回顧 LoRA 微調之路:
今天重新從 DevOps 角度切入,聊聊:如果真的要做微調模型,部署到生產環境可能有哪些考量?
| 項目 | 說明 |
|---|---|
| 筆者背景 | Site Reliability Engineer(非 ML 工程師或 AI 專家) |
| 內容基礎 | Day 32/33 微調經驗 + DevOps 方法論 + ArXiv 論文研究方法 |
| 你會得到 | 筆者角度出發的決策框架、檢查清單、troubleshooting 流程 |
| 不會看到 | 複雜數學公式、深度 ML 理論 |
| 適合讀者 | DevOps Engineer / SRE、Backend Engineer、Tech Lead |
💡 如果你的團隊有專業 ML 工程師,請諮詢他們的建議、共同調整本文方案。
本文內容為筆者主觀角度解讀,請依照實際環境斟酌採納文中所提之方案。
「在經歷 Day33 N 次失敗的微調實驗後,我發現:
Fine-tuning 的 Debug 過程,很像是在做 Root Cause Analysis。」
| 我在 Day 33 做的事 | SRE 技能 | 日常工作對應 |
|---|---|---|
| 觀察 training loss 曲線 | 監控指標異常 | 看 Grafana dashboard 發現 latency 飆高 |
| 收集 train_loss / eval_loss / 相似度 | Observability | 收集 metrics、logs、traces |
| 假設「learning rate 太高」 | 建立問題假設 | 猜測是 DB connection pool 不夠 |
| 調整參數重新微調 N 次 | 實驗驗證 | 調整 config 重啟服務測試 |
| 發現「災難性遺忘」 | 找到 root cause | 確認是 GC pause 導致 timeout |
| 記錄完整過程 (Day 33) | 寫 postmortem | 寫 incident report |
💡 共同本質:在不確定性中建立因果關係,透過實驗和觀察指標找出問題根源。
SRE 平常的工作需要和 RD 們密切合作。
即便不是親手實踐程式碼的我們,如果不梳理業務邏輯,便無法制定可以正確反應系統的狀況的指標以及合適的告警機制。換到 LLMOps 的情境亦然,我們 不需要會訓練或是微調模型,但要能評估技術方案與排查線上問題,如果不嘗試了解這些 ML 術語,會增加排查問題時的 溝通成本 和 時間成本(MTTR,平均修復時間)。
⚠️ 場景純屬虛構,如有雷同,純屬巧合,且請珍惜。
老闆:「我從後台看有大量用戶抱怨回答品質不佳、bot 亂回答、沒有解決問題還浪費時間!你們怎麼解決?」
ML 工程師:「我有先確認過這版模型,在測試集的相似度還有 90%,沒有退化。問題比較像是線上的檢索或 Prompt 出狀況。」
SRE:「我這邊也看到異常。更新知識庫後,檢索延遲從 200ms 拉到 500ms,而且有 15% 的查詢抓不到文件。」
Data Engineer:「我查一下新資料。」
[1 小時後]
Data Engineer:「發現問題:
1.新資料有 8% 格式異常(空欄位、特殊字元)
2.chunk 平均長度從 400 token → 280 token
我先產出資料品質報告。」
ML 工程師:「看來是資料問題 + chunk 切法不合。我的方案: 優先順序
1:調整 chunk size(500/80),預計召回率[註1]可恢復到 >90% 優先順序
2:如果還不行,測試 bge-large 替換 bge-base
門檻:如果調完召回率還 <85%,建議做 Fine-tuning。」
SRE:「好,我這邊幫你準備 staging 環境做 A/B 測試,同時監控調整前後的延遲、QPS 和錯誤率。召回率的部分你那邊追蹤,我們週五一起看數據。如果需要添加更多 GPU 或調整 replica 數量,跟我說。」
老闆:「可是客訴率都提高到 20% 了,光靠這些修修補補真的夠嗎?」
ML 工程師:「如果 retriever 和 Prompt 都調過了,品質還回不來,那就可能要考慮 Fine-tuning。讓模型直接學我們新添加的資料,才有辦法更穩定。如果調完品質還回不到 85%,我建議做 Fine-tuning。」
老闆:「Fine-tuning 要花多少錢?」
SRE:「(思考了一下 ROI)預估每月增加 1-3 千美金 GPU 費用,加上 1 個 ML 工程師專職維護。」
老闆:「(皺眉)這麼貴?有沒有更省錢的做法?」
ML 工程師:「(思考)恩...,我們先把資料和檢索調好,如果召回率能到 85% 以上,就不需要 FT。根據過往數據,召回率每提升 10%,客訴率約降低 5-8%。 如果我們能把召回率從現在的 75% 拉到 85%,客訴率應該能降回 12-15%。
老闆:「下週三給我結果,如果真的非做不可,你們要準備完整的成本效益分析給我看。」
ML 工程師:「了解,我週三前給你:
1.調整後的召回率數據
2.是否需要 Fine-tuning 的評估報告」
SRE:「我同步準備 Fine-tuning 的部署方案和成本分析,以防萬一。」
[註1]召回率 (Recall) = 檢索到的相關文件數 / 所有應該被檢索到的相關文件總數,在所有正確答案中,找到了多少個?
