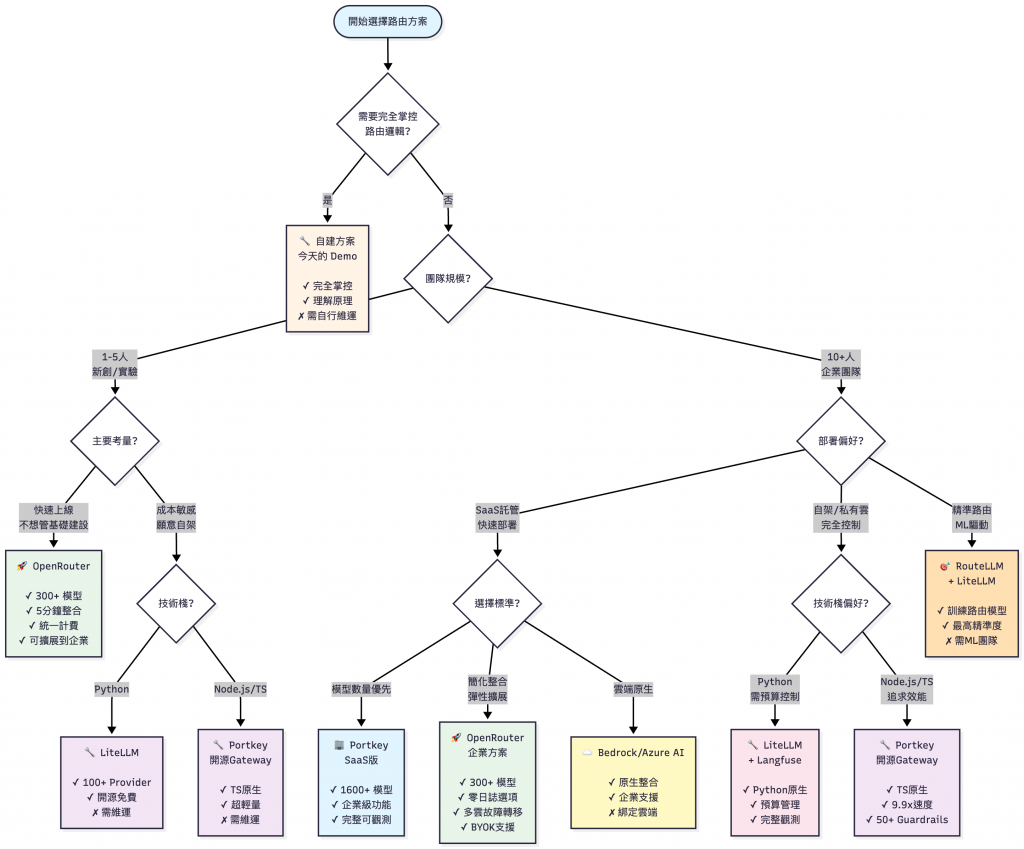
💡 本文數據更新於 2025/10/16
決策樹內的支援數量可能會持續更新,以官方文件最新為準。
因為篇幅關係,完整可執行專案一樣會放在 GitHub,完整的細節請看
README.md。
⚠️ 這個範例完全可以離線執行,不需要 OpenAI API Key。
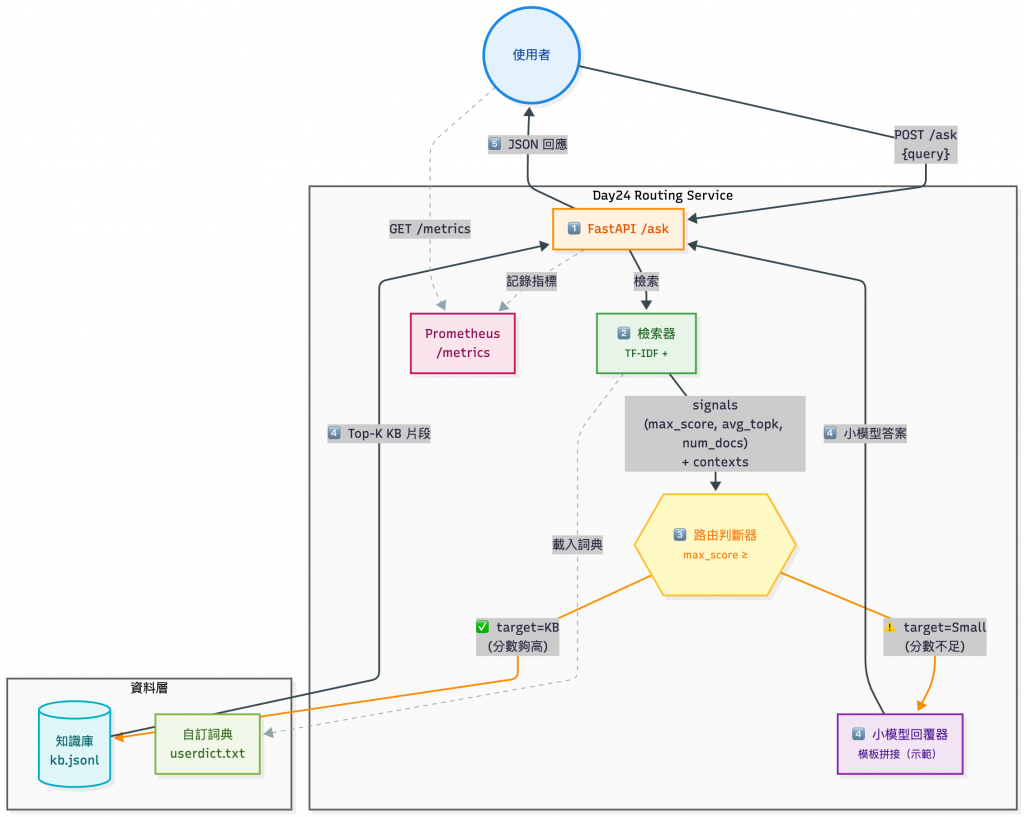
這個 Demo 展示了 多路由決策策略 (Classifier Routing) 的概念。
系統不會一律把問題送到外部 LLM,而是先透過本地的 檢索訊號(max_score、avg_topk、num_docs、context_len)進行判斷:
📝 檢索訊號解釋
max_score:最相關那一段的「相似度分數」,如果這個值很高,代表至少有一個 KB 條目(document)和 Query 高度相關。
avg_topk:前幾段(Top-k)平均的相關度,衡量整體檢索 KB 條目(document)的相關性;能避免單一高分 KB 條目誤導判斷。
num_docs:這些 KB 條目分別來自幾份 KB 條目?(只命中 1 份 = 很集中;命中很多份 = 需要比對或整合)
context_len:回傳的檢索 KB 條目總字數,反映檢索結果的資訊量;太少可能代表內容不足。
透過這種「分類器式路由 (Classifier Router)」,可以在 成本、延遲、品質 之間取得平衡,非常適合:
這個 Demo 會需要先準備兩個檔案,分別是 kb.jsonl 以及自訂詞典 userdict.txt:
kb.jsonl:
{id, text}。{"id":"faq-001","text":"公司 VPN 設定:下載新版客戶端,並以 SSO 登入;首次登入需註冊 MFA。"}
{"id":"faq-002","text":"請假流程:登入 HR 系統提交假單,主管核准後會自動同步至行事曆。"}
{"id":"faq-003","text":"內部 Wi-Fi:SSID 為 Corp-5G,密碼由 IT 每季輪替,詳見內網公告。"}
{"id":"faq-004","text":"報帳規範:差旅需上傳發票影本,填寫報銷單並經部門主管審核。"}
{"id":"faq-005","text":"開發流程:所有新功能必須先建立 Pull Request,經至少兩人 Code Review 通過後才能合併。"}
{"id":"faq-006","text":"版本控制:主幹分支為 main,禁止直接推送,必須透過 Pull Request 流程合併。"}
{"id":"faq-007","text":"例行會議:每週一上午 10 點為團隊例會,需準備上週進度與本週計劃。"}
