
在 昨天 Day 24,
我們讓多位 Agent 學會「協作」——由 Supervisor 統籌專家團隊,
讓系統能整合氣象、景點與顧問三方資訊,輸出完整的旅遊決策。
但這樣的智慧仍主要依賴「文字」層次。
真實世界的任務往往包含更多感官資訊:
旅行時,我們會看到菜單、拍下藝術品、聆聽音樂。
要讓 AI 真正理解世界,就必須具備多模態(Multimodal)能力。
傳統 LLM 只能處理文字;
而多模態模型能同時理解文字、圖片、音訊甚至影片。
這使得 AI 不再只是「讀者」,而能成為「觀察者」。
| 模態 | 範例 | 應用場景 |
|---|---|---|
| 文字 | 問答、摘要、推理 | 對話與決策 |
| 圖像 | 菜單、地圖、畫作 | 辨識與描述 |
| 音訊 | 導覽語音、音樂片段 | 語音辨識與分析 |
| 影片 | 旅遊紀錄片、監視畫面 | 情境理解與摘要 |
LangChain v1.0 搭配 Gemini 2.5 Flash,
提供了完整的 Multimodal 支援,詳細請參考 官方文件。
我們可以在同一個 Agent 中同時輸入文字與圖片,
讓它理解視覺內容、語意脈絡,並生成自然語言回應。
在旅遊場景中,
這代表助理不只會規劃行程,還能看懂菜單、分析畫作、辨識地標等。
假設我們走進維也納著名的炸豬排餐廳 Figlmüller,
拍下菜單,希望 AI 幫忙翻譯並推薦一份最具代表性的料理。

圖:維也納炸豬排餐廳 Figlmüller 的菜單。AI 透過多模態輸入,辨識並翻譯德文菜名,推薦最具代表性的經典料理。(來源:官方 Menu)
import base64
from langchain_core.messages import HumanMessage
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(model="gemini-2.5-flash")
menu_image = "figlmuller_menu.jpg"
with open(menu_image, "rb") as img:
encoded = base64.b64encode(img.read()).decode("utf-8")
message = HumanMessage(
content=[
{"type": "text", "text": "請翻譯這份菜單,並推薦一道經典的維也納料理。"},
{"type": "image_url", "image_url": f"data:image/jpeg;base64,{encoded}"},
]
)
response = llm.invoke([message])
print(response.content)

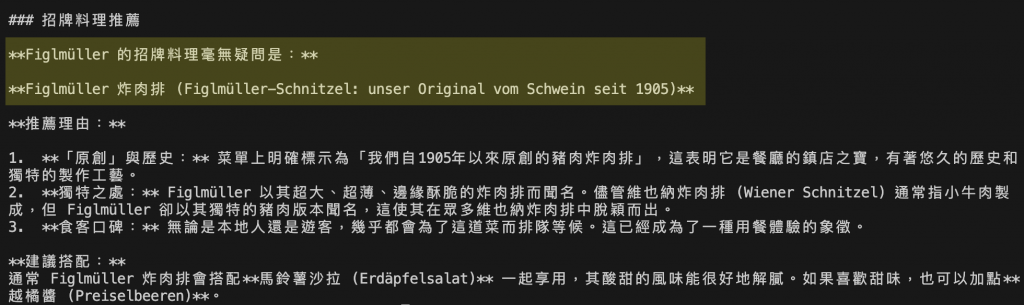
圖:AI 對維也納炸豬排餐廳 Figlmüller 的菜單進行多模態分析之結果。模型讀懂菜單並自動生成的中文翻譯,並根據文字與圖片內容推薦餐廳的招牌料理「Figlmüller 炸肉排」,並解釋其歷史與特色。
Gemini 2.5 Flash 模型能從德文菜單圖片中辨識菜名與價格,生成中文翻譯,並自動推薦餐廳招牌菜「Figlmüller 炸肉排」。
它同時解釋了料理的歷史與特色,並建議經典搭配,展現模型在圖像理解與語意推理上的整合能力。