SRE 的價值:用決策樹思考避免過度工程化和額外的維護成本,曲突徙薪,選最划算的方案。
這個場景的決策重點:
老闆:「上次不是說要調整檢索和 chunk?現在結果怎樣?」
ML 工程師:「我這邊跑了 embedding 對比,換成 bge-large 確實好一點,召回率提升了 5%。另外做了 Prompt 微調,拒答準確率也提高了。staging 環境測試下來,品質達到 87%。」
QA:「我看了測試報告,功能測試都過了,但我想確認一下:你們 staging 測試的負載量是多少?」
ML 工程師:「大概 10 QPS,主要是驗證模型品質和準確度。」
QA:「10 QPS?但我們線上高峰是 500 QPS,這個負載差距有點大。高流量下的表現需要確認一下。」
SRE:「對,我也有這個疑慮。而且從系統指標來看,延遲壓回到 280ms,P95 latency 在 2.7 秒,單 pod 記憶體 2 GB,在正常負載下都還好。但 500 QPS 的情況我們還沒實測過。我建議這樣:我們先在 staging 環境做 250 QPS 壓測(約 50% 峰值),跑個 20 分鐘看看,觀察 P95、CPU、記憶體、還有外部服務的限流情況。穩住了再走灰度發布。」
ML 工程師:「我補充一下,幻覺率從 3% 增加到 3.5%,這是因為新的 embedding 模型更敏感,會匹配到一些相關性較弱的文件。當模型參考這些邊緣文件時,可能產生不夠準確的回答。不過 3.5% 還在我們設定的 5% 安全範圍內。在高流量下,這個指標可能會有變化,我會持續監控。」
QA:「所以灰度流程是怎樣?我需要知道驗收標準。」
SRE:「灰度流程我是這樣想的:第一天先給 10% 流量,跑 24 小時看看。如果穩定,再往上加到 30%、50%,最後才全量。回滾條件我設了三個:
- 第一個是延遲,P95 如果超過 3 秒,而且連續 15 分鐘都這樣,就回滾
- 第二個是錯誤率,5xx 或業務錯誤超過 0.5%,持續 10 分鐘以上,也回滾
- 第三個是品質,Zero-hit 超過 5%,或者關鍵意圖品質掉到 85% 以下,一樣回滾
這些條件超過就切回舊版。」
ML 工程師:「關鍵意圖品質這個我會持續監控,特別是客訴最多的幾個場景。」
QA:「好,那我這邊準備功能驗收的 checklist,確保核心流程在每個階段都能正常運作。」
老闆:「87%?上次你們不是說低於 85% 才考慮 Fine-tuning?現在看起來應該不用 Fine-tuning 了?」
ML 工程師:「87% 確實超過門檻了。我建議先上線觀察,如果關鍵意圖品質低於 85%,或者 48 小時內持續下滑,我們再考量是否正式執行 Fine-tuning 計畫。」
SRE:「同意。而且現在的方案幾乎不花錢,Fine-tuning 的話,我估的 3000 美金是用 OpenAI FT 的增量推理成本。如果改成自建 GPU,在 500 QPS 高峰下成本會更高。我會在報告裡把兩個方案分開估給您看。」
老闆:「好,那就照這個計畫上線,但我要看到每天的品質報告, 特別是客訴率的變化。如果品質持續下滑或客訴率沒降低,我們就來討論這個 Fine-tuning。下週給我完整報告,把兩種方案的成本都列進去,還有如果最後需要 FT,新版本多久可以上線。」
ML 工程師 & SRE & QA:「了解。」
