昨天(Day22)我們談到 Registry(模型/知識庫版本管理),確保任何時候線上跑的都是唯一正確的版本,並且升級、回滾都有紀錄可查。然而,現實世界的知識每天都在變:政策更新、產品上新、流程改版……
即使有 Registry,如果內容不更新,品質還是會走下坡。
所以今天我們要談的是 RAG 增量、微調 (Fine-tuning) 與 持續學習 (Continual Learning):如何讓系統隨著資料更新而持續進步。本文會附可實作的兩個最小範例:
📌 建議先讀
Day13 - 資料漂移 (Data Drift) 與知識更新與Day22 - 版本治理(Versioning)— 模型與知識庫的 Registry 與發布管理,這篇相當於「偵測變化 → 具體更新」的實作續集。
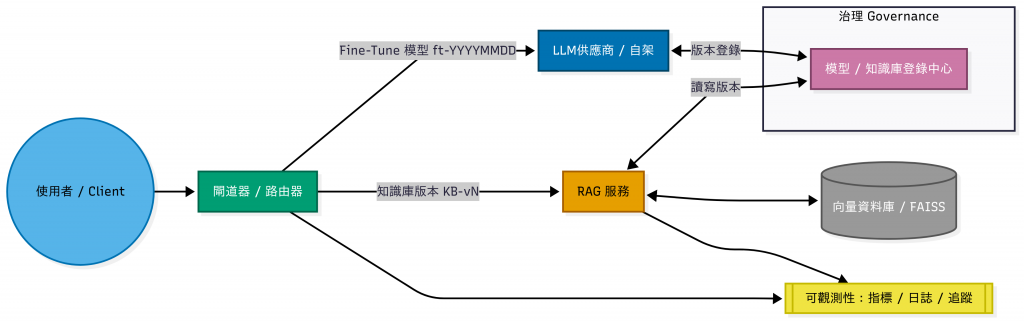
Registry + RAG + FT系統架構圖
如果沒有更新機制,最終會導致:
看到「微調」或「持續學習」,很多人會以為一定要有 GPU、要自己把模型拉下來重新訓練。
其實不一定,以下就兩種類的使用者角度分析:
API 使用者
自建 / 開源模型使用者
微調能為企業帶來以下三大價值:
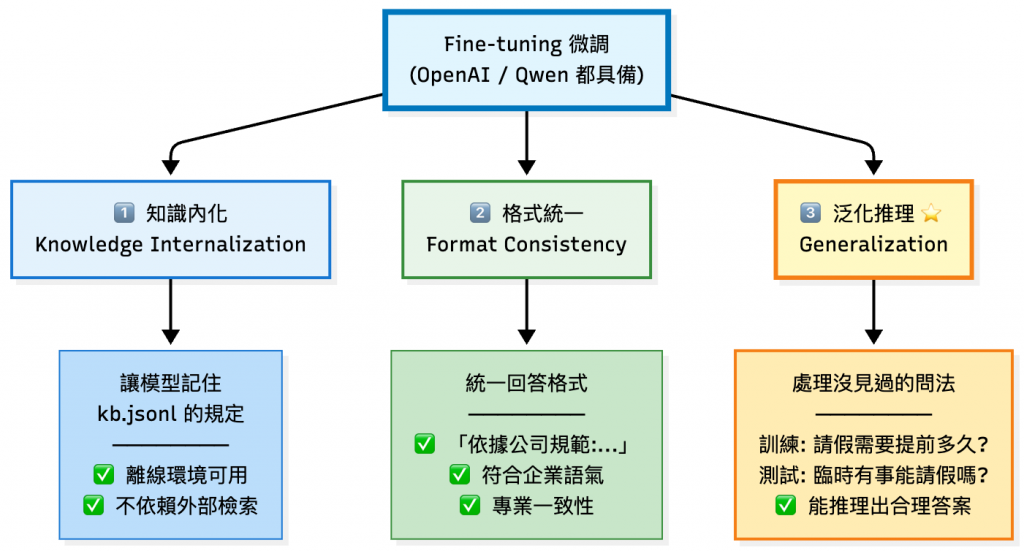
💡 RAG 解決「知識時效性」,微調解決「能力與風格」,兩者互補而非替代關係。
不論你用 API 還是自建模型,都需要一個能「隨資料更新持續演進」的策略。
| 方法 | 概念 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|---|
| Fine-tuning(微調) | 針對特定任務或領域進行模型參數調整 | 效果顯著、一次吸收大量新知 | 成本高、訓練流程長、需 GPU 或 API 費用 | 知識更新快、資料量大的領域(金融、醫療、法規) |
| Continual Learning(持續學習) | 以小批量、週期化更新,邊學邊進化 | 成本低、迭代快、能隨時吸收新知 | 需避免「災難性遺忘」、資料管理更複雜 | 即時性需求高(客服、推薦系統) |
| RAG 更新 | 不動模型,只更新向量庫補充最新知識 | 快速生效、成本最低、📉 風險低 | 生成能力不會提升、需處理快取失效與文件版本一致性 | 文件變動頻繁、以檢索為主的問答系統 |
實務上常採 混合策略:
短期用 RAG 補洞,長期安排 微調 或 持續學習,同步提升風格與結構化能力。
📚 根據 The Future of Continual Learning in the Era of Foundation Models: Three Key Directions 指出:Foundation Models 的持續學習主要有三大方向:持續預訓練、持續微調與模組化組合,可以呼應表格中的「微調/持續學習/RAG」策略。
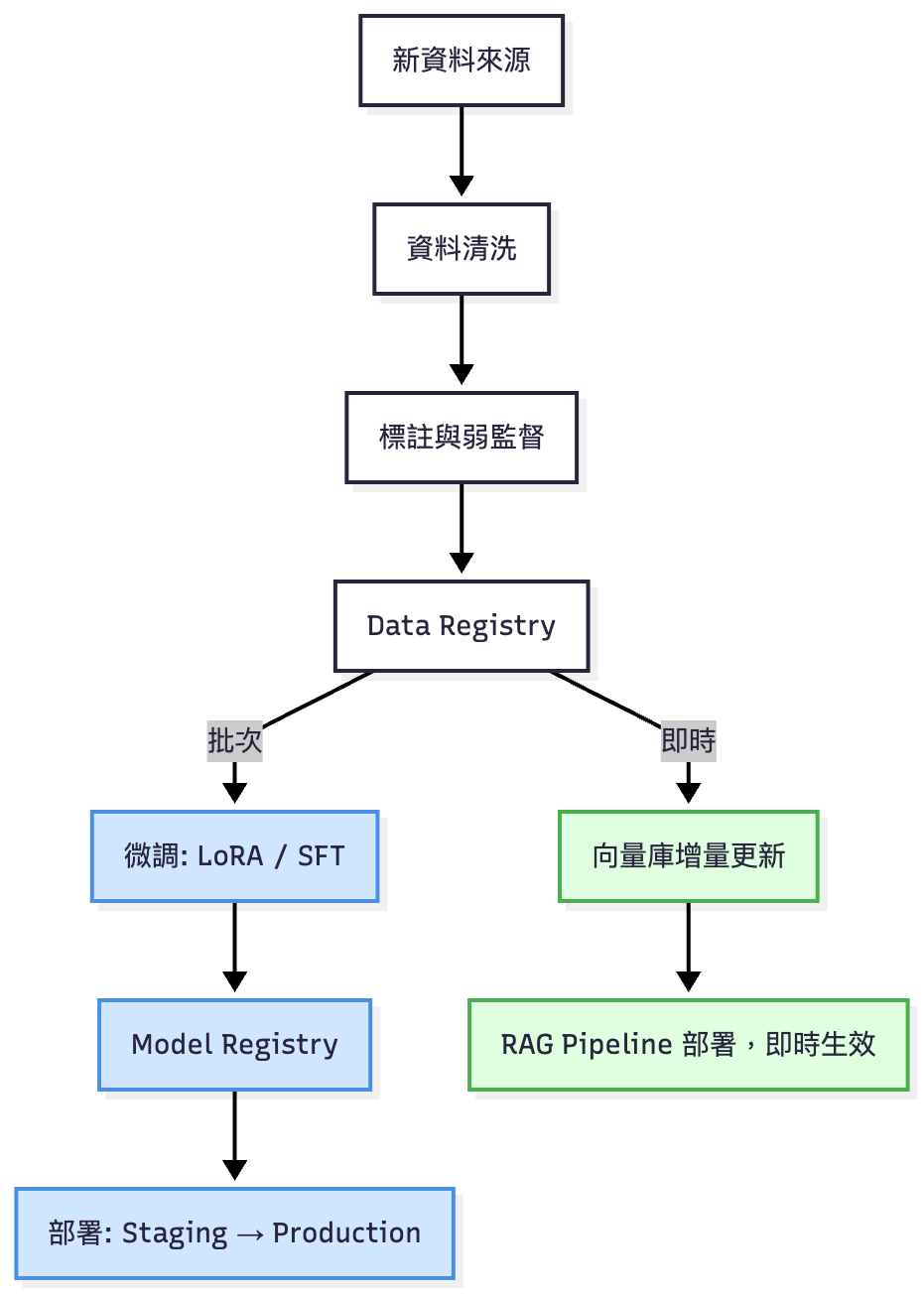
微調/即時更新對比圖
