這系列是我 9/4 起床時腦中靈光一閃決定要寫的。當我在 Day 1 決定最後目標是要做「一個企業知識庫 FAQ Chatbot」時,說實在心裡有點慌張,畢竟我也不是很確定從零開始三十天真的夠嗎?我完全沒有 ML 領域的知識真的寫得完這系列嗎?
現在回頭看,我在這系列的文章有做到以下事情:
DevOps 經驗到 LLM 應用,從監控、快取、路由的策略到上線流程,本質上都是「如何讓服務穩定運行」Prompt 實驗到生產環境的部署,而且是我一直很想嘗試的 Cloudflare 系列方案鐵人賽的精神,就是在有限時間內做出可驗證的成果,而 Day29 的線上環境部署,正好完成了這個里程碑。
如果你從 Day01 和我一起走到現在,相信我們都已具備了:
✅ RAG 應用與架構設計能力|✅ 成本與效能改善觀念
✅ 以安全角度思考 LLM 應用開發|✅ SRE 角度的監控與上線策略
然而專案上線對於工程師們來說往往只是挑戰的開始,上線後的維運才是真正考驗工程能力的時刻。
今天這篇文章,是獻給每一位堅持到最後的你。 讓我們一起把「能跑」變成「持續進化」。
| 週次 | 主題 | 關鍵產出 | 代表文章 |
|---|---|---|---|
| Week 1 | 啟動與 RAG 基礎 | Docker/Conda 環境、向量資料庫比較、Embedding 實測、Minimal RAG + Web Demo | Day06 - 初探 RAG(Retrieval-Augmented Generation) |
| Week 2 | 資料治理與 Pipeline 自動化 | 文件處理、索引建立、版本控制、Data Drift 偵測、自動化排程 | Day14 - LLMOps Pipeline 自動化實戰:用 Prefect 與 Dagster,拯救你的睡眠時間 |
| Week 3 | 應用層與可靠性 | Prompt 管理與工作流、API Gateway(驗證/限流/觀測)、Observability、幻覺偵測、快取 | Day18 - 用 FastAPI 實作 LLM API Gateway:驗證、限流、觀測與實務選型 |
| Week 4 | 生產化與雲端部署 | Registry/Iteration/Routing/Security/Cost 收斂,AWS + Cloudflare 上線與驗收 | Day29 - RAG FAQ Chatbot 實戰案例 III:部署、連通、觀測與成本驗證 |
