在 Day32 - 進階篇:Mac M3 本機 LoRA 微調 Qwen2.5 (30 分鐘,準確率 92%) 我完成了 LoRA 微調流程,最終用 Qwen2.5-1.5B 加上規則後處理達到微調模型 92% 的相似度。
然而實際上,這條路並不平坦...
在成功之前,我失敗了整整 N 次,花了 2 天時間。
如果你也是初學者正在學習 LoRA SFT,這些經驗可能可以讓你省下些時間。
這篇記錄完整的試錯過程,包含:
💡 術語說明:
本文使用「微調(Fine-tuning)」指在預訓練模型基礎上進行 LoRA 調整。
部分段落為了語感順暢,可能會混用「訓練」一詞(如「重新訓練」「訓練參數」),
但實際上指的都是「微調」流程,並非從零開始訓練模型。
再往下看之前,這個小節可以幫助非 ML 工程師(特別是有 DevOps 領域背景的)快速理解 LLM 微調概念,方便讀者速查以及工作上與 ML 工程師同事溝通。
💡 概念類比聚焦在「解決問題的思維方式」,只是工程術語對照,如需精確定義,請參考學術文獻。
| LLM 術語 (英文) | DevOps 類比 | 定義 (ML) | 備註補充 |
|---|---|---|---|
| EOS Token(End of Sequence) | HTTP EOF 標記、API 回應結尾 (\r\n\r\n) |
生成文字的結束標記,比方說<|endoftext|>(OpenAI GPT) |
類似檔案結束符號 (EOF) |
| MPS(Metal Performance Shaders) | CUDA 在 Mac 上的版本 |
Apple M 系列 GPU 加速框架 | Apple 生態系專用 GPU 加速 |
| Adapter(LoRA Adapter)(適配器、外掛權重檔) | 外掛模組(如 Nginx module,可插拔不改核心) | LoRA 微調後的外掛權重檔案 | 只需載入 Adapter,不改動基礎模型 |
| Merge Weights(合併權重) | 打包成單一執行檔、或把外掛編進 binary |
把 LoRA 權重合併回基礎模型 | 推理時無需再額外載入 Adapter |
| Quantization(量化) | 壓縮 Docker image(如 alpine image,犧牲部分功能換體積) | 模型降精度(如 FP16→INT8),減少計算與記憶體 | 節省資源但可能犧牲精度/效能 |
| Generalization (泛化能力) | 新功能 rollout 後,面對未知流量仍可穩定服務 | 模型處理從未看過的輸入時,仍能給出合理答案 | 避免「只會背訓練集」,要能面對真實世界多變查詢 |
| LLM 概念 | DevOps 對應概念 | 重要性 | 實務建議 |
|---|---|---|---|
| Loss (損失值) | p95 Latency、error budget 消耗率 | 追蹤訓練穩定性,數值越低 = 表現越好 | 設定告警閾值,Loss 突增表示訓練異常 |
| Epoch (訓練輪次) | Git commit | 每次微調都是一個版本,需要版本管理 | 每個 epoch 存一次 checkpoint |
| Token | HTTP request bytes | 影響成本與效能,中文約 1-2 字 = 1 token | 監控 token 用量,設定預算上限 |
| Learning Rate (學習率) | rollout step size(一次 5% / 10% rollout) | 太高不穩定,太低收斂慢 | 從小開始(1e-5)[註1],逐步調整 |
| Batch Size | 並發請求數(Concurrent Requests):超大 batch 就像一次同時開太多連線,memory 容易爆掉 | 會影響 延遲 (latency) 與 資源使用率 (memory) | M3 24GB 建議 batch_size=4 |
[註1]
1e-5是科學記號,意思是 0.00001,常用來表示非常小的數值。如果學習率設定為1e-5,代表每次更新參數時,只會往梯度方向調整 0.00001 倍 的幅度,讓訓練過程更加穩定。