SRE 的價值:在 ML 關注模型品質、QA 關注測試完整性的基礎上,補充生產環境的容量驗證(壓測)、部署策略(灰度流程)、風險控制(自動回滾條件)和成本分析,確保安全且經濟地上線。
這個場景的決策重點:
🚨 告警觸發:幻覺率從 3% 飆到 8% (AM 2:00)
SRE(被手機吵醒,檢查監控):「幻覺率飆到 8%,我先回滾到 v1.2.0。」
[執行回滾]
SRE(在 Slack):@ml-team @data-team 「線上已恢復。昨晚 23:45 開始幻覺率飆升,有誰動過索引或資料?附件:[monitoring_dashboard_link]」
ML 工程師:「我們昨天上了 v1.2.1,把 chunk 從 600/100 overlap 改成 350/50,還加了一批新資料。」
SRE:「時間點一致,我在 staging 重現看看。@data-team 麻煩早上幫忙查昨天新添加的資料品質。」
早上會議(AM 10:00)
老闆:「昨天 incident 怎麼回事?」
SRE:「凌晨幻覺率飆到 8%,我在 3 分鐘內回滾到舊索引,線上恢復正常。異常發生在 index@v1.2.1 上線之後。」
Data Engineer:「我早上跑了 profiling,發現昨天入庫的新資料有問題: - 15% 空欄位 - 3.2% 重複樣本 - 平均 token 長度從 450 降到 280」
ML 工程師:「我們發現原因是新資料有格式問題,加上 chunk 調得太小,導致語意切太碎、召回率下降。
今天修復計畫:
1. 清理資料,加上 schema 驗證與空文本檢查
2. 重嵌有問題的資料並重建索引 [index@v1.2.1-hotfix]
3. 驗證關鍵意圖召回率 ≥85%」
SRE:「我的部分:
1. 對 [index@v1.2.1-hotfix] 做 250 QPS 壓測 + P95/CPU/記憶體檢查
2. 灰度 rollout:10% → 30% → 50% → 100%,回滾條件已設好
3. 撰寫 postmortem」
QA:「我會跑回歸測試,驗證核心問答流程。」
老闆:「好,但 bot 後台用戶抱怨沒有顯著提升,不太明白新資料的用途??今天先上 hotfix ,這週五 sprint 雙週會要有報告和改進方案。」
會後對話
ML 工程師:「老闆那句話...我們是不是方向錯了?」
SRE:「有可能。我看了一下客戶問題分類,80% 是產品功能的問題,不是新資料所提到的關於產品外觀的問題。」
ML 工程師:「所以我們為了提升召回率加的這些跟產品外觀有關的新資料,可能用戶不太在乎這個?」
SRE:「不然下午跟 PM kick-off 會議,談談用戶真正的痛點是什麼?先確認需求優先級,不然之後老闆還是會問一樣問題。」
ML 工程師:「好,先把 hotfix 修好,再來整理改善方向。」
SRE 的價值:有系統化的應對流程(快速止血、找出根因、提出改進),同時將失誤轉化為系統性改進機會,避免事故演變成指責大會。
這個場景的決策重點:
上面三個故事場景,展現了 SRE 在技術會議中的價值:
| 場景 | SRE 角色 | SRE 做的事 | 對應下方章節 |
|---|---|---|---|
| 場景 1 | 成本守門人 | 成本分析(USD$1-3K/月)設定決策門檻(品質 <85%) | 👇 成本評估👇 決策框架 |
| 場景 2 | 風險控制者 | 灰度流程(10%→30%→50%)設定回滾條件(P95、錯誤率) | 👇 監控指標 |