😎 想複習特定主題? 回到30 天帶你實戰 LLMOps:從 RAG 到觀測與部署 - 系列首頁查看完整文章列表
部分功能建構中 🫠
💡
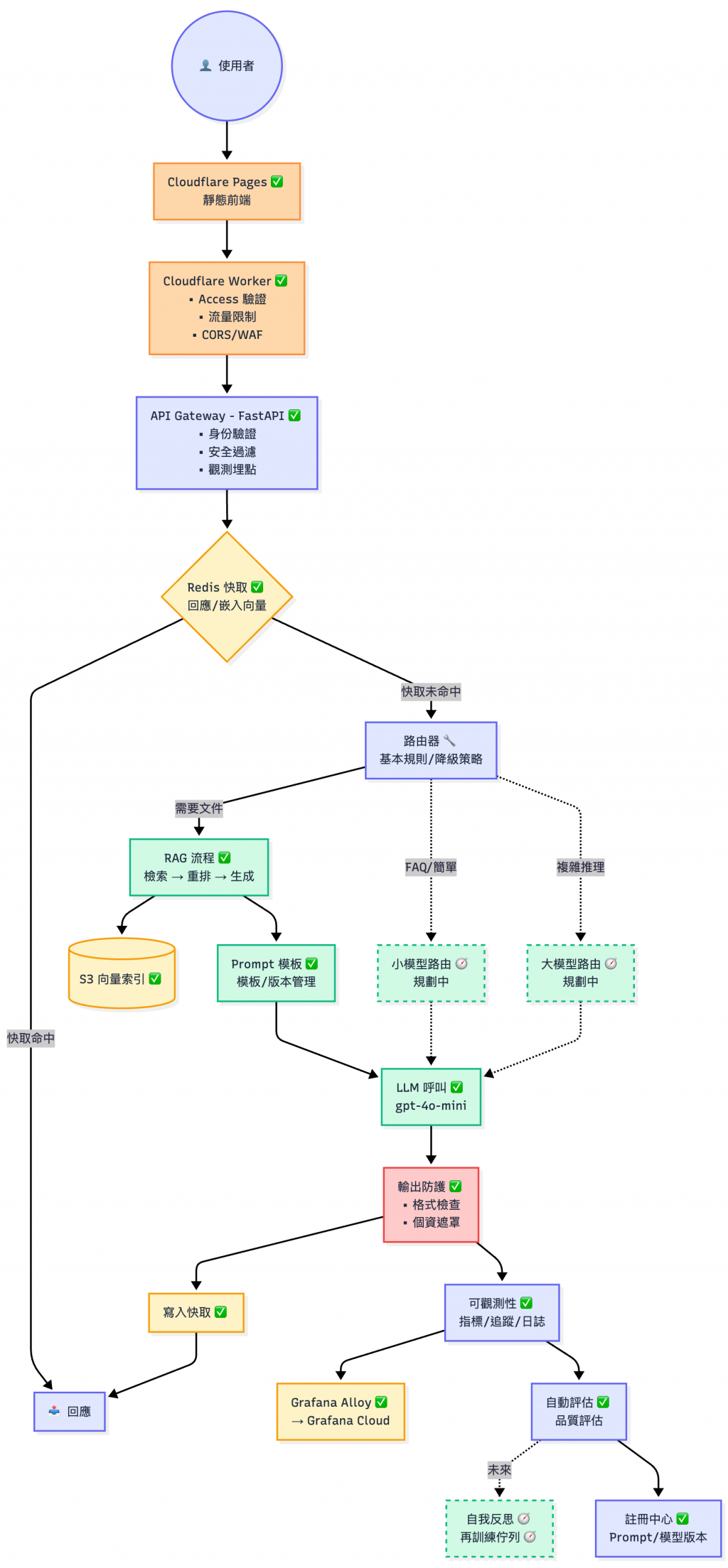
Workflows我已經放在 GitHub 上面。為了測試方便,目前是用手動觸發的方式,本節會介紹他們如何組合起來。Workflows的步驟有相通之處,建議自己準備base image,就可以省下更多CI/CD的時間。
⚠️
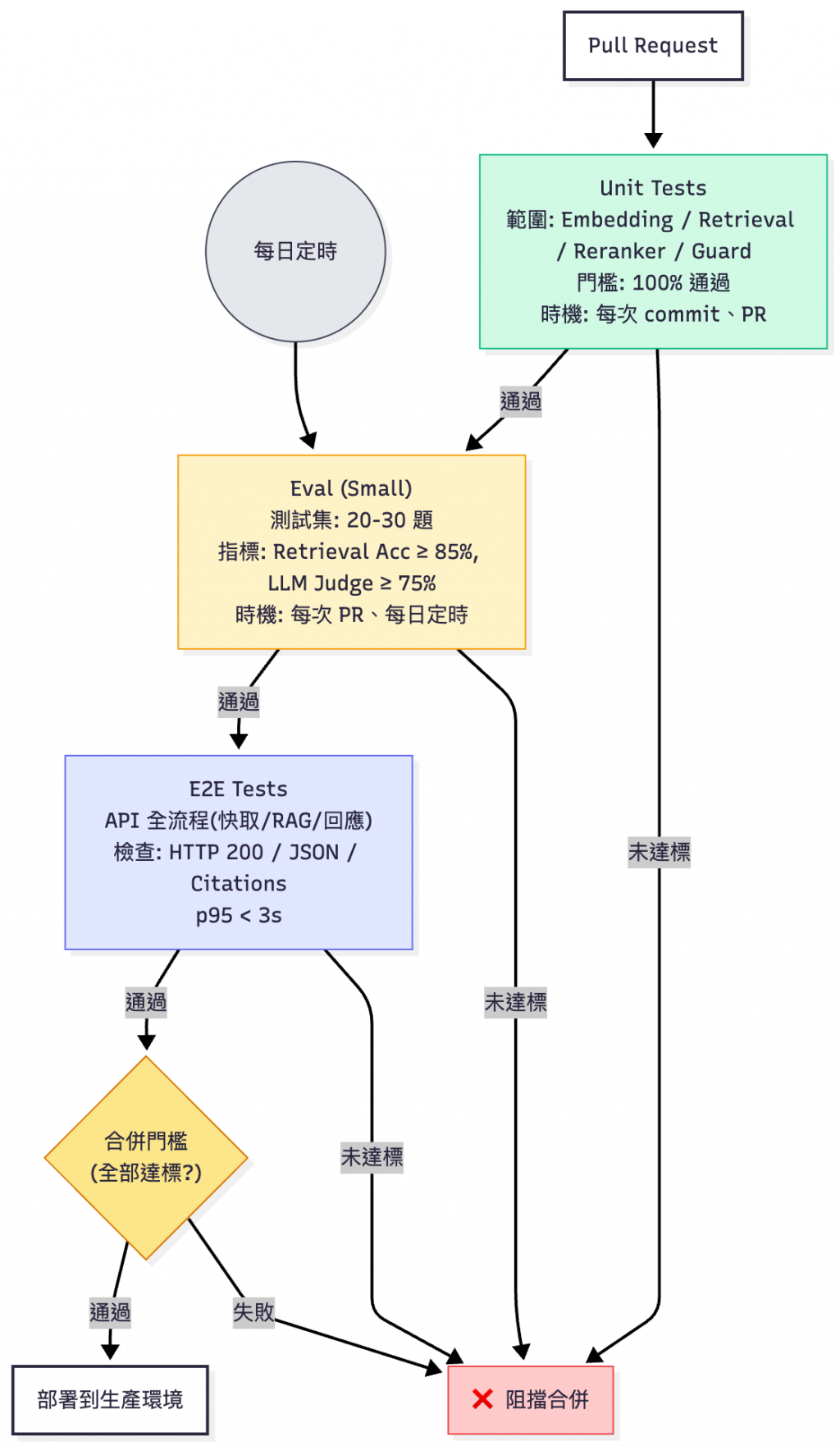
- 生成品質目前是設定在 60% PASS,但這不是 產品化的標準
- 測試集包含 真實使用者查詢,實際環境不會進版控以避免敏感資料外洩。
CI流程可以從 -S3/GCS以EVAL_DATA_TOKEN動態取回整合測試,今天的展示流程是使用非真實資料的小型樣本。
⚠️ 我實際在寫 workflow 時,有發現如若 e2e test 的時候
FAISS維度(Dimesion)不相符也會導致測試失敗。開發用的索引和實際在產線上的索引維度必須一致。如果可以的話,建議從Model Registry抓取對應的kb_version,實作細節可以參考 Day22 - LLM 與知識庫的版本控制中心:Model Registry。
| 測試階段 | 當前表現 | 產品發布門檻 | 狀態 | 備註 |
|---|---|---|---|---|
| Unit Tests | 100% | 100% | ✅ 達標 | 模組功能穩定 |
| 檢索準確率 | 100% | ≥85% | ✅ 超標 | Top-1 準確度優秀 |
| 生成品質 | 62% | ≥75% | ⚠️ 待改進 | 主要改善目標 |
| E2E 可用性 | 通過 | 100% 通過 | ✅ 達標 | 端到端流程穩定 |

GitHub EVAL test Workflow 結果
[註1]
Jaccard 相似度衡量LLM回覆答案與測試集裡面的參考解答的重疊程度,公式為「交集 ÷ 聯集」。交集是兩邊共同的詞或片段,聯集則是兩邊所有詞的總集合。若相似度低於門檻(如 0.60),則該題判定失敗;但只要整體準確率達標,測試仍會通過。
| 應用場景 | 檢索準確率 | 生成品質 | 額外要求 |