💡 在 Day14 我們曾經用 Prefect / Dagster 打造過自動化 Pipeline,資料側的更新流程同樣可以透過排程系統週期化執行,或設計 Trigger 自動觸發。
因為篇幅關係,完整可執行專案一樣會放在 GitHub,完整的細節請看
README.md。
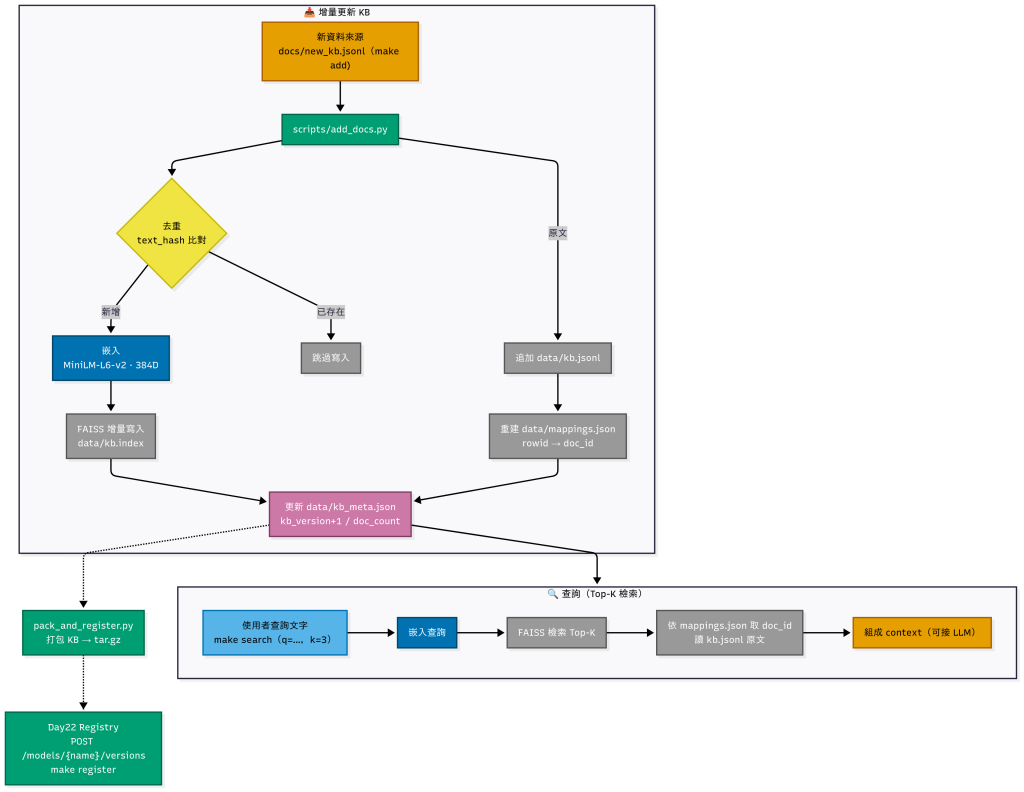
使用端在回答時:先檢索 kb.index → 取回 kb.jsonl 原文 → 組合成上下文 → 再讓 LLM 生成,這就是 RAG (Retrieval-Augmented Generation) 的步驟。
優點:
限制:
[註1] 提示設計 (Prompt Engineering):可以重溫 Day15 的文章。
[註2] 少量微調 (LoRA / SFT):進階篇補充
建立初始知識庫檔案
data/kb.jsonl:知識庫主檔,預設建立為空檔。之後所有文件都會新增到這裡。建立對照表
data/mappings.json:儲存向量索引中每個 rowid 對應的文件 ID,避免檢索結果對不到原文。初始化時填入空的 {"rowid_to_doc_id":{}}。建立知識庫的基本中繼資料
data/kb_meta.json:紀錄知識庫的版本號、文件數、embedding 維度、使用的模型名稱等。初始化時先填一個基礎的樣板: {
"kb_version": 0,
"doc_count": 0,
"dim": 384,
"model": "sentence-transformers/all-MiniLM-L6-v2"
}
執行結果:
❯ make init
mkdir -p data scripts
[ -f data/kb.jsonl ] || : > data/kb.jsonl
[ -f data/mappings.json ] || printf '%s\n' '{"rowid_to_doc_id":{}}' > data/mappings.json
[ -f data/kb_meta.json ] || printf '%s\n' '{"kb_version":0,"doc_count":0,"dim":384,"model":"sentence-transformers/all-MiniLM-L6-v2"}' > data/kb_meta.json
✅ 初始化完成
這邊我在 GitHub Repo 已經有建立範例文件(
docs/examples_10.jsonl)了,可以直接拿來使用。
這個步驟就是把新的知識文件加進 知識庫 (KB),背後會做這幾件事:
去重比對
嵌入向量化
sentence-transformers/all-MiniLM-L6-v2 把文字轉成 384 維向量。更新索引
kb.index),讓新資料能被快速檢索到。紀錄原文與中繼資料
kb.jsonl。mappings.json(行號 → doc_id 對應表)、kb_meta.json(KB 版本、文件數量等)。執行結果:
❯ make add
python scripts/add_docs.py --jsonl docs/examples_10.jsonl
🆕 建立新索引 ...