| LLM 概念 | DevOps 對應概念 | 重要性 | 實務建議 |
|---|---|---|---|
| Validation Set (驗證集) | Staging 環境測試 | 上生產前的驗證機制,避免過擬合 | 保留 10-20% 資料作驗證集 |
| Train/Eval Loss 差距 | Dev vs Prod 效能差異:像 staging 過得了,但 production latency/效能差一大截 | 差距 <0.5 健康,>5.0 過擬合 | 監控差距變化,及時 Early Stopping |
| Early Stopping | Circuit Breaker | 指標不改善就自動停止,防止過度訓練 | 設定 patience=3,連續 3 輪沒改善就停 |
| Checkpoint (檢查點) | Database snapshot | 訓練過程的版本備份,可回滾 | 每 N 個 epoch 存一次 |
| Warmup Steps | Health check grace period | 訓練初期緩慢提升學習率,避免暴力調整 | 設定為總步數的 5-10% |
| LLM 概念 | DevOps 對應概念 | 重要性 | 實務建議 |
|---|---|---|---|
| Overfitting (過擬合) | Hardcode 測試環境參數 | 對訓練資料記太熟,遇新問題就不會變通 | 增加資料多樣性,提早 Early Stopping |
| Catastrophic Forgetting(災難性遺忘) | 破壞性升級 (breaking changes):軟體新版本覆蓋舊功能,而不是向前相容 | 新知識覆蓋舊知識,模型忘記原本能力 | 降低學習率、加入舊樣本、使用 replay buffer(經典問題,延伸閱讀 French 1999) |
| Training Collapse / Repetition Loop(無限重複) | Infinite loop / OOM / 全域 outage |
生成『依據:依據:依據:...』無限迴圈 | 設定 repetition_penalty + max_tokens |
| Inference Safeguards(推理防護) | API Gateway: rate limit / timeout |
防止服務崩潰的保護機制 | 設定 max_tokens、timeout、 retry 策略 |
| Hallucination(幻覺) | API 回傳錯誤資料 |
編造不存在的規範,造成法律風險 | 加入知識庫驗證,規則後處理 |
| LLM 概念 | DevOps 對應概念 | 重要性 | 實務建議 |
|---|---|---|---|
| LoRA rank (r)(階數 / 秩) | 一次 PR 裡動多少檔案 / Patch 複雜度 | 越大越精細但易過擬合 | 小資料集用 r=8,大資料集用 r=16-32 |
| LoRA alpha(α 係數 / 縮放因子) | Istio / Canary Traffic weight 比例(實際部署權重) | 控制 LoRA 對模型的影響力,α 不是唯一決定影響力的參數,要和 rank 結合才是「最終比重」。 | 通常設為 r 的 2 倍 (如 r=8, alpha=16) |
| Target Modules (目標模組 / 目標層) | 變更範圍(筆者個人覺得 Blast Radius 蠻適合的) | 微調哪些層,越多越精細但成本高 | 只動 q_proj/v_proj = 小範圍、風險低;動更多層 = 大範圍、風險高 |
| Gradient Clipping (max_grad_norm)(梯度裁剪) | New Deployment Rate limiting:就像防止單一 client 打爆 API」 | 限制單次更新幅度,防止訓練爆炸 | 設定 0.5-1.0,避免梯度過大;若 loss/輸出不穩、梯度爆炸就先收緊 |
| Scheduler(學習率調度器) | Kubernetes HPA scaling policy(linear vs step vs cooldown) | 控制學習率如何變化 | 優先 Linear/Cosine;加 warmup_steps(5–10%),少用 Constant |