|---|---|---|---|
| 內部知識庫 | 80%+ | 75%+ | 快速迭代能力 |
| 客服機器人 | 90%+ | 80%+ | Fallback 機制 |
| 技術文檔助手 | 95%+ | 85%+ | 來源引用功能 |
| 醫療/法律諮詢 | 98%+ | 95%+ | 強制人工審核 |
Root Cause 可能原因分析:
改進行動(可按優先順序執行):
| 優先級 | 改進項目 | 具體做法 | 預期提升 | 驗收標準 |
|---|---|---|---|---|
| P0 | Prompt 精簡 | 移除冗語、改條列式、限制輸出 ≤300 tokens | +5-8% | 16 筆 eval 平均 tokens ≤300 |
| P0 | Context 預算器 | 動態計算 token 預算、保留高分 top-k=3 片段 | +3-5% | 正確率不降且 budget 達標 |
| P1 | Eval 資料校準 | 檢查測試集代表性、補充邊緣案例 | +2-4% | 新測試集通過率 ≥75% |
| P1 | Multi-Judge | 使用 GPT-4 + Claude 雙重評審、取共識 | +3-5% | 評審一致性 >80% |
建立自我進化的評估體系,讓每次失敗都成為系統改善的養分。這邊採用三階段門檻策略,避免邊緣值抖動:
💡為何設定 70-75% 警戒帶?因為 LLM 評估可能有誤差,邊緣值可能是測試資料問題而非程式問題,人工覆核可避免誤判
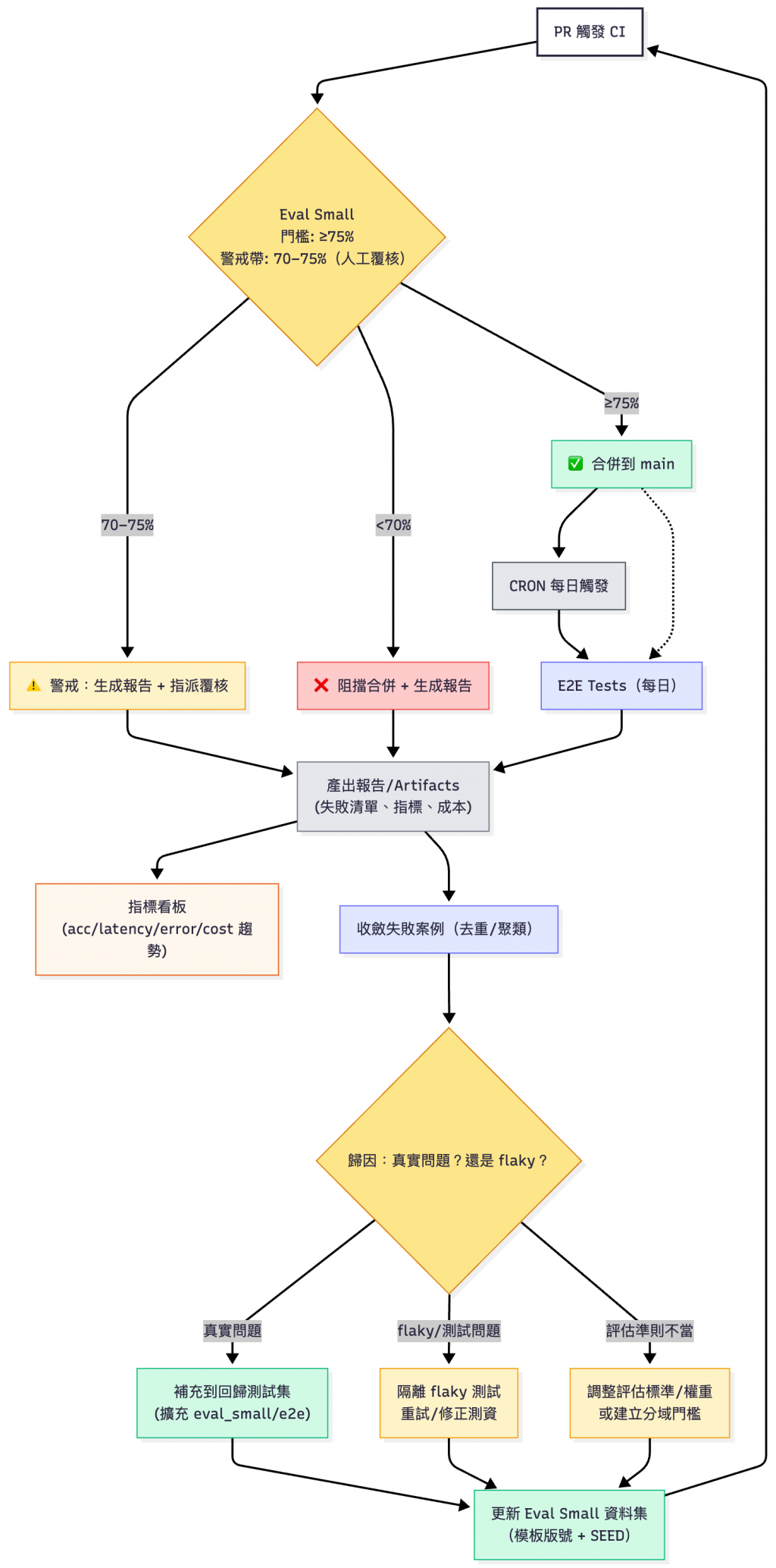
關鍵設計理念:
eval-dataset-v20251015),確保可以回溯任何時期的評估基準[註1] Flaky Test: 不穩定的測試(有時 pass、有時 fail)
[註2] LLM Judge: 用另一個 LLM 當評審,判斷答案品質
基於 Day27 - RAG FAQ Chatbot 實戰案例 I:功能驗收全紀錄(檢索 × 快取 × 安全 × 監控)的測試環境以及驗收結果,建立生產環境的服務水準目標:
| 類別 | 指標 | 目標值 | Day27 驗收 | 監控來源 |
|---|---|---|---|---|
| 可用性 | 成功率 | ≥99.9% | 100% ✅ | llm_requests_total |