圖:Figlmüller 的維也納豬排(Wiener Schnitzel)。這塊金黃酥脆的豬排大到覆滿整個餐盤,第一眼就讓人驚艷。薄薄的麵衣、樸實的調味,卻意外耐吃,正是維也納經典美食之一;而 Figlmüller 也正是維也納豬排的招牌百年老店。(攝影:作者自攝)
延續 昨天 Day 24 的 Multi-Agent 架構,
今天我們替維也納旅遊助理新增一位具視覺理解能力的 CuisineAgent(美食顧問)。
這位新成員能分析使用者上傳的餐廳菜單圖片,
辨識德文菜名、翻譯內容,並推薦代表性料理。
| Agent | 功能 | 模態支援 |
|---|---|---|
| WeatherAgent | 分析天氣 | 文字 |
| PlannerAgent | 規劃行程 | 文字 |
| CuisineAgent | 分析菜單圖片與推薦料理 | 圖像 + 文字 |
| AdvisorAgent | 整合建議 | 文字 |
| Supervisor | 統籌協作流程 | — |
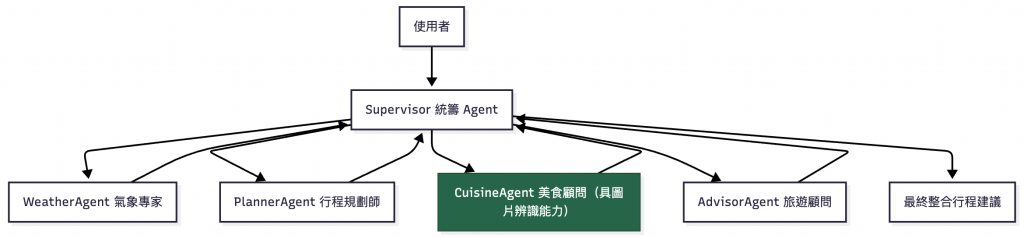
圖:Multimodal × Multi-Agent 系統架構。Supervisor 統籌四位專家——氣象、行程、美食與顧問。美食顧問能理解圖片(菜單)內容,其他 Agent 則進行文字推理與決策,最終由 Supervisor 整合成完整旅遊建議。
因完整程式篇幅較長,故聚焦在今天新增的美食顧問相關的程式片段,完整程式請參考 昨天 Day 24 的 Demo。
import asyncio, base64, os
from langchain.chat_models import init_chat_model
from langchain.agents import create_agent
from langchain.tools import tool
from langgraph.checkpoint.memory import InMemorySaver
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_core.messages import HumanMessage
# Gemini 2.5 Flash 已具備多模態能力,能處理圖片與文字
model = init_chat_model("gemini-2.5-flash", model_provider="google_genai")
# 新增美食顧問 Agent
cuisine_agent = create_agent(model=model,
tools=[],
system_prompt="你是美食顧問,能閱讀菜單圖片、翻譯內容並推薦代表性料理。",
checkpointer=checkpointer)
# CuisineAgent 包裝成 Tool 作為子 Agent供 Supervisor 呼叫,能夠分析菜單圖片並依飲食偏好推薦料理
@tool("CuisineAgent", description="分析菜單圖片並依飲食偏好推薦料理")
async def call_cuisine(image_path: str, dietary_preferences: str):
with open(image_path, "rb") as f:
encoded = base64.b64encode(f.read()).decode("utf-8")
msg = HumanMessage(
content=[
{"type": "text", "text": f"請分析這張菜單並推薦一道經典維也納菜。飲食偏好: {dietary_preferences}"},
{"type": "image_url", "image_url": f"data:image/jpeg;base64,{encoded}"},
]
)
result = await cuisine_agent.ainvoke({"messages": [msg]},
{"configurable": {"thread_id": "1"}})
print("\n[CuisineAgent] 輸出:", result["messages"][-1].content)
return result["messages"][-1].content
# Supervisor 呼叫子 Agent,加入飲食偏好
supervisor = create_agent(
model=model,
tools=[call_weather, call_planner, call_cuisine, call_advisor],
system_prompt=(
"你是旅行統籌助理。根據使用者需求,自行決定何時呼叫氣象、行程、美食與顧問專家。"
"最後整合所有子 Agent 結果,輸出完整建議。"
"使用者不吃牛肉,請避免推薦含牛肉的菜餚。"
),
checkpointer=InMemorySaver(),
)
# 主程式:提供菜單圖片供 Supervisor 規劃行程並推薦餐點
menu_path = "figlmüller_菜單.png"
result = await supervisor.ainvoke({
"messages": [{
"role": "user",
"content": f"幫我規劃維也納一日遊,請考慮天氣與行程,並分析我上傳的菜單圖片推薦餐點,且我不吃牛肉。菜單路徑:{menu_path}"
}]
}, {"configurable": {"thread_id": "1"}})
print("\n=== 最終整合輸出 ===")
print(result["messages"][-1].content)
這段程式在原有的 Supervisor × Multi-Agent 架構中,
新增具多模態能力的 CuisineAgent(美食顧問),
讓系統能「看懂菜單」並根據使用者飲食偏好推薦料理。
核心做法如下:
create_agent() 建立 CuisineAgent,負責讀取菜單圖片、翻譯內容並推薦料理。@tool("CuisineAgent") 將其包裝成可被 Supervisor 呼叫的工具,dietary_preferences)如不吃牛肉,過濾不適合的餐點。這讓旅遊助理不只懂文字,也能看懂圖片、理解偏好,展現多模態的決策能力。
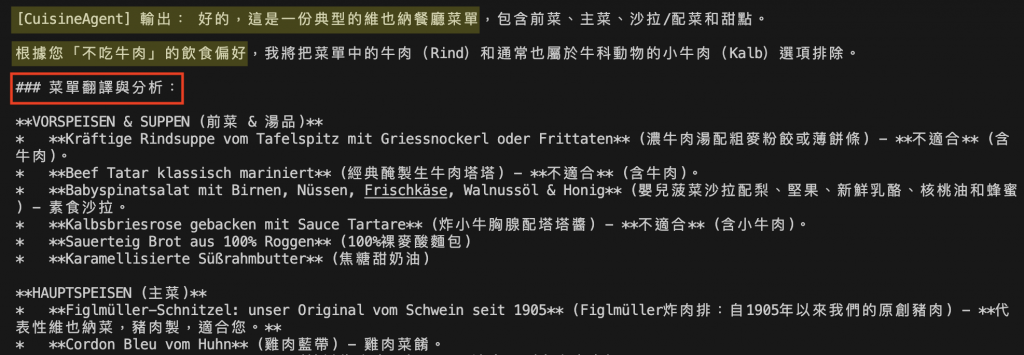
圖:CuisineAgent 分析 Figlmüller 菜單的多模態輸出。模型從圖片中辨識出德文菜名與成分,並依使用者「不吃牛肉」的偏好自動排除含牛肉與小牛肉的選項,生成對應的中文翻譯與註解。