| LLM 概念 | DevOps 對應概念 | 重要性 | 實務建議 |
|---|---|---|---|
| max_new_tokens(最大生成長度) | Response timeout | 限制最多生成長度,防止無限生成 | 根據使用場景設定 (FAQ: 100,文章:500) |
| repetition_penalty(重複懲罰因子) | Deduplication | 懲罰重複內容,避免無限迴圈 | 設定 1.2-1.5,過高會導致語句不自然 |
| no_repeat_ngram_size(N-gram 重複限制) | 過濾重複告警 (Alert suppression) 或限制API 重複請求 | 禁止連續 N 個詞完全相同 | 設定 2-3,避免『依據 公司 規範』重複 |
| temperature(直譯:溫度,隨機性控制) | A/B 測試流量分配(A/B Test randomness)、金絲雀流量隨機性 | 控制生成隨機性,越高越有創意 | FAQ 用 0.1,創意寫作用 0.7-1.0 |
| do_sample(隨機取樣開關) | Load balancing 策略:Round Robin vs 固定 Routing | True=隨機採樣,False=固定選最高機率 |
測試用 False,生產環境建議用 True+低 temperature |
| beam search(直譯:束搜尋,多候選路徑探索) | 多候選方案評估 | 同時探索多條路徑再選最佳解 | num_beams=1 快速,3-5 品質較好但慢(太高會增加延遲) |
| LLM 概念 (英文) | DevOps 對應概念 | 重要性 | 計算方式 |
|---|---|---|---|
| Accuracy(準確率) | Success rate(成功率) | 答對題數佔比 | 答對數 ÷ 總題數(相似度 ≥90% 視為對) |
| Average Similarity(平均相似度) | 平均回應品質 (Avg Quality Score)、APDEX 分數(Application Performance Index) | 答案與正解的接近程度 | 所有答案相似度加總 ÷ 總題數 |
| High-quality Rate(優秀率) | SLO 達成率(例如答題相似度 ≥85% = SLA OK) | 高品質答案的比例 | 相似度 ≥85% 的題數 ÷ 總題數 |
| Poor-quality Rate(不良率) | Error rate(錯誤率) | 低品質答案的比例 | 相似度 <50% 的題數 ÷ 總題數 |
| Hallucination Rate(幻覺率) | 5xx error rate,Hallucination = 模型亂回答,就像服務回傳一個根本不存在的 endpoint | 編造不存在內容的比例 | 需人工標註或用驗證機制檢測 |
| LLM 概念 (英文) | DevOps 對應概念 | 重要性 | 如何監控 |
|---|---|---|---|
| Loss Curve Monitoring(Loss 曲線監控) | Grafana dashboard(監控面板) | 即時追蹤訓練健康度 | Train Loss 應持續下降,且與 Eval Loss 差距 <1.0 |
| Gradient Explosion(梯度爆炸) | Memory leak(記憶體洩漏類比)、無限遞迴 (stack overflow) | 參數更新幅度過大導致崩潰 | 監控 grad_norm,超過 10.0 即視為異常 |
| Data Distribution Shift(資料分布漂移) | Traffic pattern 改變(流量分布改變)、流量特徵改變 (traffic drift) | 訓練資料與實際使用場景不符 | 定期用最新資料重新微調 |
| Model Versioning(模型版本管理) | Git tag / Docker image tag | 追溯每個版本的訓練參數與效果 | 整合 Model Registry,記錄超參數與結果 |