| 效能 | P95 延遲(命中快取) | ≤100ms | 8ms ✅ | llm_request_latency_seconds |
| 效能 | P95 延遲(未命中) | ≤2.5s | 2.85s ⚠️ | llm_request_latency_seconds |
| 成本 | 每請求成本 | ≤NT$0.2 | $0.005 ✅ | llm_cost_total_usd |
| 品質 | 檢索準確率 | ≥85% | 100% ✅ | 離線評估 |
| 品質 | 生成品質 | ≥75% | 62% ⚠️ | LLM Judge |
| 快取 | 命中率 | ≥60% | - | rag_cache_results_total |
⚠️ 重要: 請先設定 OpenAI billing alert ($XX/月上限),避免測試時超支
⚠️ 待改進項目(P0 優先級):
📋 告警規則(核心三條):
💡 實戰建議:先用 Day27 數據作為 baseline,初期只開核心告警,避免告警疲勞。
北極星指標(North-Star Metric, NSM)是一個(或極少數幾個)能最直接代表「產品為使用者創造的核心價值 」的指標。它用來統一方向、對齊團隊、驅動長期成長:每天做的改善,不再是零碎輸出(任務數、功能數),而是能穩定把產品往「對使用者更有價值」推進的那件事。
一份好的北極星指標應該以使用者價值(外部體驗/結果)為中心、可以透過實驗和反覆迭代改善、可以由不同的版本或是實驗來公平對比(有一致的定義/抽樣/時間窗),並且不容易被偽造(比方說被腳本自動化刷指標)。
每週成功解決的獨立問題數
(Weekly Successfully Resolved Unique Questions)
| 要素 | 說明 |
|---|---|
| 定義 | 使用者提問後「未在 5 分鐘內重複提問同類問題」的 unique query 數量 |
| 目標 | 從 baseline 提升 50%(6 個月內) |
| Day27 狀態 | 🔴 未追蹤(需建立 baseline) |
| 量測方式 | query logs + 重複查詢偵測 + 週報統計 |
| 驅動行動 | 提升檢索品質、擴充知識庫、改善Prompt、降低成本以擴大使用 |
| 檢視節奏 | 每週一檢視趨勢,每月復盤成效 |
為何選這個做為北極星指標?