| 場景 3 | 系統改進推動者 | 快速回滾(3分鐘止血)Root Cause Analysis | 👇 風險矩陣 |
接下來,我們把這些「臨場決策」,整理成「可重複使用的框架和檢查清單」。
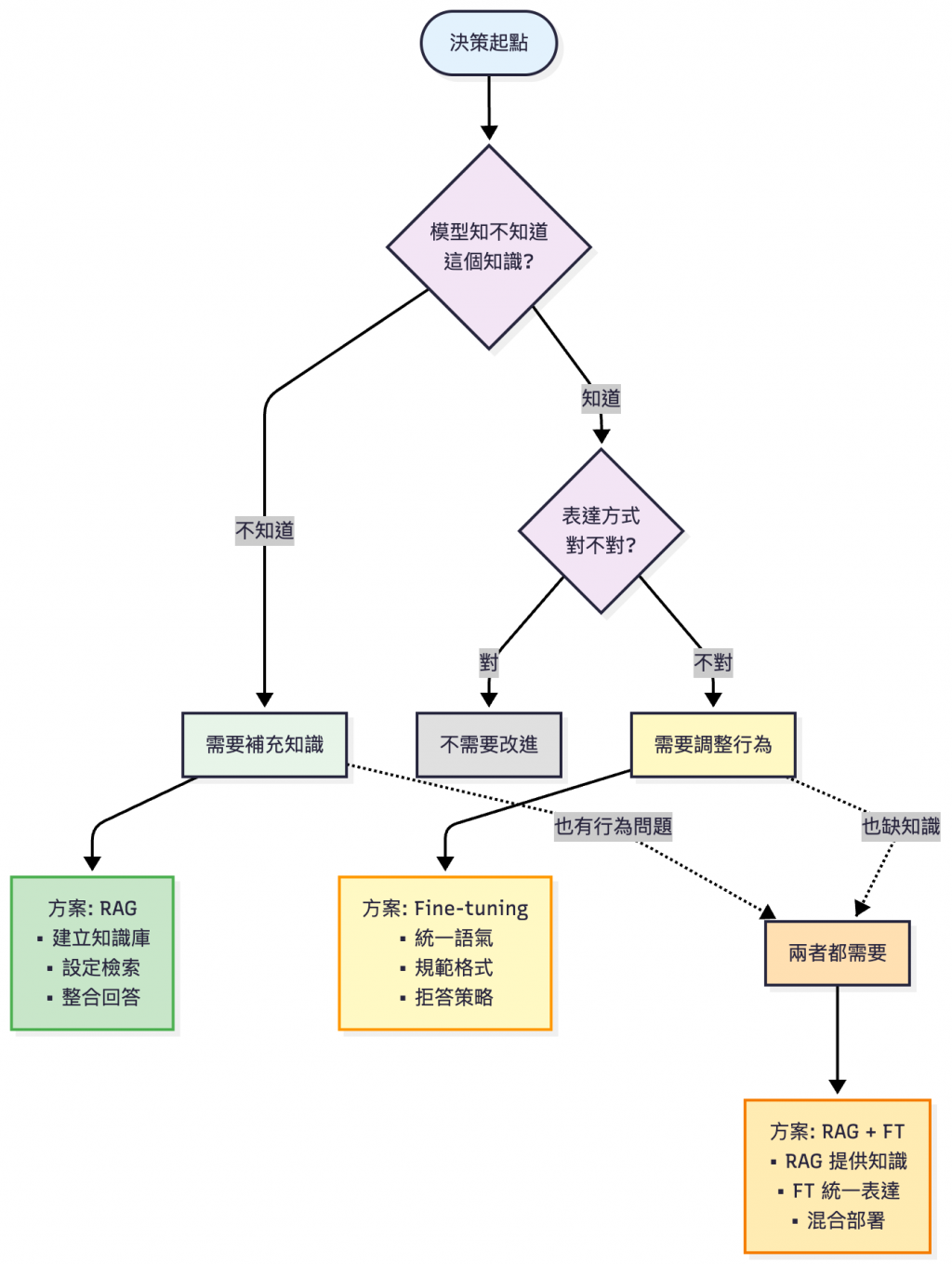
Fine-tuning 不是 RAG 的替代方案,而是解決不同問題
| 誤區 | 正確做法 | 真實案例 |
|---|---|---|
| ❌ 「我們要自己微調模型才專業」 | ✅ 先評估 RAG 是否足夠,再考慮微調 | 花 3 個月微調,最後發現 RAG 就能解決 |
| ❌ 「微調可以解決所有問題」 | ✅ Fine-tuning 是工具,資料品質才是關鍵 | 用爛資料微調,反而讓模型變差(詳見 Day33 除錯紀錄😂) |
| ❌ 「OpenAI 太貴,自建一定划算」 | ✅ 計算總體擁有成本(TCO),包含人力 | OpenAI: $3k/月 vs 自建: GPU $5k + 2 人力 |
| ❌ 「我們有 GPU 就可以做微調」 | ✅ 先確認治理能力,避免上線災難 | 微調後沒有版本管理,無法回滾 |
| ❌ 「微調一次就永久有效」 | ✅ 需要持續監控與定期微調 | 業務變化後,微調的模型過時了 |
| 特性 | RAG | Fine-tuning | 具體差異 |
|---|---|---|---|
| 主要用途 | 知識注入 | 行為調整 | - |
| 更新速度 | 即時(更新知識庫) | 慢(需重新微調) | RAG: 分鐘級 vs FT: 小時-天級 |
| 成本 | 中(檢索 + 推理) | 高(微調 + 推理) | RAG: $500-2k/月 vs FT: $3k-20k/月 |
| 維護難度 | 低 | 高 | RAG: 1 人 vs FT: 2-3 人 |
| 知識準確性 | 高(直接引用來源) | 中(可能幻覺) | RAG 可以 cite sources |
| 格式一致性 | 中 | 高 | FT 可以強制輸出格式 |
| 適合頻繁更新 | ✅ 是 | ❌ 否 | RAG 每天更新 vs FT 每月微調 |
| 適合統一風格 | ❌ 否 | ✅ 是 | FT 可以學習特定語氣 |
💡 詳細的技術實作差異請參考 Day23 - 讓 LLM 應用與時俱進:RAG 增量 × Fine-tuning 部署與治理指南
回到場景 1: 老闆問「Fine-tuning 要花多少錢?」 SRE 答「預估 1-3 千美金/月 GPU 費用 + 1 個 ML 工程師」 這個數字怎麼來的?我們來拆解。
💡 延伸閱讀:Day17 - LLM 部署策略選型:雲端 vs 本地 vs 混合架構(成本與隱私) 已詳細說明隱藏成本(電費、人力、維護),本章聚焦 Fine-tuning 方案差異。 小提醒:本文的數字都是用公開資料和經驗假設來估算,不同公司、不同雲端合約或硬體規格,實際成本可能差很多。別把這篇當成報價單,而是當作參考範例,幫助你思考決策方向。
| 維度 | OpenAI FT | 自建 GPU(地端) | 雲端 GPU |
|---|---|---|---|
| 準確度 | ⭐⭐⭐⭐⭐ 95%+ | ⭐⭐⭐⭐ 92% | ⭐⭐⭐⭐ 92% |
| 資料隱私 | ❌ 上傳雲端 | ✅ 完全本地 | ⚠️ VPC 可隔離 |