{"id":"faq-008","text":"IT 支援:若遇到電腦故障或帳號問題,請至 IT Helpdesk 提交工單。"}
{"id":"faq-009","text":"年度健檢:公司會於 9 月安排員工年度健康檢查,報名方式會提前寄送 Email。"}
{"id":"faq-010","text":"出差規定:出差需事先填寫申請單,並附上行程表,經主管批准後方可訂票。"}
userdict.txt
⚠️ 我這邊之前用英文系的
tokenizer套件來切詞,但效果不好 XD ,會把詞切壞掉
公司VPN
VPN
SSO
MFA
請假流程
請假
報帳規範
出差規定
出差補助
內部Wi-Fi
Wi-Fi
版本控制
Pull Request
Code Review
年度健檢
健康檢查
例行會議
IT支援
Helpdesk
在今天的 Demo 裡,Router 並不是一個複雜的 ML 模型,而是一個 閾值式分類器(Threshold-based Classifier),它會根據 檢索訊號(retrieval signals)來判斷:
程式片段如下:
def decide(signals: RetrievalSignals) -> RouteDecision:
go_kb = (
(signals.max_score >= THRESH_MAX or signals.avg_topk >= THRESH_AVG)
and signals.num_docs >= MIN_DOCS
)
target = "kb" if go_kb else "small_model"
reason = (
f"max={signals.max_score:.2f} avg={signals.avg_topk:.2f} "
f"docs={signals.num_docs} → {target}"
)
return RouteDecision(target=target, reason=reason, signals=signals)
如果有命中知識庫 (kb.jsonl) 裡的一筆資料(num_docs >= 1),且符合以下條件任一,就會直接走 KB 回覆模式:
max_score)avg_topk)否則會丟給小模型 (llm_small.py)。
那 signals 是誰算出來的?答案是 retriever:
self.vectorizer = TfidfVectorizer(
tokenizer=lambda s: list(jieba.cut(s, HMM=True)),
token_pattern=None,
ngram_range=(1, 2),
max_features=20_000,
norm="l2"
)
self.matrix = self.vectorizer.fit_transform(self.texts)
在這段程式碼中,我們會用 jieba 切中文詞,再丟進 TF-IDF,Query 進來時,會由這個步驟轉換,然後和 KB 做點積相似度。