✅ 直接反映產品價值(幫使用者解決問題)
✅ 可驅動團隊統一行動方向
✅ 可量化追蹤且與商業價值掛鉤
從 SRE 角度來看,提升北極星指標固然重要,然而我們還是必須守護以下的底線,來確保系統回答的品質以及使用者體驗順暢:
| 類別 | 指標 | 目標 | Day27 狀態 | 為何需要這個護欄? | 優先級 |
|---|---|---|---|---|---|
| 品質 | LLM-Judge 勝率 | ≥55% | 🟡 Jaccard 62%🔴 無 Judge | 答案錯誤 → 使用者不信任 → 不願再用 | P1 |
| 品質 | Citation Precision | ≥85% | 🟡 有引用但未量化 | 引用錯誤 → 信任度下降 | P1 |
| 體驗 | P95 Latency(未命中) | ≤2.5s | 🟡 2.85s(略超) | 太慢 → 使用者放棄 | P0 |
| 體驗 | 成功率 | ≥99.9% | 🟢 100% ✅ | 服務掛掉 → NSM 歸零 | ✅ |
| 成本 | Cost per request | <NT$0.2 | 🟢 0.005 ✅ | 成本太高 → 無法規模化 | ✅ |
| 成本 | 平均 Token 數 | ≤300 | 🔴 967(超標) | Token 過多 → 成本增加 + 延遲上升 | P0 |
| 成本 | 升級率(小→大模型) | 10-30% | 🔴 Day27 單模型 | 過度升級 → 成本暴增 | P2 |
| 安全 | Guard 誤報率 | ≤2% | 🟡 測試全擋🔴 無統計 | 誤攔合法請求 → 使用者受阻 | P2 |
| 效率 | Cache Hit Rate | ≥60% | 🟢 已有指標 ✅ | 命中率低 → 成本增加 | ✅ |
| 流程 | 週報完成率 | 100% | 🔴 無定期覆核 | 缺乏覆核 → 品質劣化被忽略 | P1 |
檢視節奏:
雖然我的專案並未真實給外部使用者使用(我必須先對得起我的錢包🫠),但是以上指標可以給各位有興趣的讀者作為參考。
雖然因為時程和費用關係,我沒有明確做掉 Logs 這塊,不過實務上我會把 Logs 分成三層處理:邊緣(Cloudflare) 把 Log 推送到 s3 或是其他 Object Storage 做長期稽核、網路(ALB) 送 S3 存 Access Logs、**應用以 JSON stdout 交給 Grafana Alloy/Promtail 收集,集中到 Grafana Cloud Loki。三層用同一個 x-correlation-id 串起來,除錯時能從 Edge 、 ALB 、 App 一路追溯,既能即時查問題,也保留長期稽核與成本可控。