🧠 載入嵌入模型:sentence-transformers/all-MiniLM-L6-v2
🔢 向量化 10 筆文本 ...
Batches: 100%|███████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.20it/s]
📌 寫入索引 ...
📝 追加原文 ...
🔗 更新 rowid 對應 ...
🧾 更新 KB meta ...
✅ 完成:新增 10 筆;跳過重複 0 筆;kb_version=1;總筆數=10
之後每次跑 make add 或 python scripts/add_docs.py --jsonl xxx.jsonl,系統會 在原有的 KB 上疊加新資料,而不是整個覆蓋重來。之後新增或是要修改條目時,只要修改 docs/examples_10.jsonl 即可,這樣的方式謂之「增量新增(Incremental Update)」。
比方說,我再加上五條規則:
{"text": "假勤規範:員工請假需於系統提前填寫申請,事後補登需主管同意。"}
{"text": "會議室預約:每次單位最多可預訂 2 間會議室,使用完畢請及時取消未使用時段。"}
{"text": "檔案保存:重要專案文件需存放於公司雲端,不得僅存在個人電腦。"}
{"text": "加班申請:平日加班需提前申請,假日加班需部門主管與人資雙重核准。"}
{"text": "資安培訓:所有員工需每年完成一次線上資安測驗,未完成將停用公司帳號。"}
再執行一次 make add:
❯ make add
python scripts/add_docs.py --jsonl docs/examples_10.jsonl
🗂️ 載入既有索引 ...
🧠 載入嵌入模型:sentence-transformers/all-MiniLM-L6-v2
🔢 向量化 5 筆文本 ...
Batches: 100%|███████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.29it/s]
📌 寫入索引 ...
📝 追加原文 ...
🔗 更新 rowid 對應 ...
🧾 更新 KB meta ...
✅ 完成:新增 5 筆;跳過重複 10 筆;kb_version=2;總筆數=15
這個步驟其實是 驗證 KB(知識庫)有沒有建好、能不能被檢索到:
這步就是 Smoke Test(冒煙測試),保證 RAG pipeline 的「檢索」環節正常。
執行結果:
❯ make search q="請假規定有哪些?" k=3
python scripts/search.py "請假規定有哪些?" --k 3
🔎 Query: 請假規定有哪些?
[1] sim=0.6197 | doc_51f8beab | 假勤規範:員工請假需於系統提前填寫申請,事後補登需主管同意。
[2] sim=0.6114 | doc_e761823c | 加班申請:平日加班需提前申請,假日加班需部門主管與人資雙重核准。
[3] sim=0.5681 | doc_838f69ae | 出差報銷:發票需於 30 天內上傳;逾期需直屬主管簽核理由。
---
🧩 Context for LLM:
假勤規範:員工請假需於系統提前填寫申請,事後補登需主管同意。
加班申請:平日加班需提前申請,假日加班需部門主管與人資雙重核准。
出差報銷:發票需於 30 天內上傳;逾期需直屬主管簽核理由。
記得先檢查有沒有
faq-bot這個 model
# 看該 model 是否已有版本
curl -s http://localhost:8000/models/faq-bot/versions | jq
# 有回傳陣列(可能是空陣列 [])→ model 存在
# 回 404/錯誤 → model 可能不存在
# 建立 model - `faq-bot`
curl -sX POST http://localhost:8000/models \
-H 'Content-Type: application/json' \
-d '{"name":"faq-bot","description":"KB-backed FAQ bot"}' | jq
執行結果:
# 僅打包 KB ,不送出註冊
❯ make pack
python scripts/pack_and_register.py --pack-only --name faq-bot --registry http://localhost:8000
✅ 已打包:data/kb-v1757915827.tar.gz
checksum: sha256:01b016e61f3a9862939e42fed5f03c5799f79da6fdbe4dfa4f3ca54dcba1002f
artifact_url: file:///Users/hazel/Documents/github/2025-ironman-llmops-demo/day23_incremental_update/data/kb-v1757915827.tar.gz
# 打包 KB + 註冊(呼叫 Day22 Registry API)
# 註冊成功時,你應該會看到 Registry 回傳的版本物件(`...-kb` 版本號)。
❯ make register
python scripts/pack_and_register.py --name faq-bot --registry http://localhost:8000 --auto-unique
✅ 已打包:data/kb-v1757915843.tar.gz
checksum: sha256:853f5d982596cc49cdaeb00592a0cfe4d8d823ed1f6ee3557c08539c6b7e59fa
artifact_url: file:///Users/hazel/Documents/github/2025-ironman-llmops-demo/day23_incremental_update/data/kb-v1757915843.tar.gz
{
"id": 2,
"version": "2-kb+1757915843",