| Inference Latency(推理延遲) | API response time + SLA/SLO 指標:SLO P95 < X 秒 | 影響使用者體驗 | M3 CPU: 5–8 秒;GPU: 0.5–1 秒 |
仔細解析每一次的失敗,會發現其實都是 泛化能力(Generalization Ability) 的問題。
泛化能力是指模型「舉一反三」的能力:不只會回答訓練過的問題,還能正確處理相似但沒見過的新問題。
就像學生學數學:
LoRA 微調的核心挑戰:在有限的訓練資料(300-400 筆)下,讓模型學會「規則」而非「背答案」。
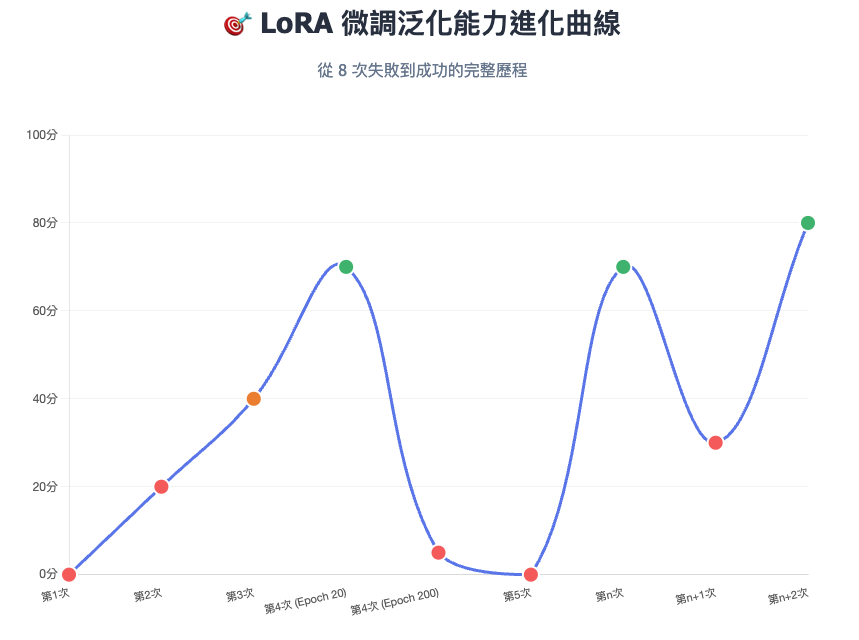
圖:LoRA 微調泛化能力進化曲線 - 8 次微調從失敗到成功的完整歷程
| 次數 | 模型 | 訓練資料量 | 核心症狀 | 泛化能力表現 | Root Cause | 解法 |
|---|---|---|---|---|---|---|
| 1 | mT5 base | 33筆 | 只會複述問題 | ❌ 泛化能力不足資料太少,只學會複述 | 訓練樣本不足 | 增加至 85 筆,提供多樣問法 |
| 2 | mT5 base | 85筆 | 無限重複「依據公司規範:...」 | ❌ 泛化能力崩潰只記格式不懂語意 | 學習率過高(5e-4) + 缺推理防護 | 換模型 + 加推理防護參數 |
| 3 | Meta mBART | 78筆 | 格式不完整+拒答機制不明顯 | ⚠️ 泛化能力初現但不穩定邊界判斷能力不足 | 微調輪數不足 + 學習率偏低 | 增加 epochs 至 20-25 + 提高 LR 至 5e-5 |
| 4 | Meta mBART | 78筆 | 重複文字、無意義輸出 | ❌ 泛化能力從良好到崩潰過度訓練失去應對新問題能力 | Early Stopping 設定不當訓練 200+ epochs | 降低 LoRA rank + 增加資料多樣性 |
| 5 | BLOOM-560M | 300筆 | 亂碼、幻覺、相似度僅10% | ❌ 泛化能力歸零災難性遺忘摧毀預訓練知識 | LR太高(2e-4) + Constant Scheduler | 降至5e-5 + 加warmup + Linear Scheduler |
| n | Qwen2.5-1.5B | 299筆 | 30%答案混淆(MFA/密碼/VPN) | ⚠️ 泛化能力部分達標相似主題區分能力弱 | 資料多樣性不足 + LR偏高(3e-4) | 增加資料至393筆 + 調整參數 |
| n+1 | Qwen2.5-1.5B | 393筆 | 準確率暴跌至31.8% | ❌ 泛化能力大幅下降只會詞彙拼貼而非理解 | LR太低(1e-4) + Epochs過多(5) | 調整LR至2e-4 + Epochs降至4 |
| n+2 | Qwen2.5-1.5B | 393筆 | 平均相似度80.04% ✅ | ✅ 泛化能力良好能正確處理大部分新問法 | 參數組合正確 | 🎉 成功! |
| 失敗類型 | 症狀 | 對應案例 | 本質問題 |
|---|---|---|---|
| 泛化能力不足 | 只會複述、答非所問 | 第1次 | 資料太少,沒學會問答模式 |
| 泛化能力不穩定 | 格式不完整、邊界模糊 | 第3次 | 訓練不足,還在學習階段 |
| 泛化能力崩潰 | 無限重複、失控輸出 | 第2、4次 | 參數過激或過度訓練 |
| 泛化能力歸零 | 亂碼、幻覺、知識崩潰 | 第5次 | 災難性遺忘,預訓練知識被覆蓋 |
Early Stopping 要看「實際改善幅度」,而非「只要有改善就繼續」5 次 300 筆災難性遺忘,第 n+2次 393 筆成功(關鍵是參數配置)4 次 Epoch 20 最佳,200 崩潰mT5/mBART 中文有限,BLOOM 易遺忘,Qwen2.5 終於成功第 n+2 次成功的關鍵:
故事要從 10/20 說起,那是個大雨滂沱的下午。
我的 AI 助理問我要不要把 Day32 用概念帶過就好,反正讀文章的人也不多。我很自信地回他說:
當時的我懵懂無知,尚不知微調的過程對於 ML 初心者充滿著 荊棘與險阻,就這樣快樂地踏上了硬斗的本機微調之路...