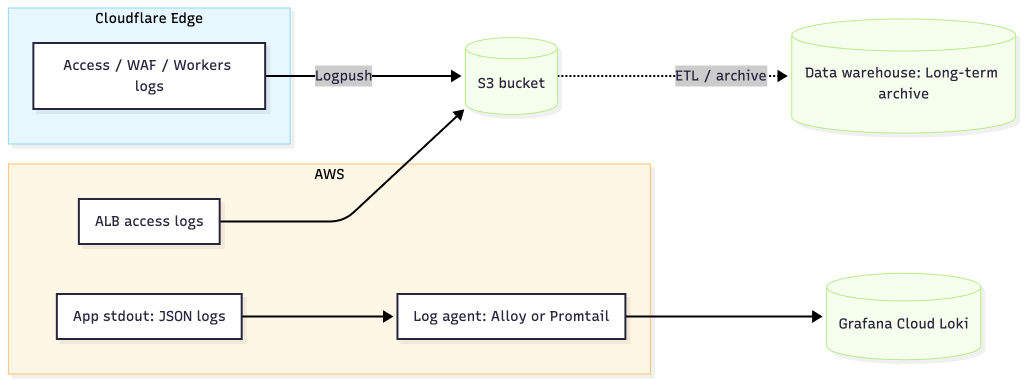
| 日誌來源 | 格式 | 結構化策略(labels vs body) | 收集/匯入管道 | 上傳目標 | 等級與取樣 |
|---|---|---|---|---|---|
| FastAPI / Gunicorn(App) | JSON(stdout) | labels:service, env, version, route, status;body:message, duration_ms, user_id_hashed, client_ip_hashed…(labels 控制在 5–8 個內) |
Alloy / OTel Collector(產生/傳遞 x-correlation-id) |
Grafana Cloud Logs | error / warn 全量;info 取樣(高 QPS 路徑 5–10%;尖峰期可再下調) |
| 層級 | 儲存位置 | 建議留存期(範圍 → 預設) | 改善/合規措施 |
|---|---|---|---|
| 熱存(即時除錯) | Loki / Grafana Cloud Logs | 7–14 天 → 預設 14 天( 30 天也可,但成本較高) | 快查、與 Metrics/Traces 串查(trace_id / correlation_id) |
| 熱存(延長版,可選) | Grafana Cloud Logs | 14–30 天 → 預設 30 天(若團隊常需回看一個月) | 與 SLO/迴歸分析對齊;超過 14 天建議降低 info 取樣率 |
| 冷存(稽核/追蹤) | S3(壓縮+Lifecycle) | 30–180 天 → 預設 90 天,到期自動轉 Glacier | PII 掩碼後再落地、分區(date/level/service)、物件鎖/版本控 |
| 問題 | 查詢步驟 | 觀察指標/欄位 | 備註 |
|---|---|---|---|
| Edge 擋掉了嗎? | 比對 Access/WAF 與 ALB 同時段請求量差異 | action=block/allow, rule_id, ALB target_status_code |
量差=邊緣已攔截;再抽樣檢視規則命中分佈 |
| 慢在哪? | 先看 Metrics p95 鎖定時間窗 → 用 correlation_id 在 Loki 串查整段 |
correlation_id, duration_ms, route, status, upstream_time |