"stage": "None",
"artifact_url": "file:///Users/hazel/Documents/github/2025-ironman-llmops-demo/day23_incremental_update/data/kb-v1757915843.tar.gz",
"tags": [
"kb",
"rag",
"incremental"
],
"meta": {
"artifact_type": "KnowledgeBase",
"embedding_model": "sentence-transformers/all-MiniLM-L6-v2",
"dim": 384,
"doc_count": 15,
"kb_version": 2,
"index_type": "faiss.IndexFlatL2",
"hash": "sha256:853f5d982596cc49cdaeb00592a0cfe4d8d823ed1f6ee3557c08539c6b7e59fa"
},
"created_at": "2025-09-15T05:57:23.580040",
"updated_at": "2025-09-15T05:57:23.580046"
}
打包 (pack):把目前的 KB(含 kb.jsonl、索引檔 kb.index、mappings.json、kb_meta.json)壓縮成一個檔案,完整保存 當下的 KB 狀態(方便回溯/切換版本),也方便之後傳遞給其他系統或是同事。
data/kb-v1757860693.tar.gz
註冊 (register) : 把剛剛打包好的檔案登錄 Registry 伺服器,並且記錄是哪個 model(例如 faq-bot)、 這個版本對應的 KB 檔案路徑(artifact_url)、附帶的 metadata(例如 embedding 模型、維度、文件數)。
後續如需切換 Stage(Staging/Production)、搭配 Gateway 讀取「當前 Prod KB 版本」等,可延用 Day22 Registry 的 API 與流程。
因為篇幅關係,完整可執行專案一樣會放在 GitHub,完整的細節請看
README.md。
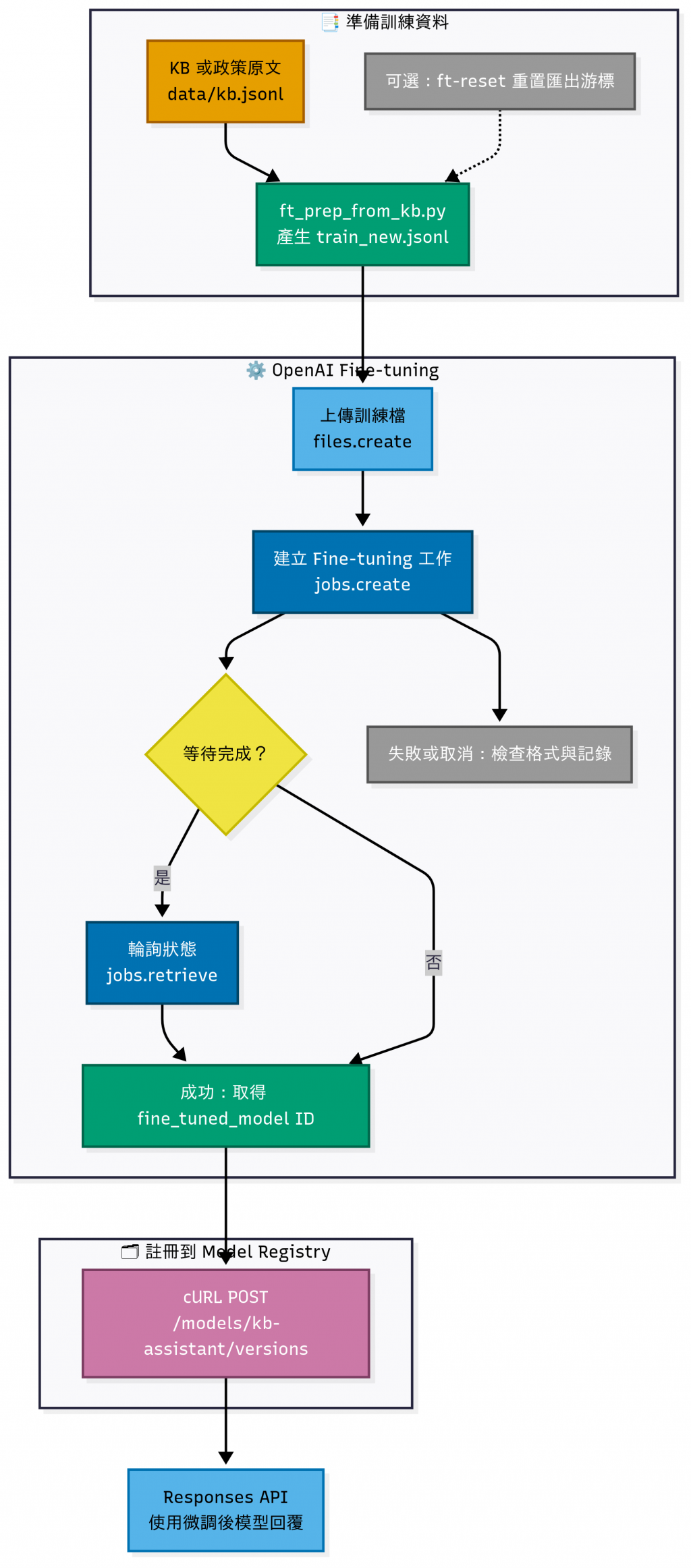
如果你希望模型 「直接學會 KB 的內容」,而不是每次查詢都要透過 RAG;
或者有些場景需要模型 「一開口就具備企業專屬的語氣」,並且輸出的答案能保持 專業一致 ,
這時候就可以考慮使用 Fine-tuning。
常見用途:
⚠️ 不過要注意:Fine-tuning 會花錢,也不是萬靈丹。Fine-tuning 是「把知識寫進模型」,如果 KB 常常更新,還是建議混合搭配 RAG,比較彈性。
❯ make ft-export
mkdir -p scenarios/open_ai/
python scripts/ft_prep_from_kb.py --out scenarios/open_ai/train_new.jsonl
✅ 已輸出 29 筆(15 條文 × 每條最多 2 問句)→ scenarios/open_ai/train_new.jsonl
KB 總筆數 15;原游標 0 → 15(force_all=False, since=None)
❯ make ft-run
mkdir -p scenarios/open_ai/
python scripts/ft_prep_from_kb.py --out scenarios/open_ai/train_new.jsonl
✅ 無新增:KB 目前 15 筆,已匯出至 15。
python scripts/openai_finetune.py run --model gpt-4o-mini-2024-07-18 --train_jsonl scenarios/open_ai/train_new.jsonl
{
"job_id": "ftjob-r36EN0l762lwiqpQagdwfkfp",
"status": "validating_files",
"model": "gpt-4o-mini-2024-07-18",
"training_file": "file-G3L6MjXqwzHjFsUKCTAEBn"
}
{
"job_id": "ftjob-r36EN0l762lwiqpQagdwfkfp",
"status": "succeeded",
"fine_tuned_model": "ft:gpt-4o-mini-2024-07-18:personal::CFxCOwhl" # <--- 最後會得到一個新的 `fine_tuned_model` ID,可以直接拿來呼叫
}
make ft-export 會生成 訓練資料集,格式如下:
{"messages": [{"role": "system", "content": "請以『溫和、專業、簡潔』的客服口吻回答,並用三段式條列 1–3 點重點。"}, {"role": "user", "content": "想請問:2025 年 VPN 設定流程:步驟 1"}, {"role": "assistant", "content": "您好,感謝您的提問,以下為重點整理:\n\n1) 2025 年 VPN 設定流程:步驟 1 下載新版客戶端\n2) 步驟 2 使用 SSO 登入\n\n後續若需要協助,請隨時與我們聯絡。\n(內部資料更新日:2025-09-15)"}]}
{"messages": [{"role": "system", "content": "請以『溫和、專業、簡潔』的客服口吻回答,並用三段式條列 1–3 點重點。"}, {"role": "user", "content": "可以提供2025 年 VPN 設定流程:步驟 1的流程/做法嗎"}, {"role": "assistant", "content": "您好,感謝您的提問,以下為重點整理:\n\n1) 2025 年 VPN 設定流程:步驟 1 下載新版客戶端\n2) 步驟 2 使用 SSO 登入\n\n後續若需要協助,請隨時與我們聯絡。\n(內部資料更新日:2025-09-15)"}]}
...