| 微調時間 | 25-45min | 15-30min | 15-60min |
| 微調成本/次 | $3 / 1M tokens(例:30M = $90) | $5–15 | $10–50 |
| 推理成本/月(30M tokens) | $2–3(20% 走 FT[註1],依 I/O 比例) | $0(已含於固定成本) | 已含於租金(按時數) |
| 基礎設施成本/月 | ✅ $0 | $369–469 | $1,060–2,950 |
| 人力成本/月 | ✅ $0(兼任) | $3,300–4,400(0.6–0.8 FTE) | $1,650–2,750(0.3–0.5 FTE) |
| 總成本/月(含人力) | $3–93(依重訓頻率) | $3,669–4,869 | $2,710–5,700 |
| 適合場景 | 快速驗證、小流量 | 法規限制、已有 IT 團隊 | 彈性擴容、中流量 |
成本說明:
[註1] 20% 的出處請參考下面 混合部署架構 了解設計理念。
| 方案 | 月成本 | Break-even | 說明 |
|---|---|---|---|
| OpenAI FT | $3–93 | - | 推理 $2–3 + 訓練 $0–90 |
| 雲端 GPU | $1.0k–3.0k | 約 11B–30.7B tokens/月 | 按實例時數計費(未含人力) |
| 地端 GPU | $369–469 | 約 3.8B–4.9B tokens/月 | 硬體 $333 + 電費 $36 |
| 方案 | 月成本 | 適用團隊 | 說明 |
|---|---|---|---|
| OpenAI FT | $3-93 | 小團隊(<10人) | 初次建置約 $93,之後每月僅推理 $2–3,若有增量 FT 則視資料量增加。 |
| 雲端 GPU | $2.7k–5.7k | 中型團隊(10–50人) | 需要 0.3–0.5 FTE |
| 地端 GPU | $3.7k–4.9k | 大型團隊(>50人) | 需要 0.6–0.8 FTE |
| 混合方案 | $2.6k–3.9k | 中型團隊 | 本地基礎 ($0.4–0.5k) + 雲端備援 ($20) + Routing ($0.05–0.1k) + 人力 ($2.2–3.3k) |
成本包含:微調、推理、硬體折舊、電費、人力(Day 17 有完整拆解)
TCO:總體擁有成本,Total Cost of Ownership
OpenAI FT 推理成本(變動):
├─ 僅 20% 流量走 FT(混合架構設計)
├─ 邊際成本:$0.48/M × 20% = $0.096/M
└─ 訓練成本另計(首次 $90,後續 6-12 個月重訓一次)
自建 GPU 成本(固定):
├─ 硬體攤提:$333/月
├─ 電費:$36/月
├─ 雜支:$0–100/月
└─ 總計:$369–469/月
Break-even(不含人力):
$369 ÷ $0.096/M ≈ 3,844M tokens/月 (3.8B)
$469 ÷ $0.096/M ≈ 4,885M tokens/月 (4.9B)
⚠️ 請注意:
- 雲端 GPU Break-even(不含人力):
$1,060 ÷ $0.096/M ≈ 11,042M tokens/月 (11B)
$2,950 ÷ $0.096/M ≈ 30,729M tokens/月 (30.7B)