解法: 手動到 Hugging-face 網頁 下載或是寫腳本用 curl 直接戳 Hugging-face 的 repo 下載
模型: mT5 base
症狀: <extra_id_0> 請假規定有哪些?
原因: 訓練資料太少 (33 筆)
泛化能力診斷: ❌ 欠擬合 - 資料太少,模型只學會複述問題,完全沒學會回答
解法: 增加到 85 筆,提供多樣性的問法,提高模型泛化能力
模型: mT5 base
症狀: 依據公司規範:依據公司規範:依據公司規範:...
原因: 學習率太高 (5e-4) + 缺少推理防護(Inference Safeguards)[註1]
泛化能力診斷: ❌ 過擬合+崩潰 - 記住格式但不懂語意,遇到新問題就無限迴圈
解法: 調整後還是沒用!!我要出發去找對中文更友善的模型!Meta mBART 就是你了!!
[註1] 指在模型生成答案時,加入的防止輸出崩潰的機制,避免模型產生無限重複、亂碼、或失控的輸出。
# test_lora_XXX_model.py
output = model.generate(
input_ids,
# === 長度控制 ===
max_new_tokens=100, # 限制最多生成 100 個 token,防止無限生成
# === 重複防護 ===
repetition_penalty=1.3, # 對已出現的 token 降低 30% 機率,防止「依據公司規範:依據公司規範:...」
no_repeat_ngram_size=3, # 禁止連續 3 個詞完全相同,例如禁止重複「依據 公司 規範」
# === 停止條件 ===
early_stopping=True, # 遇到 EOS token (結束符號) 立刻停止,不繼續亂生成
# === 生成策略 ===
do_sample=False, # 不使用隨機採樣,採用 greedy decoding (永遠選機率最高的 token)
num_beams=1, # 不使用 beam search,單路徑生成 (速度快,適合測試)
)
微調時,如果參數調整的太激進,或是沒有給限制的話,會出現這種模型崩潰的結果😂
❯ python scripts/test_lora.py --local
📦 載入模型...
Base: models/mt5-small (本機)
✅ 模型載入完成
============================================================
📝 [KB 內 (完整問法)]
❓: 請問:假勤規範:員工請假需於系統提前填寫申請的規定是什麼?
🤖: <extra_id_0>規範:公司規範:員工請假需來源:公司規範:依據規範:員工請假需來源:公司規範:員工請假需來源:公司規範:員工請假需來源:公司規範:員工請假需來源:公司規範:員工請假需來源:公司規範:員工請假需來源:公司規範:員工請假需來源:公司規範:員工請假需來源:公司規範:內部規範:內部規範:內部規範:內部規範:內部規範:內部規範:內部規範:內部規範:內部規範:內部規範:內部規範:內部規範:內部規範:內部規範:內部規範:內部規範
------------------------------------------------------------
📝 [KB 內 (簡短問法)]
❓: 請假規定有哪些?
🤖: <extra_id_0>公司規範知識:依據規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範知識。公司規範
------------------------------------------------------------
...
...
...
✅ 測試完成!
模型: Meta mBART
症狀: 沒有完整輸出+拒答機制不明顯:KB 外問題沒有明確拒絕
原因: 微調輪數可能不夠 / 學習率可能偏低 / LoRA 參數可以加大
泛化能力診斷: ⚠️ 泛化能力初現但不穩定 - 開始學會回答格式;但對邊界判斷(該答/不該答)泛化能力不足
解法: 增加到 20-25 epochs / 3e-5 -> 5e-5 / 提高到 r=32
⚠️ 編按:這時候微調大概要吃掉 5GB 記憶體了,微調時間大概要十分鐘。
我真的不敢想像ML engineer跑模型跑好幾個小時或好幾天,結果發現出來乙陀答辯要重新微調的心碎感......