...
make ft-run 會呼叫 OpenAI Fine-tuning API,把我們準備好的訓練資料集送上去,
並以 gpt-4o-mini-2024-07-18 為基底,產生一個「專屬於我們」的微調模型;
這個模型除了原本的能力外,還會學會我們指定的語氣與 FAQ 知識。
這個過程花費的時間,會依照 排隊任務的多寡 與 資料集大小 而有所不同,
可能從幾分鐘到幾十分鐘不等。
我們可以:
make ft-status JOB=ftjob_xxx 查詢狀態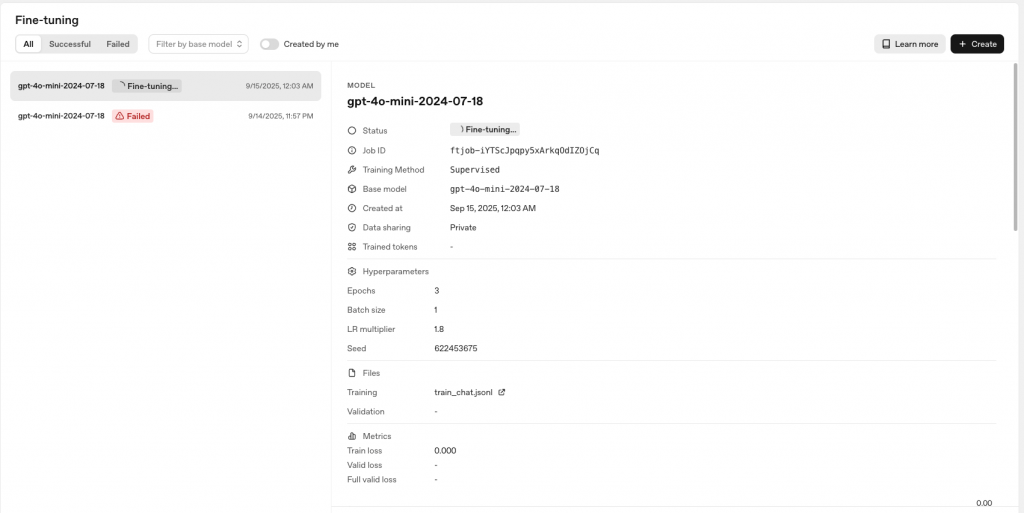
訓練完成後畫面會顯示 fine_tuned_model ID,可以直接拿來呼叫了。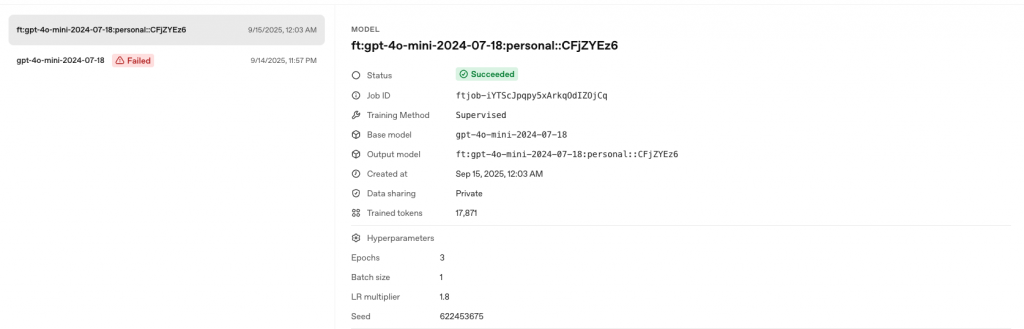
缺點很明顯,就是沒有照著訓練問題集就不會回答正確答案,但是語氣和回答大致上符合我們資料集的內容。
執行結果:
❯ make ft-test
👤: 假勤規範有哪些重點?
🤖: 假勤規範的重點如下:
1. 事前申請:員工需於系統填寫請假單並獲主管同意後方可休假。
2. 事後補登:未事前申請者需於事後補登請假單並附上主管同意理由。
後續若需要協助,請隨時與人資單位聯絡。
(資料更新日:2025-09-15)
❯ make ft-test
👤: 請假有哪些規範?
🤖: 請假規範通常會依公司或組織的政策而有所不同。一般而言,請假流程可能包括:
1. **事前申請**:大多數公司要求員工於系統中填寫請假單並獲得主管核准後方可休假。
2. **病假證明**:連續病假超過三天需提供醫師證明。
建議您查閱內部資料或向人資單位確認最新規範。
從上面的測試可以看到一個有趣的現象:
| 問題類型 | 測試問題範例 | 模型回答 | 觀察 |
|---|---|---|---|
| 訓練資料中有的問題 | 假勤規範有哪些重點? | 列出事前申請、事後補登等規範 | ✅ 答案準確、語氣專業 |
| 訓練資料中沒有的問題 | 請假有哪些規範? | 說明事前申請流程、病假證明要求 | ✅ 保持格式與語氣一致性 |
這正是 Fine-tuning 的核心價值:泛化能力
Fine-tuning 不是「背答案」,而是讓模型學會:
💡 為什麼只需要 29 筆訓練資料就有效?