用同一 ID 串 Edge → ALB → App 日誌與指標 |
告警門檻需要依真實流量校準,避免一開始就「報警成災」。如果真的要用建議先用 Grafana Cloud Alerts 或 Alertmanager 開三條核心告警:服務存活(up0,3m)、延遲 p95(>1.5s,10m)、錯誤率 5xx(>2%,10m),跑一週後再按 SLO 調整門檻與抑制規則。
實務上我的經驗是會自建 Alert Manager 系統去串接 Prometheus,如果是和 AWS 原生工具有相關的也可以用 CloudWatch Metrics + SNS + Slack 兜出告警系統。
以下提供一張告警工具決策圖,以我專案的大小應該是直接用 Grafana Cloud 就完事:
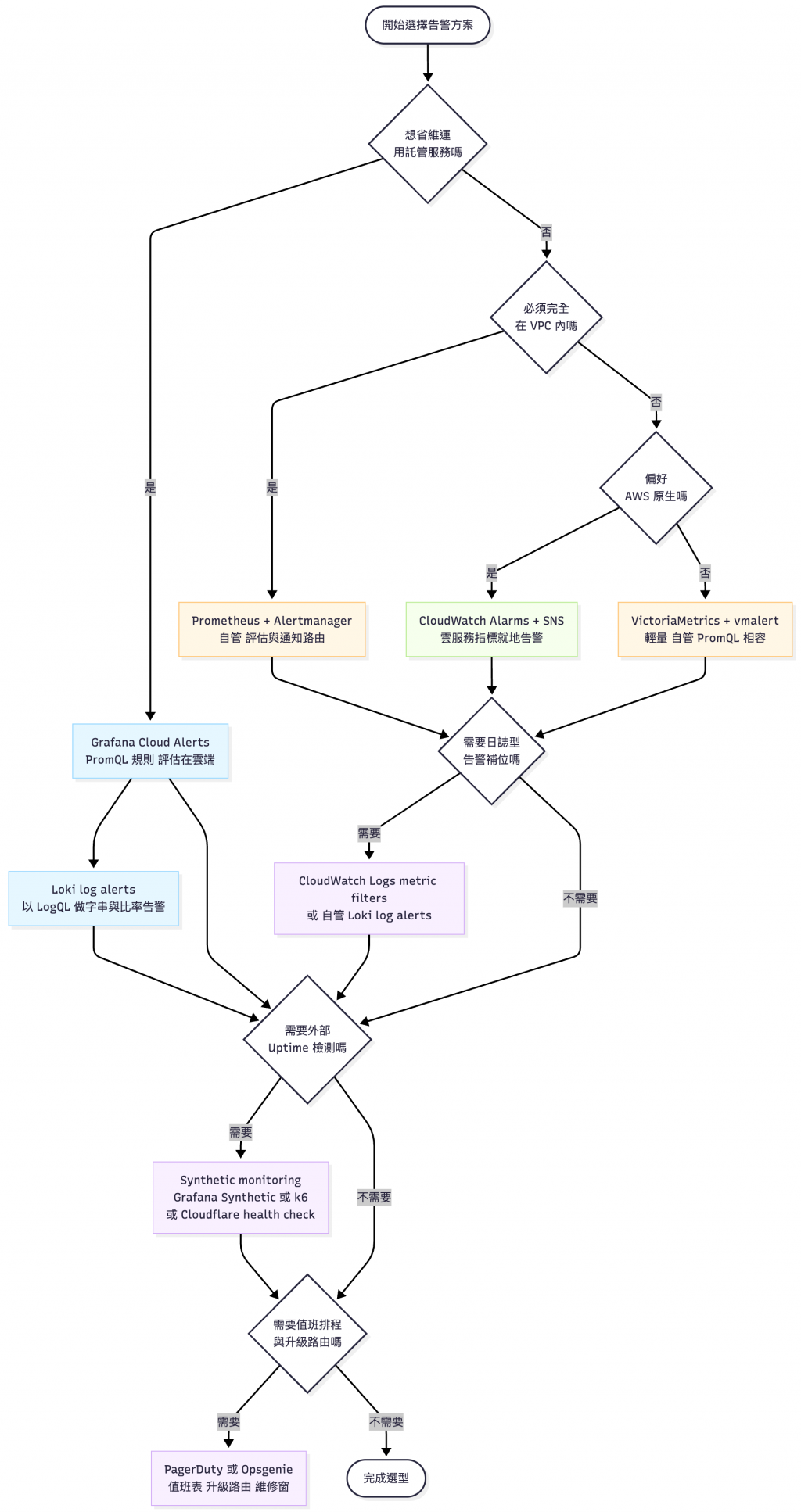
請參考 Day14 - LLMOps Pipeline 自動化實戰:用 Prefect 與 Dagster,拯救你的睡眠時間
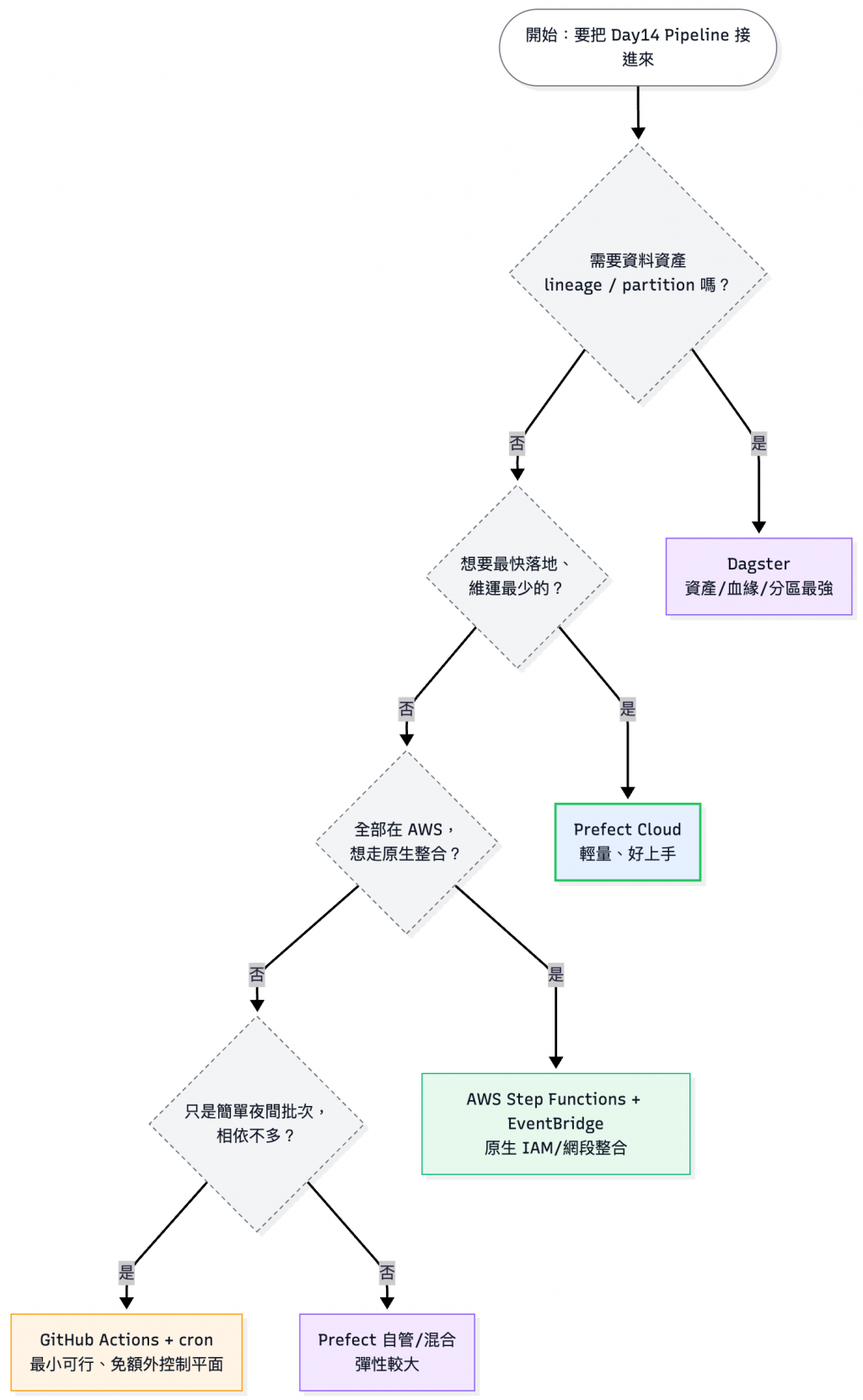
可以參考 Day14 使用 LLM Pipeline 的工具,不過如果你的情境很簡單(像我這次的實戰案例),可以用 GitHub Workflow 就解決,如果是私有的環境應該使用另外一台和 EC2 類似大小(2 vCPU / 4GB Memory)的就可以搞定了。
可以參考以下決策樹:
以我 Day28 實戰篇分享的那種架構,可以先上 Auto Scaling Group,這是最不用改動現有架構的方式。但如果後續要承受更多的 requests,我會建議還是採用 ALB + ASG + EC2 / ECS 的方式去做,會比較容易設定。
| 節點 | 指標/訊號 | 判斷目標/門檻 | 策略 | 備註 | 最小/快可行(先做) |
|---|---|---|---|---|---|
| Edge(Cloudflare) | 每 IP/路徑 QPS、4xx/5xx、WAF 命中 | 高峰前預熱快取;4xx/5xx 連續升高 | 限流+快取: 先擋尖峰(已做) | 減少回到源頭=變相「Scale Out」 | ⭐ |
| ALB | ALBRequestCountPerTarget、TargetResponseTime |
p95 > 1.5s、每目標 RPS > 30–50 | Target Tracking:觀察 RPS 或目標回應時間 | 目前專案沒用到 ALB,可以建立 Target Group(HTTP 健康檢查),把 EC2/Service 掛上去 | |