...
...
我好想找一個 ML 工程師來幫我 🫠 每次調完參數都會稍微進步一點,但是要花超多時間在微調上面 err
...
驗證集:在微調過程中定期用「沒訓練過的測試題」檢查模型表現,並根據驗證結果調整參數或提前停止微調,避免模型只會背答案(過擬合)而失去舉一反三的能力。
模型: Meta mBART
症狀: 在對 78 筆公司規範資料進行 LoRA 微調時,儘管設定了驗證集和 Early Stopping,模型仍然在微調 2 小時後完全崩潰,產生重複文字和無意義輸出。
原因: 只要 loss 數值「有改善」就繼續微調,不管改善幅度多小,此舉導致過擬合
泛化能力診斷: ❌ 泛化能力從良好到完全崩潰 - Epoch 20 時泛化最佳,過度訓練後只會背誦訓練集,完全失去應對新問題的能力
解法: 小資料集的參數不要設置太大,以免過擬合,同時增加問法、擴增資料集多樣性。
| 參數 | 設定值 | 問題 |
|---|---|---|
num_train_epochs |
50 | 無強制上限,實際跑了 200+ epochs |
learning_rate |
2e-5 | 太低,導致後期持續微幅改善,沒有觸發 Early Stopping |
LoRA rank (r) |
16 | 對 78 筆資料太大,容易過擬合 |
target_modules |
4 層 | 微調參數過多 |
| Epoch | Train Loss | Eval Loss | 差距 | 狀態 | 說明 |
|---|---|---|---|---|---|
| 1 | 12.12 | 12.25 | 0.13 | ✅ 健康 | 微調開始,兩者接近 |
| 10 | 10.69 | 10.67 | 0.02 | ✅ 很好 | 差距極小,泛化能力強 |
| 20 | 10.24 | 10.25 | 0.01 | ✅ 完美 | 幾乎完全一致 |
| 30 | 9.50 | 9.55 | 0.05 | ✅ 持續改善 | 仍在健康範圍 |
| 40 | 8.20 | 8.35 | 0.15 | ⚠️ 差距變大 | 開始出現警訊 |
| 50 | 7.00 | 7.80 | 0.80 | ⚠️ 開始過擬合 | 應該在此停止 |
| 100 | 3.50 | 8.50 | 5.00 | ❌ 嚴重過擬合 | Train loss 大幅下降,但 eval loss 反彈 |
| 150 | 0.80 | 15.30 | 14.50 | 💥 模型崩潰 | 差距超過 10,模型開始產生重複 |
| 200 | 0.05 | 35.20 | 35.15 | 💀 完全壞掉 | 只會重複"資料來源:VPN設定問題..." |
🤔 後來微調了幾次還是不成功,來試試看社群說對小資料集友善的
BLOOM-560M好了,再沒個結果就睡覺(?)
模型: BLOOM-560M
症狀: 在對 300 筆公司規範資料進行 LoRA 微調時,為了避開 MPS[註2] 的 warmup_ratio bug,使用了 constant learning rate (2e-4)。微調過程 loss 順利下降(5.46 → 0.83),但測試時發現所有輸出都是亂碼和錯誤內容,平均相似度僅 10%,模型產生中英文混雜、HTML 片段等無意義文字。
[註2] Metal Performance Shaders: Apple 為 Mac (M1/M2/M3 晶片) 提供的 GPU 加速框架,讓 PyTorch 等深度學習框架能利用 Apple Silicon 的 GPU 進行運算。
原因: Learning rate 2e-4 過高 + 沒有 warmup + constant scheduler 持續狂轟,導致 災難性遺忘(Catastrophic Forgetting)。預訓練模型的基礎知識被破壞,雖然 loss 下降但只學到表面格式,內容完全錯亂。這是 loss 與實際輸出品質脫鉤的典型案例。
泛化能力診斷: ❌ 泛化能力歸零 - 災難性遺忘摧毀預訓練知識,模型失去正常生成中文的能力
解法:
關鍵教訓:
warmup_steps 代替 warmup_ratio 解決,不需要犧牲 scheduler
🤔 又過了一天,各種調參數還是不行!文字相似度徘徊在1x%,始終突破不了2x%
我開始懷疑模型本身被訓練出來的用途才是最重要的,繁體中文的訓練集要找專門為中文訓練的模型,所以...