OpenAI的gpt-4o-mini基座模型已具備強大的語言理解能力,Fine-tuning只需要:
- 告訴模型「你的語氣應該是什麼」(少量範例即可)
- 提供「領域知識的典型問答模式」(建立推理模板)
- 不需要窮舉所有可能的問題(模型會類推)
# 把訓練好的模型註冊到 day22 的 registry
❯ MODEL_ID='ft:gpt-4o-mini-2024-07-18:personal::CFxCOwhl'
❯ curl -sX POST http://localhost:8000/models/kb-assistant/versions \
-H 'Content-Type: application/json' \
-d "{
\"version\": \"ft-2025-09-15\",
\"artifact_url\": \"openai://models/${MODEL_ID}\",
\"tags\": [\"kb\", \"ft\", \"openai\"],
\"meta\": {
\"artifact_type\": \"OpenAIFineTunedModel\",
\"provider\": \"openai\",
\"base_model\": \"gpt-4o-mini-2024-07-18\"
}
}" | jq
{
"id": 3,
"version": "ft-2025-09-15",
"stage": "None",
"artifact_url": "openai://models/ft:gpt-4o-mini-2024-07-18:personal::CFxCOwhl",
"tags": [
"kb",
"ft",
"openai"
],
"meta": {
"artifact_type": "OpenAIFineTunedModel",
"provider": "openai",
"base_model": "gpt-4o-mini-2024-07-18"
},
"created_at": "2025-09-15T07:28:40.637883",
"updated_at": "2025-09-15T07:28:40.637885"
}
# 確認有這個模型
❯ curl -s http://localhost:8000/models/kb-assistant/versions | jq
[
{
"id": 3,
"version": "ft-2025-09-15",
"stage": "None",
"artifact_url": "openai://models/ft:gpt-4o-mini-2024-07-18:personal::CFxCOwhl",
"tags": [
"kb",
"ft",
"openai"
],
"meta": {
"artifact_type": "OpenAIFineTunedModel",
"provider": "openai",
"base_model": "gpt-4o-mini-2024-07-18"
},
"created_at": "2025-09-15T07:28:40.637883",
"updated_at": "2025-09-15T07:28:40.637885"
}
]
status: failed)時不會計費;通過驗證後開始訓練才計費。[註1]mkdir -p scenarios/open_ai/
python scripts/ft_prep_from_kb.py --out scenarios/open_ai/train_new.jsonl
✅ 無新增:KB 目前 31 筆,已匯出至 31。
python scripts/openai_finetune.py run --model gpt-4o-mini-2024-07-18 --train_jsonl scenarios/open_ai/train_new.jsonl
{
"job_id": "ftjob-YicTUtZyYvqVmDXZbQXcc8gg",
"status": "validating_files",
"model": "gpt-4o-mini-2024-07-18",
"training_file": "file-6oBKT9h1dNyHYjgfLaAiKY"
}
{
"job_id": "ftjob-YicTUtZyYvqVmDXZbQXcc8gg",
"status": "failed",
"fine_tuned_model": null
}
OpenAI 官方文檔 - Billing guide for the Reinforcement Fine Tuning API
⚠️ 本文中的 fine-tuning Model ID 與 Job ID 僅作示範用途,如果要寫企業部落文或是真實經驗分享的話建議遮蔽。不同於
API Key,這些 ID 無法單獨被濫用,但公開分享仍可能讓他人側錄你在進行的專案或時間點。若包含公司內部數據或敏感模型,請務必避免在公開場合完整揭露。
⚠️ 讀前提醒(給不自行建模、只用雲端 API 的讀者)