經過轉換後我們會得到:
max_score(最高相似度)avg_topk(前 K 平均分數)num_docs(有多少 KB 條目有命中)這些就是 Router 的決策依據。
📖 名詞解釋
jieba
Python 常用的中文斷詞套件。中文不像英文有空格,必須先把句子切成詞才能做檢索或向量化。
句子:「如何設定公司 VPN?」 jieba → ["如何", "設定", "公司", "VPN"]
- TF-IDF(Term Frequency – Inverse Document Frequency)
一種傳統的文字表示方法:
- TF:一個詞在 KB 條目裡出現的頻率
- IDF:一個詞在所有 KB 條目裡有多常見(越常見 → 權重越低)
結果:常見的「的、了」權重很低,重要關鍵詞「VPN、請假流程」權重較高。- 點積相似度(Dot Product Similarity)
當 KB 條目和查詢都轉換成向量後,可以計算兩個向量的「點積」來衡量相似度。
- 值越大 → 代表越相關
- 值接近 0 → 幾乎沒關係
❯ curl -s http://localhost:8000/ask \
-H "content-type: application/json" \
-d '{"query":"如何設定公司 VPN?","top_k":3}' | jq
{
"answer": "公司 VPN 設定:下載新版客戶端,並以 SSO 登入;首次登入需註冊 MFA。",
"route": {
"target": "kb",
"reason": "max=0.38 avg=0.18 docs=8 → kb", # 直接用 KB (Knowledge Base) 回答
"signals": {
"max_score": 0.3766860747925358,
"avg_topk": 0.17816988020579652,
"num_docs": 8,
"context_len": 135
# 代表 Top-1 分數 0.38,平均 0.18,找到 8 筆 KB 條目,因此判定走 KB
}
},
"contexts": [ # Top-K 的檢索結果清單。
{
"id": "faq-001",
"text": "公司 VPN 設定:下載新版客戶端,並以 SSO 登入;首次登入需註冊 MFA。",
"score": 0.3766860747925358
},
{
"id": "faq-009",
"text": "年度健檢:公司會於 9 月安排員工年度健康檢查,報名方式會提前寄送 Email。",
"score": 0.09389546005229006
},
{
"id": "faq-005",
"text": "開發流程:所有新功能必須先建立 Pull Request,經至少兩人 Code Review 通過後才能合併。",