- 雲端 GPU Break-even(含人力):
$2,710 ÷ $0.096/M ≈ 28,229M tokens/月 (28.2B)
$5,700 ÷ $0.096/M ≈ 59,375M tokens/月 (59.4B)
[註2]
- 邊際成本 = $0.096/M 估算:$0.48/M × 20%(僅 20% 流量走 FT);
其中 $0.48/M 基於 80% input ($0.30) + 20% output ($1.20)。若有 cached input 命中($0.15/M)則更低。- 若未來調整分流占比為 x%,可用 $0.48/M × x% 直接換算新的邊際成本;快取命中會進一步降低此值。
OpenAI FT:$3-93/月(首月含訓練,後續僅推理 $2-10)
自建 GPU:$3,669–4,869/月(含 0.6–0.8 FTE)
Break-even(含人力):
最低成本:$3,669 ÷ $0.096/M ≈ 38,219M tokens/月 (38.2B)
最高成本:$4,869 ÷ $0.096/M ≈ 50,719M tokens/月 (50.7B)
結論:
在混合架構下(20% 走 FT),自建 GPU 需要 38-51B tokens/月 才能達到 break-even。
對大多數企業而言,除非月流量 >40B tokens,否則 OpenAI FT 更划算。
⚠️ 此表僅供快速判斷,實際仍需依合約、人力與法規評估
| 月流量 | 推薦方案 | 月成本(OpenAI FT)推理(20% 走 FT)+訓練 | 月成本(自建 GPU) | 主要考量 |
|---|---|---|---|---|
| <100M | OpenAI FT | $93-102(首月$93+$2-10) | $3.7-4.9k | 首月含訓練,後續僅$2-10 |
| 100M-1B | OpenAI FT | $10-96(+首次訓練$90) | $3.7-4.9k | 省人力,隨流量線性成長 |
| 1B-10B | OpenAI FT | $96-960(+首次訓練$90) | $3.7-4.9k | 仍遠低於自建成本 |
| 10B-40B | OpenAI FT | $960-3.8k(+首次訓練$90) | $3.7-4.9k | 仍低於自建,但差距縮小 |
| >40B | 評估期/自建 | >$3.8k(+首次訓練$90) | $3.7-4.9k | 接近或超過自建成本,需評估隱私因素 |
例外情況(無論流量都要自建):
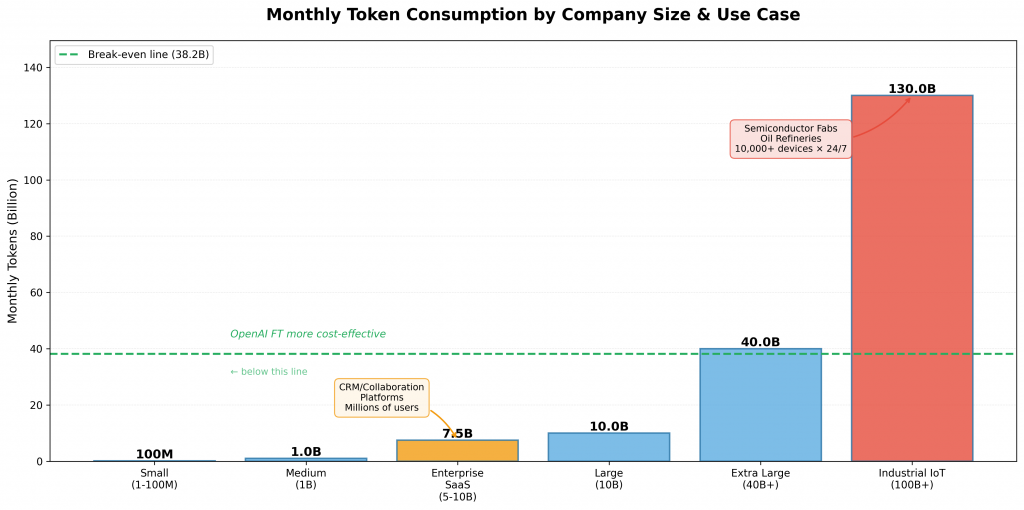
產業規模 vs Tokens 用量比較
本文開頭的「SRE 預估 1–3 千美金/月 GPU 費用 + 1 位 ML 工程師」指的是 自建或雲端 GPU 的情境,因此成本會落在機器與人力上。如果使用 OpenAI FT API,實際費用其實便宜很多:
💡 不是為做而做,先驗證需求再選方案。
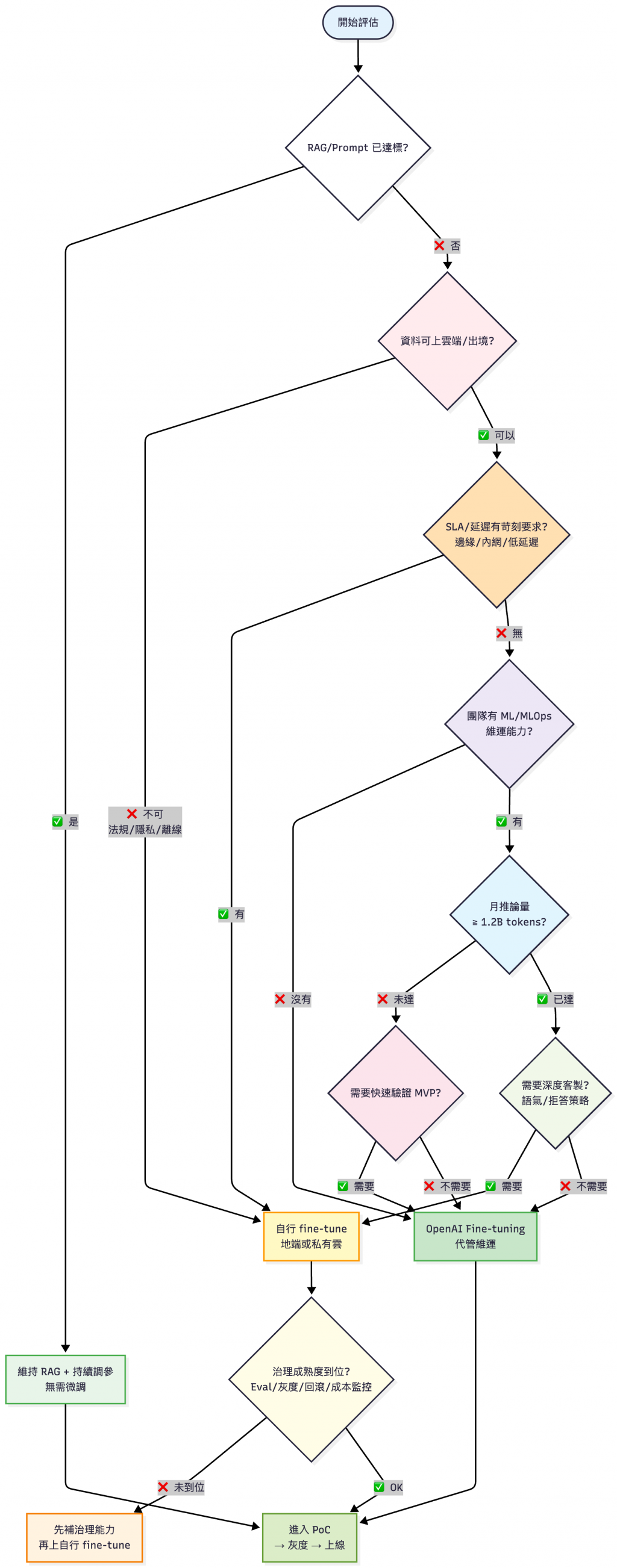
真實世界必須要依照需求決定要採用哪種方案
說明:
- 流量門檻: 參考前面 break-even 分析(含人力約 1.2–1.6B tokens/月)
- 治理成熟度: 包含 Eval、灰度、回滾、成本監控(見下方檢查清單)