這裡示範的是 LoRA 監督式微調(SFT),主要用來學會企業語氣、回覆格式與內部規範。如果你平常只用雲端模型(OpenAI/Anthropic/Cohere/Bedrock 等),不需要自己訓練 ;直接上傳 instruction-tuning 格式資料到官方的 Fine-tuning / Custom Model 服務即可,效果與 LoRA 類似。建議把這一節當成「了解本地訓練的可能性」來看,真的要離線自訓時,再參照 Day32 - 進階篇:Macbook Air M3 本機 LoRA 微調 Qwen2.5(30 分鐘,相似度 92%) 的完整流程操作。
雖然雲端 Fine-tuning API 很方便,但在以下情境中,自建 LoRA 訓練更合適:
| 情境 | 原因 | 範例 |
|---|---|---|
| 資料合規要求 | 不能將敏感資料上傳到雲端 | 醫療記錄、金融交易、內部機密 |
| 離線環境 | 無法連接外部 API | 軍事、政府、內網系統 |
| 成本控制 | 大量訓練需求,API 費用過高 | 每週重訓、多模型實驗 |
| 模型客製化 | 需要完全控制訓練參數 | 特殊領域、極端壓縮需求 |
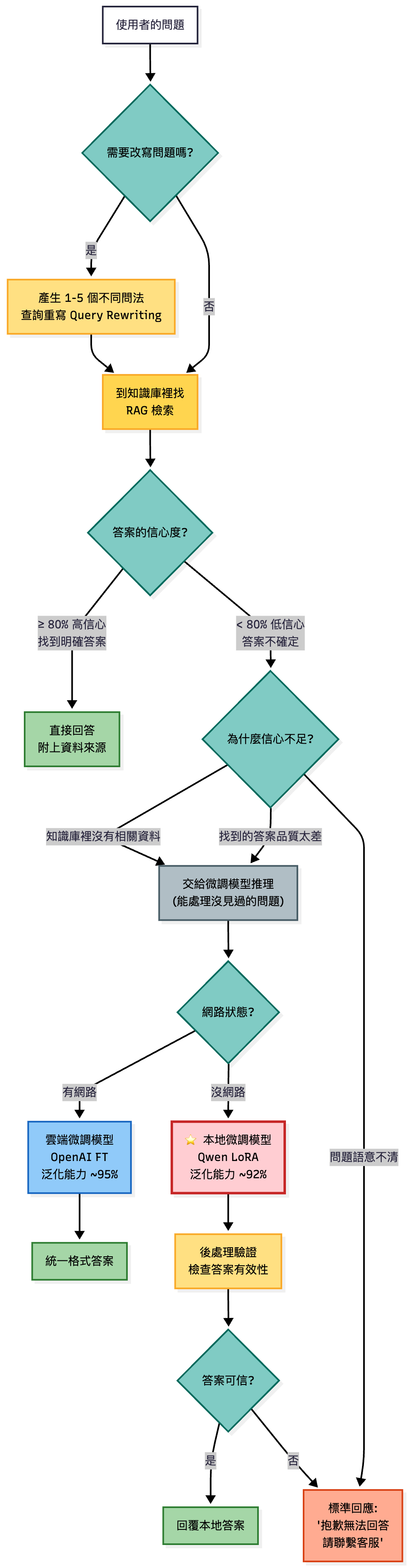
RAG + Fine-tuning 混合決策流程:信心不足時依網路狀態選擇雲端(OpenAI FT)或本地(Qwen LoRA)微調模型
💡 關鍵數據對比:
- OpenAI FT:29 筆訓練資料,泛化能力 ~95%
- Qwen LoRA:300+ 筆訓練資料 + 後處理,泛化能力 ~92%
差異來自基座模型能力與訓練基礎設施的不同。
LoRA(Low-Rank Adaptation) 是一種參數高效的微調方法:
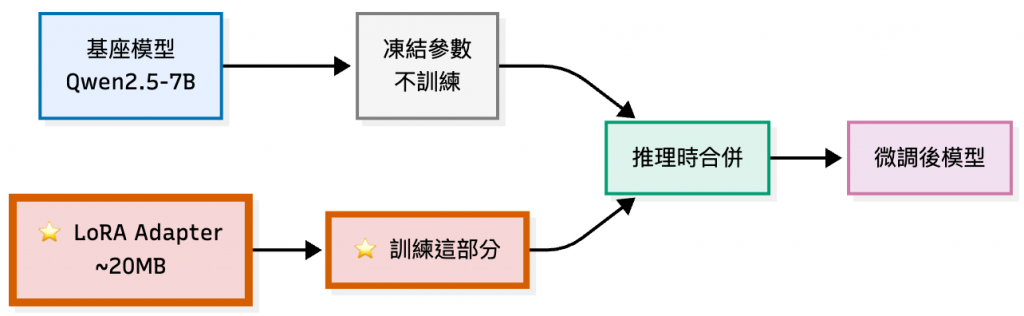
在持續學習場景中,模型吸收新知識時可能會「忘記」舊知識。Replay Buffer 是常用的解決方案:
做法:把新資料 + 小量舊資料混合訓練(例如:80% 新 + 20% 舊)
效果:
⚠️ 學界研究(Is Continual Learning Ready for Real-world Challenges?)指出,持續學習在真實世界中仍面臨「災難性遺忘」與資料管理困難的挑戰,因此 Replay Buffer 這類混合舊資料的手法,往往是實務上不可或缺的一環。
| 面向 | API Fine-tuning(OpenAI / Anthropic / Cohere / Bedrock) | LoRA SFT(自建或開源模型) |
|---|---|---|
| 基礎設施 | 雲端供應商處理,不需自行維護 | 對硬體有要求:可能需要 GPU / 訓練環境 |
| 資料格式 | Instruction-tuning JSONL |
instruction-tuning JSONL |
| 資料安全 | 上傳到雲端(需信任供應商) | 完全本地,不外流 |
| 成本 | 訓練費用依 Token 計價 | 需自行租用 GPU,成本浮動 |
| 訓練速度 | 供應商處理,通常較快 | 取決於硬體,可能較慢 |
| 適用情境 | 快速上線、統一語氣/FAQ | 離線自訓、控制權限、合規需求 |
| 維護 | 更新資料 → 重新上傳訓練即可 | 需自行規劃 Replay Buffer、檔案管理 |
👉 詳細的 LoRA SFT 操作與程式碼,我會在 Day32 - 進階篇:Macbook Air M3 本機 LoRA 微調 Qwen2.5(30 分鐘,相似度 92%) 再完整示範。這裡先讓大家建立概念即可。
此表參考 Google SRE Book: Service Level Objectives訂定。
| 指標類別 | 指標名稱 | 定義(SLI) | 目標(SLO) | 觀測窗 | 來源 |
|---|---|---|---|---|---|
| 品質 | Retrieval 召回率@k=3 | 在 top-3 中至少有 1 個相關文件 | ≥ 70% | 滾動 24h | RAG 服務 |
| 品質 | 檢索失敗率 | 無結果返回 / 總查詢數 | ≤ 2% | 滾動 1h | RAG 服務 |
| 使用者體驗 | 重開率(reopen) | 24h 內語意相似問題再提問比率 | ≤ Baseline × 1.0 | 滾動 24h | Gateway 日誌 |
| 使用者體驗 | 👍/👎 比率 | thumbs_up / (up + down) | ≥ 80% | 滾動 24h | 應用層 |
| 成本 | 成本/請求 | 當日總成本 / 請求數 | ≤ 預期 × 1.10 | 2h ~ 24h | 成本 API |
| 成本 | 快取命中率 | cache_hits / (hits + misses) | ≥ 60% | 滾動 24h | Redis / Gateway |
| 效能 | p95 延遲 | 95% 請求完成時間 | ≤ 500ms 且 ≤ 上版 × 1.2 | 滾動 1h | API 指標 |
| 效能 | p99 延遲 | 99% 請求完成時間 | ≤ 2000ms | 滾動 1h | API 指標 |
| 可靠性 | HTTP 錯誤率 | (4xx + 5xx) / 總請求數 | ≤ 1% | 滾動 5min | Gateway 日誌 |
| 可靠性 | LLM 錯誤率 | LLM API 失敗 / 調用數 | ≤ 0.5% | 滾動 5min | LLM 客戶端 |
| 可靠性 | 系統可用性 | 成功請求 / 總請求數 | ≥ 99.9% | 滾動 30 天 | 綜合監控 |