圖:Supervisor 整合氣象、行程、美食三位專家結果後的最終建議。除了行程規劃與天氣建議外,系統也根據菜單內容推薦「Figlmüller 炸肉排」與甜點「Kaiserschmarrn」,展現多模態與多 Agent 協作的整合能力。
在這次的 Demo 結果,CuisineAgent 透過 Gemini 2.5 Flash 模型成功從圖片中讀取菜單文字,
並根據使用者的飲食偏好(不吃牛肉)自動過濾不適合的餐點,
接著由 Supervisor 整合氣象、行程與美食建議,
輸出包含天氣穿著建議、行程規劃與推薦料理的完整旅遊提案。
這顯示多模態 Agent 不僅能理解圖像資訊,
更能與其他專家協作,根據語意與偏好生成個人化建議,
讓 AI 從「能看懂圖片」進一步邁向「能理解情境與需求」。
今天,我們讓旅遊助理從「理解文字」進化為「理解世界」。
透過 LangChain v1.0 × Gemini 2.5,AI 不再只侷限於文字對話,
而能觀察、分析與推理現實世界的資訊。
這次實作展示了三項重要進展:
多模態理解(Multimodal Understanding)
模型能同時處理文字與圖片,例如從菜單影像中辨識文字、翻譯內容,並據此生成餐點建議。
專家協作(Multi-Agent Collaboration)
旅遊助理不再單打獨鬥,Supervisor 能整合氣象、行程、美食顧問等多位專家,形成分工明確的決策流程。
偏好導向(Personalized Reasoning)
系統能根據使用者飲食偏好(如不吃牛肉)自動篩選與推薦,提供更貼近個人需求的互動體驗。
這代表 AI 正從 語言理解(Language Understanding)
邁向 感知理解(Perceptual Understanding) 的新階段——
AI 不只是能對話的助理,更是能觀察、思考、理解世界的旅伴。

圖:維也納工業大學(Technische Universität Wien)夜景。立面上的古典雕像在燈光下浮現,每一尊都象徵著理性、工藝與學問的精神。這座融合藝術與科學的建築,如同多模態系統中協作的各個 Agent——各自專精、彼此呼應,在光影與結構間共同展現「理解世界」的智慧與秩序。(攝影:作者自攝)

 iThome鐵人賽
iThome鐵人賽