| 能力 | 具體要求(範例參考) | 檢查方式 | 必備度 |
|---|---|---|---|
| Eval | 測試集 ≥100 samples+ 自動化品質指標追蹤 | 是否有自動化評測流程? | 必備 |
| 回滾 | 監控 + 自動回滾MTTR ≤5min | 能否在 staging 演練回滾? | 必備 |
| 版本 | Model Registry+ 追溯性(誰訓練/何時/用什麼資料) | 是否能追溯線上模型來源? | 必備 |
| 隱私/安全 | 資料合規審計GDPR/HIPAA/SOC2 | 是否通過合規檢查?或確認可內網部署? | 必備 |
| 灰度 | Canary/Blue-Green2–5 階段流量切換 | 能否做到 10% → 50% → 100% 切換? | 應備 |
| 觀測性 | Hallucination rate+ P95 延遲 + 成本監控 | 儀表板是否涵蓋這三項? | 應備 |
| 成本 | 到請求/模型/租戶粒度的訓練+推理成本追蹤 | 能否回答「上週這個模型花了多少錢」? | 應備 |
| 人力 | ≥0.3 FTE 專職維運+ Runbook | 是否有明確 Owner 與待命機制?Runbook 是否包含常見故障? | 應備 |
| 資料治理 | PII 遮罩/洗除+ 資料刪除政策 | GDPR 刪除請求能執行嗎? | 加分 |
| 紅隊測試 | Prompt injection+ 資料外洩演練 | 是否做過攻擊演練? | 加分 |
| 自動化 | Pipeline as Code訓練→評測→部署全流程可重現 | 能否一鍵重現訓練流程? | 加分 |
在選擇自建 Fine-tuning 系統前,可以考慮用此清單評估團隊準備度
⚠️ 雲端 GPU 僅解決硬體維運問題,但治理清單要求完全相同。若必備項未達成,即使租 GPU 成本高昂,風險依然存在。
| 場景 | 佔比 | 方案 | 決策條件 | 原因 |
|---|---|---|---|---|
| 一般查詢 | 50% | RAG only | • 知識更新頻繁• 無特殊格式要求 | 多數需求是「查詢最新知識」,RAG足夠且成本最低。 |
| 一致語氣 / 固定格式 | 20% | RAG + OpenAI FT | • 需要品牌語氣• 需要結構化輸出(JSON/XML) | 當需要品牌風格、精準輸出格式時,才引入FT。 |
| 敏感/合規資料 | 20% | RAG + 自建 LoRA/FT | • 涉及隱私/機密• 法規要求內網部署 | 涉及隱私或法規 → 離線推理。 |
| 簡單 FAQ | 10% | 規則 + RAG fallback | • 問題重複率 >80%• 答案固定且少量(<100條) | 高重複率問題直接用規則處理,幾乎零成本。 |
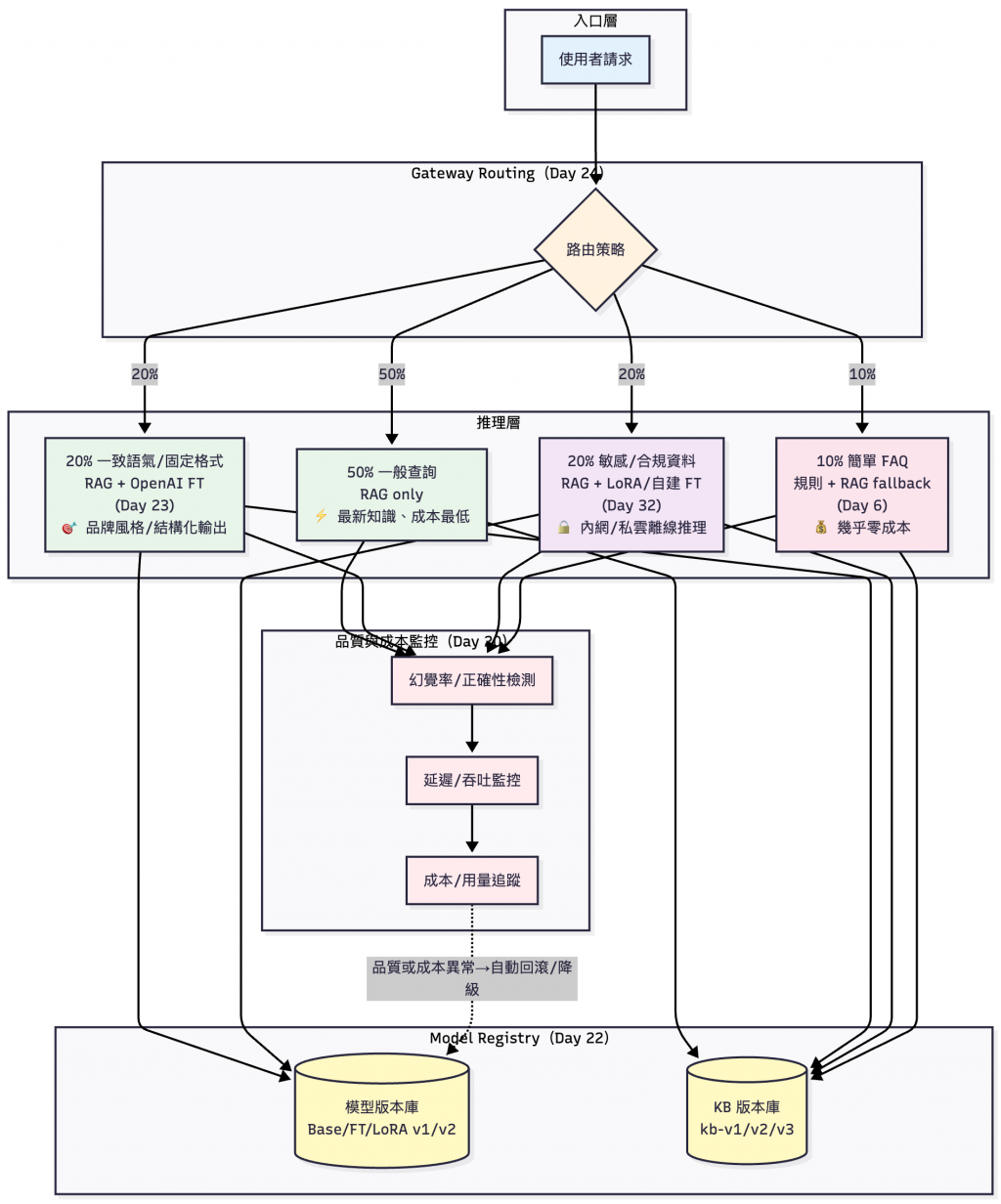
實務部署流程參考(不同企業比例會有落差,這裡提供的是常見分佈,整理自參考文章)
💡 路由實作以及現成工具參考詳見:Day24 - LLM 應用分流:用任務分類做到省錢可靠
💡 回到場景 2: SRE 設定了三個自動回滾條件
- P95 延遲 >3s(持續 15 分鐘)
- 錯誤率 >0.5%(持續 10 分鐘)
- 品質下降到 <85%
雖然情境裡的 SRE 最後不需要真的採用 Fine-tuning,但是如果真的要做的話,這些閾值怎麼設?