| 可靠性 | 告警數(發布期間) | 發布期間觸發的告警 | = 0 | 部署期間 | Alert 系統 |
假定條件如下:
| 類別 | 項目 | 數值 |
|---|---|---|
| 業務量 | 每日請求 | 2,000 req/day |
| 單次 token 數 | 1,200 (問題 50 + context 900 + 答案 250) | |
| 知識庫 | 總段數 | 10,000 段 |
| 每週新增 | 100 段(去重後) | |
| 平均長度 | 300 tokens/段 | |
| 快取 | 命中率 | 60% (FAQ 類應用) |
| Redis 容量 | 2GB | |
| 定價 | LLM 輸入 | $0.15/1k tokens (gpt-4o-mini) |
| LLM 輸出 | $0.60/1k tokens | |
| 嵌入 | $0.02/1k tokens (OpenAI) | |
| GPU (A100 80GB) | $3.5/hour[註1] | |
| 部署 | Fine-tuning | 每季 1 次(200k tokens) |
| 金絲雀測試 | 2h 觀測、20% 流量 |
[註1] GPU 成本說明:以雲端 GPU 租用價格(如 AWS p4d.xlarge、GCP a2-highgpu-1g)除以機器上所有的 A100 卡數量為準,若為三年攤提的自購硬體,且利用率大於六成,理論上會低於此值。
推得成本試算如下:
| 項目 | 成本模型(公式) | 範例計算 | 何時採用 | 備註 |
|---|---|---|---|---|
| RAG 增量更新 | ||||
| └ 初次嵌入 | 段數 × 平均 tokens ÷ 1000 × $0.02/1k tok | 10,000 × 300 ÷ 1000 × 0.02 = $60(一次性) | KB 初始化 | 使用 OpenAI embedding 的假設 |
| └ 每週增量新增 | 段數 × 平均 tokens ÷ 1000 × $0.02/1k tok | 100 × 300 ÷ 1000 × 0.02 = $0.60/週 | 文件常更新 | 以「去重後實際嵌入段數」計 |
| └ 本機嵌入 | GPU 時間 × 單價 | 10k 段 ≈ 2 分鐘 on A100 ≈ $0.12 | 合規需求 | MiniLM-L6-v2 嵌入模型免費 |
| RAG 推理成本(每日) | ||||
| └ 未快取 | 請求數 × [(輸入+輸出)tok ÷1000 × 單價] | 2,000 × {[(50+900)×**$0.15**] + [250×**$0.60**]} ÷1000 = $585/day | 常態服務 | 例:gpt-4o-mini(輸入 $0.15/1k、輸出 $0.60/1k) |
| └ 快取後 | 未命中率 × 未快取成本 | 0.40 × 585 = $234/day | FAQ 高重複 | 假設 60% 命中率 |
| └ 快取節省 | 命中率 × 未快取成本 | 0.60 × 585 = $351/day | – | 投資報酬率高 |
| Fine-tuning | ||||
| └ OpenAI FT | 訓練 tokens ÷1000 × $0.08/1k tok | 200k ÷1000 × 0.08 = $16(一次性) | 固定語氣/格式 | 每季重訓 ≈ $64/年(示例) |
| └ 自建 LoRA | GPU $/h × 小時 | A10 $3.5/h × 4h = $14(訓練) | 法遵/私有 | 另有 資料準備 ~$600(示例) |
| 基礎設施 | ||||
| └ 索引儲存(月) | 索引大小(GB) × $0.10/GB/月 | 10k 段 ≈ 15MB ≈ $0.0015/月 | KB 大 | 幾乎可忽略 |
| └ Redis 快取(月) | 記憶體 GB × $0.50/GB/月 | 2GB × 0.50 = $1.00/月 | 啟用快取 | 例:自管/低價方案;雲託管更高 |
| 金絲雀測試(2h) | 新版流量 ×(新舊成本差) | 2h 請求 ≈ 2,000×(2/24)=167;新版 20%→ 33 req;(0.40−0.29)×33 = $3.63/次 | 每次部署新版 | 以 gpt-4o-mini 成本差示例 |
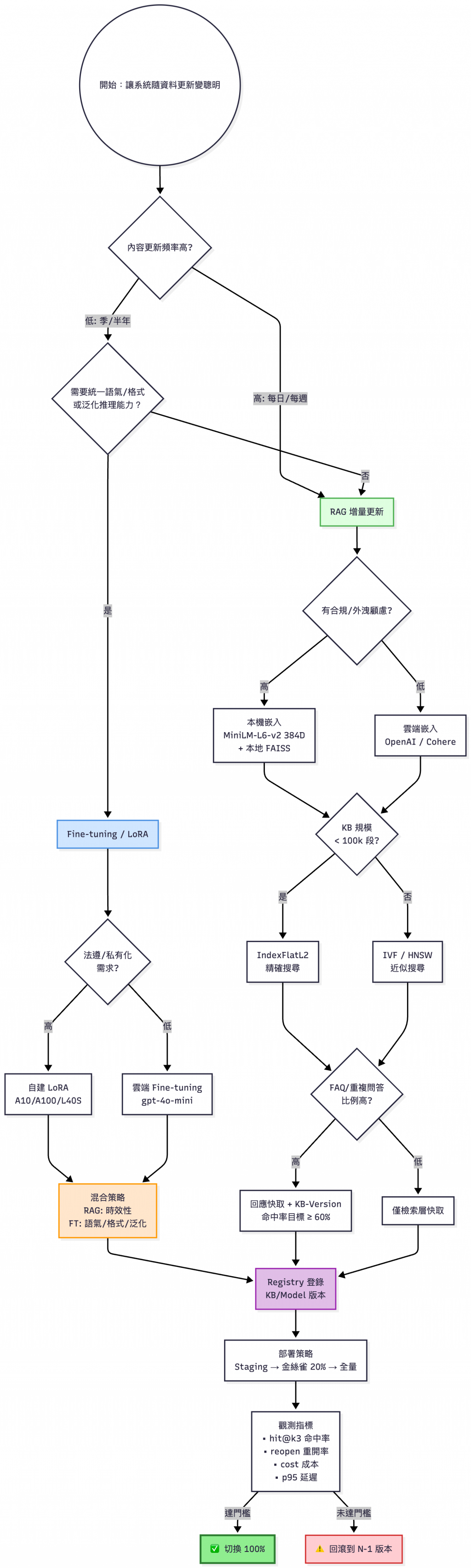
技術選型與部署流程圖:結合 RAG 2.0 架構、MLOps 最佳實踐與企業級監控策略
💡 流程設計參考:
- 更新策略:基於內容變動頻率的技術選型原則
- 安全考量:企業合規與資料隱私保護要求
- 效能改善:向量索引與快取策略的規模化設計
- 部署治理:金絲雀發布與自動回滾機制
⚠️ 聲明:本試算僅提供初步估算,表格內容可能有未盡完備、資料更新時差或項目疏漏。若與實際區域定價、折扣方案、維運費用不一致,結果可能產生明顯偏差;請以實際參數帶入本表公式後之計算為準。
昨天(Day22)提到的Registry(登錄中心) 解決的是「版本管理與可回溯」的問題,確保任何時刻都能知道線上跑的是哪個版本,並且能安全回滾。 但 如果知識與模型本身不持續更新,再完善的 Registry 也只能保證「舊版本」的正確,卻無法避免品質逐步退化。
👉 明天 Day 24:我們將進入模型路由(Routing):如何把不同任務導向合適的模型。