| App(EC2) | CPU、記憶體、同時連線/佇列長度 | CPU 50–65%;記憶體:80-85% | Target/Step Scaling | CPU:設定 ASG(AutoScalingGroup)監控ASGAverageCPUUtilization,記憶體:裝 CloudWatch Agent 上報,自訂或 mem_used_percent > 80–85% 觸發 |
✅ |
| 非同步工作/Queue | 佇列長度、等待時間 | 等待 > 30s 或長度 > 100×工作/實例 | 基於佇列長度擴縮 | IO 密集用可以用這種做法消化需求,用於尖峰消化流量/外部限流/長工時任務(與輸入長度無關;入口仍應限制 input | ✅* |
| Cache(Redis) | 命中率、記憶體 | 命中率 < 60%、mem > 85% | 調高節點記憶體 或是 增加分片 | 命中率升高就可以直接降低擴容需求 | |
| LLM API 限額 | 供應商限速、錯誤率 | 逼近限額或 429 升高 | 節流+排隊+降級 | 小模型先擋著用,需要時做分級路由(再升級大模型) | ⭐ |
✅=可以很快做完;✅*=若有該元件可以做;⭐=雖非 autoscaling,但能降低壓力。
這 30 天的專案目的是為了全面認識 RAG 的每個環節在做什麼,以及可以手把手從零到一體驗 RAG FAQ Chatbot 開發建置以及上線。
在真實的工作場景,專案上線對工程師來說往往只是起點。這一系列鐵人賽最重要的,是把以前工作上的 DevOps 概念落實到 LLM 應用開發,最後透過三步驟的 CI/CD 檢核 pipeline 以及回饋循環,讓這套系統可以持續提供穩定的品質。
這三十天對我來說並不只是「怎麼做 RAG FAQ Chatbot」,更是如何實踐工程化方法,打造可靠的近生產級 LLM 應用。新專案、套件對我來說是具有不同功能的工具,新工具會源源不斷出現,然而決策思考過程卻可以延伸到未來:無論是 n8n/MCP/Codex 等工具做工作流的實作,還是資料清洗、摘要等自動化流程都可以套用。
系列結束了,但我們的探索才剛開始。
每一條路都有大大的學問,都值得繼續探究。
(裡面推薦的中文實體書我自己有買,方法論我覺得要看自己環境適不適用)
30 天的旅程,感謝你的陪伴。無論你是:
我會在 GitHub 和個人部落格持續維護與分享之後的專案。
如果《30 天帶你實戰 LLMOps:從 RAG 到觀測與部署》系列對你有幫助,歡迎:
Hazel 撰於 2025 iThome 鐵人賽最後一天
2025.10.14