| 指標類別 | 指標名稱 | Naming Label | 如何設定閾值 | 觸發動作 |
|---|---|---|---|---|
| 品質 | 幻覺率 | sft_quality_hallucination_rate |
1️⃣ 跑 1 週收集 baseline2️⃣ 取 p95 值3️⃣ 閾值 = baseline × 1.5 | 自動回滾 |
| 相似度 | sft_quality_similarity_score |
1️⃣ 用測試集計算當前值2️⃣ 閾值 = 當前值 × 0.9 | 自動回滾 | |
| 效能 | P95 延遲 | sft_perf_latency_p95_ms |
1️⃣ 壓測找到容量上限2️⃣ 閾值 = 上限 × 0.7 | 降低流量 |
| P99 延遲 | sft_perf_latency_p99_ms |
1️⃣ 參考 SLA(如:<2s)2️⃣ 閾值 = SLA - 200ms(緩衝) | 自動回滾 | |
| 成本 | 單次推論成本 | sft_cost_inference_per_request_usd |
1️⃣ 計算月預算2️⃣ 閾值 = 預算 ÷ 預期流量 × 1.2 | 追蹤 |
| 可用性 | 成功率 | sft_availability_success_rate |
業界標準:• 內部工具:95%• 一般服務:99%• 關鍵服務:99.9% | 自動回滾 |
典型場景範例(參考值,需根據實際環境調整):
| 場景 | 幻覺率閾值 | P95 延遲閾值 | 成功率目標 |
|---|---|---|---|
| 客服 FAQ Bot | <5% | <500ms | 99% |
| 金融問答系統 | <1% | <300ms | 99.9% |
| 內部知識庫 | <10% | <1000ms | 95% |
💡 閾值設定原則(參考 Google SRE Book: SLO):
- 先跑 1-2 週收集 baseline(真實流量的正常水平)
- 根據業務需求設定 目標值(如:P95 延遲 <500ms)
- 告警閾值 = 目標值 × 容忍係數(如:目標 × 1.2)
- 持續調整:每月檢視誤報率,調整閾值
💡 監控實作細節參考:
💡 回到場景 3: 凌晨幻覺率從 3% 飆到 8%,這就是「資料 Drift」風險。如何預防以及快速應對?
| 風險類型 | 典型症狀 | 快速應對 | 延伸閱讀 |
|---|---|---|---|
| 災難性遺忘 | 相似度暴跌(78%→10%) | • 降低 learning rate(0.0001→0.00005)• 加入舊樣本 Replay• 設定 Early Stopping | Day32/33 - LoRA 微調與踩坑紀錄 |
| 模型洩漏 | Adapter 權重被竊取 | • 加密存儲(AES-256)• 訪問控制(RBAC)• 審計日誌 | 參考文章:TensorShield 論文 |
| 版本混亂 | 無法回滾A/B 測試失效 | • Model Registry• Git LFS 版本追蹤• 標籤化部署(kb-v1.2.3) | Day22 - Model Registry |
| 資料 Drift | 新資料格式錯誤 → embedding 失真 → 召回率下降 | • Schema 驗證• CI/CD 自動檢查• 漂移偵測(Cosine Similarity) | Day13 - Data Drift 偵測Day34 - 部署風險案例 |
| 成本失控 | GPU 閒置訓練過頻 | • 預算告警(AWS Budget)• 定期 ROI 檢討• Break-even 分析 | Day17 - 部署策略選型 |
| 快取失效 | 更新後命中率驟降 | • 漸進式快取替換• 版本化快取 Key• 監控命中率變化 | Day21 - LLM 應用快取實戰 |
| 風險 | 機率 | 影響 | 優先級 | 實際損失估算 |
|---|---|---|---|---|
| 災難性遺忘 | 🔴 高 | 🔴 高 | 🔴 P0 | 相似度驟降(92% → 10%)用戶體感品質明顯下滑出處:Day33 實證 |
| 版本混亂 | 🟠 高 | 🟠 中 | 🟠 P1 | MTTR 從 3min 延長至 30min–2h無法快速回滾範例值,依組織流程而異 |
| 資料 Drift | 🟡 中 | 🟠 中 | 🟡 P2 | 召回率下降 10–20%,客訴增加出處:Day13 方法論,需線上 A/B 實測 |
| 模型洩漏 | 🟢 低 | 🔴 高 | 🟠 P1 | 商業機密外洩,法律風險機率低但後果嚴重控管:加密 / RBAC / 審計 |
| 快取失效 | 🟡 中 | 🟡 中 | 🟡 P2 | 成本上升 30–60%(命中率驟降)延遲惡化出處:Day21 成本模型估算 |
| 成本失控 | 🟢 低 | 🟡 中 | 🟢 P3 | GPU 閒置率 ~40%浪費預算範例值,需以實際使用率 / 租賃費率估算 |
從實作(Day 32)→ 踩坑(Day 33)→ 部署評估(Day 34),完整涵蓋 LoRA 微調的完整生命週期。
SRE 的核心價值:
上線前必檢項目:
SRE 的價值:不只是「把服務跑起來」,而是在技術可行性與商業價值間找到平衡點。企業 QA Bot 並不一定要做 Fine-tuning,先用現成工具驗證想法,確認必要性後再投資才是穩健做法。