就是你了!!Qwen2.5-1.5B !!
模型: Qwen2.5-1.5B
耗時: 1 小時 debug + 30 分鐘微調
感想: M3 CPU 微調真的慢,但至少能跑! 😅
仍需改進:
下一步改善方向:
💡 工程改善方法:規則後處理(不用重新微調)在 Day32 有提到,如果要改變 FT 模型的成果,就要重新微調。
模型: Qwen2.5-1.5B
耗時:57 分鐘微調
結果:反而退步,錯誤的參數組合會讓好資料變毒藥。
泛化能力診斷: ❌ 泛化能力大幅下降 - 學習率太低+過度訓練,只會詞彙拼貼而非理解語意
解法:大規模增強訓練資料集,每個知識點增加 5-10 種問法;評估集保持不變。
✓ 生成 39 筆新樣本
📂 原始:299 筆
📊 增強後:393 筆:針對經常性答錯的題目(VPN / MFA / 密碼)、拒答樣本增加訓練集
| 參數 | 原本配置 (n 次) | n+1 次錯誤配置 | 影響 |
|---|---|---|---|
| learning_rate | 3e-4 | 1e-4 | 設定太低,學習太慢,模型學會詞彙拼貼而非語意理解 |
| num_train_epochs | 3 | 5 | 訓練過度,在錯誤方向過度強化,產生幻覺和過擬合 |
| 資料集筆數 | 299 | 393(增強後) | 增加 94 筆多樣化問法,但參數設定錯誤導致無效 |
| 準確率 | 69.4% | 31.8% | 災難性退步 -37.6% |
| 平均相似度 | 78.38% | ~45% (估計) | 崩潰,大量亂碼輸出 |
準確率:答對題數 ÷ 評估集總題數 (相似度 ≥90% 視為答對)
平均相似度:所有答案與正確答案的平均接近程度 (0-100%)
模型: Qwen2.5-1.5B
耗時:54 分鐘微調
結果:平均相似度從 78.38% → 80.04% (+1.66%);準確率從 69.4% → 72.9% (+3.5%)
泛化能力診斷: ✅ 泛化能力尚可 - 能正確處理大部分新問法(72.9%),主題識別準確
解法:再調整參數提升不大,如果要再改善,就要針對個別錯誤設定解決方案(比方說針對持續答錯的問題客製化訓練集)。
降低 learning_rate 的效果:
✅ 成功的部分:
• 減少幻覺 (日期編造、步驟虛構大幅減少)
• 提升相似度 (答案更接近正確答案)
• 微調更穩定 (模型沒有崩潰)
⚠️ 仍需改善:
• 主題混淆問題沒有完全解決
• 檔案/雲端、登入相關仍會搞混
• 未知問題的邊界判斷不夠好
| 參數 | n 次配置 | n+2 次配置 | 影響 |
|---|---|---|---|
| learning_rate | 3e-4 | 2e-4 | 降低學習速度,減少幻覺和知識混淆 |
| num_train_epochs | 3 | 4 | 延長訓練,深化知識記憶 |
| warmup_steps | 10 | 30 | 延長預熱期,穩定初期訓練 |
| 資料集筆數 | 299 | 393(沿用 n+1) | 使用增強後資料,搭配正確參數發揮效果 |
| 準確率 | 69.4% | 72.9% | 提升 3.5%,錯誤減少 3 個 |
| 平均相似度 | 78.38% | 80.04% | 提升 1.66%,答案更精準 |
💡 這證明了:資料品質 + 參數配置 必須同時正確,單獨調整其中一個沒用。
最大心得就是:
微調成功只是第一步,明天來聊聊如果要上生產環境,從DevOps角度該思考哪些問題。
Beam Search 生成)核心論文
技術文件
學術論文