"score": 0.06392810577256372
}
],
"usage_tokens_est": 12, # 估算這次回答大約用了多少 Token
"cost_usd_est": 0.0. # 小模型推理成本估算(因為用 KB 回答,所以這裡是 0)
}
# Wi-Fi
❯ curl -s http://localhost:8000/ask \
-H "content-type: application/json" \
-d '{"query":"內部 Wi-Fi 密碼是多少?","top_k":3}' | jq -r '.route.reason'
max=0.55 avg=0.24 docs=8 → kb
# 健檢報名(模糊關聯:年度健檢,但問題不同)
❯ curl -s http://localhost:8000/ask \
-H "content-type: application/json" \
-d '{"query":"公司的健檢報名流程是?","top_k":3}' | jq -r '.route.reason'
max=0.10 avg=0.09 docs=4 → small_model
# KB 裡沒有「午餐補助」相關內容,檢索分數低,走小模型回覆客服模板回答
❯ curl -s http://localhost:8000/ask -H "content-type: application/json" -d '{"query":"午餐補助怎麼領?","top_k":3}' | jq -r '.answer'
目前知識庫沒有足夠線索,建議改以工單/人力支援處理。
接續 Day19 - 可觀測性(Observability) — 延遲、Token 與成本 的概念,本次 Demo 也有紀錄 Prometheus 格式的指標,方便後續接入 Grafana 或其他監控工具。
可以透過以下指令呼叫:
# 直接查看前 20 行
❯ curl -s http://localhost:8000/metrics | head -n 20
# HELP day24_requests_total Total API requests
# TYPE day24_requests_total counter
day24_requests_total{route="/ask"} 3.0
# HELP day24_request_latency_seconds Request latency histogram
day24_request_latency_seconds_bucket{le="0.1",route="/ask"} 2.0
day24_request_latency_seconds_bucket{le="0.3",route="/ask"} 3.0
day24_request_latency_seconds_count{route="/ask"} 3.0
# HELP day24_route_decision_total Route decision counts
day24_route_decision_total{target="kb"} 2.0
day24_route_decision_total{target="small_model"} 1.0
# 查看路由決策分布
❯ curl -s http://localhost:8000/metrics | grep day24_route_decision_total
# HELP day24_route_decision_total Routing target
# TYPE day24_route_decision_total counter
day24_route_decision_total{target="kb"} 2.0
day24_route_decision_total{target="small_model"} 1.0
# 查看 Token 使用量
❯ curl -s http://localhost:8000/metrics | grep day24_tokens_total
# HELP day24_tokens_total Estimated tokens used
# TYPE day24_tokens_total counter
day24_tokens_total{role="prompt"} 7.0
day24_tokens_total{role="completion"} 42.0
我們的 Demo 用的是 簡單的閾值式分類器。雖然清楚,但在實戰裡還有很多強化手法,可以讓路由更精準、更安全:
Embedding 後比對最接近的類別,再決定路由。SMALL / LARGE,而是從 Registry 讀取當前 Production 版本 → 方便金絲雀部署、回滾。 👉 Day22 - 版本管理(Versioning)👉 Day25 – 安全防護(Security Guardrails)— 端到端防禦 Prompt Injection 與資料外洩 會談到這部分。
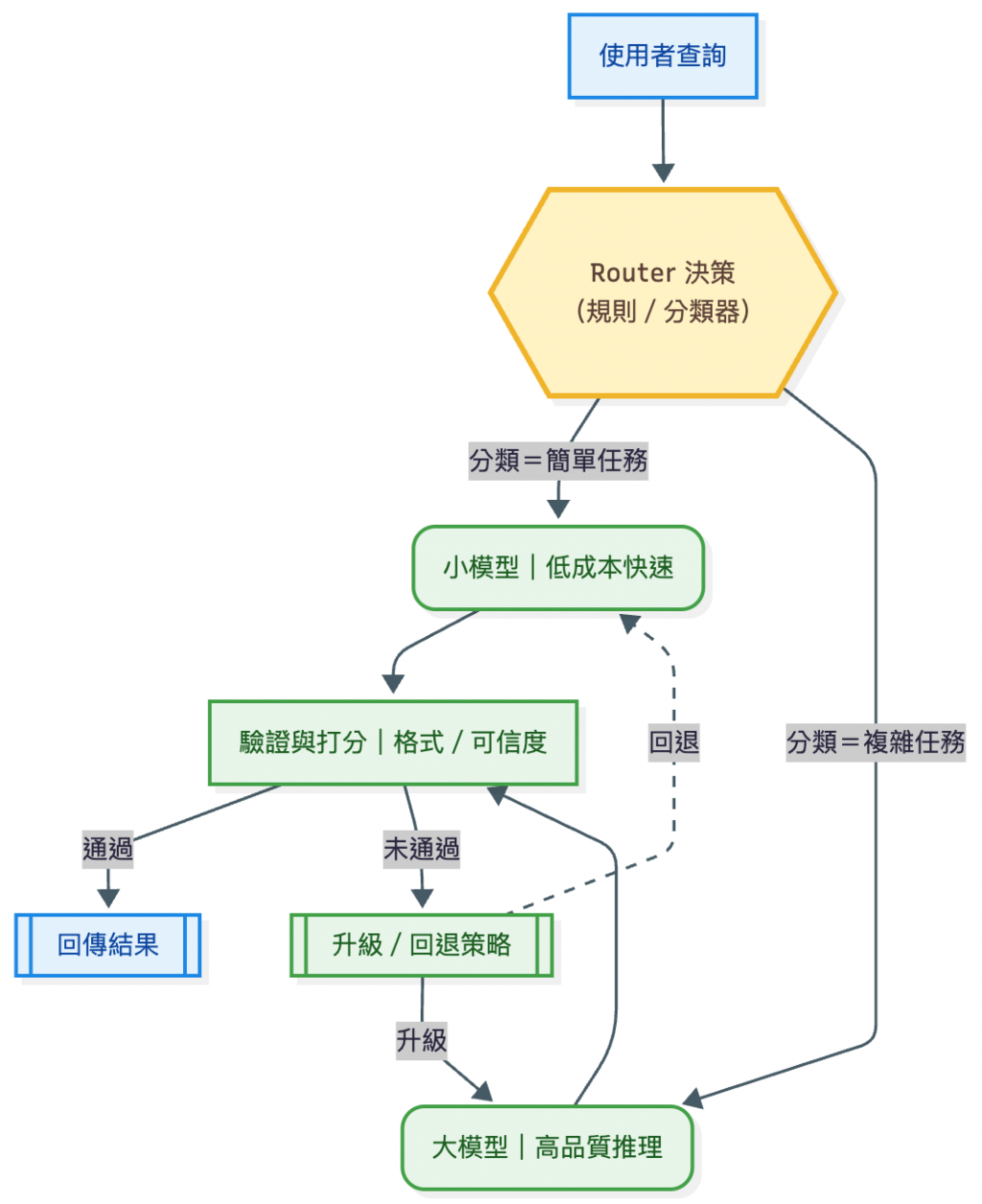
註:這是 企業內部典型架構,比本次 Demo 更完整,能支援 自動升級 / 回退、AB 測試、金絲雀流量分配 等機制
- 本圖參考自:
- IBM Research — LLM Routers
- AWS Machine Learning Blog — Multi-LLM Routing Strategies
今天(Day24)我們了解了:
明天(Day25)我們將進一步探討 安全性挑戰:包含 Prompt Injection、資料洩漏、以及企業必備的防護清單。

