目前為止,我們建立了完整的 Observability 2.0 架構:從資料收集(OTLP)、儲存(Parquet + Iceberg or S3 Table)、處理(Schema 設計與轉換)到視覺化(Grafana)。但這些架構都有一個共同前提,就是應用程式必須主動暴露 metrics、logs 或 traces。
如果應用程式沒有辦法主動暴露 signal 怎麼辦?再來,如果你想監控的不是應用程式,而是 Kernel 層級的網路封包、系統呼叫、或 CPU 排程行為呢?傳統的監控工具很難做到這些。
在鐵人賽的倒數四天,我們會介紹 eBPF (extended Berkeley Packet Filter),一個能在 Linux Kernel 中安全執行程式的技術。雖然短短三到四天的篇幅,要從零開始講述 eBPF,可能沒辦法講得全面與深入,但也希望藉由不同的視角,讓我對可觀測性工程有更全面的認識。
BPF (Berkeley Packet Filter, 為了和eBPF 做出區別也稱 Classic BPF) 是 eBFP 的前身,它是一個用在 Unix-like 系統上截取封包的架構。
在 BPF 尚未問世之前,截取封包的方式非常繁瑣且耗費系統效能:
舉例來說,如果你想用 tcpdump 抓取 port 80 的 HTTP 封包
tcpdump port 80
BPF 則可以解決這樣的問題,讓 User space 中的應用程式透過額外的程式,告訴作業系統要過濾掉哪些網路封包。這樣的手法讓封包可以在 kernel 層就決定是否過濾,而不用將每個封包丟到 User space 進行處理。
只不過,BPF 的能力就僅限於網路封包的處理,並且其支援的指令集非常有限。因此在 2014 年,Linux kernel 引入 eBPF(extended BPF)的概念,擴展更多的功能。
相較於 BPF 的單一功能,eBPF 允許開發者在作業系統 kernel 中執行自訂程式,同時確保這些程式是安全且受控的。能夠安全且高效地擴展 kernel 的功能,而不需要修改 kernel 原始碼或載入 kernel 模組。 從歷史來看,作業系統 kernel 一直是實作可觀測性、安全性和網路功能的理想場所,因為 kernel 具有監督和控制整個系統的能力。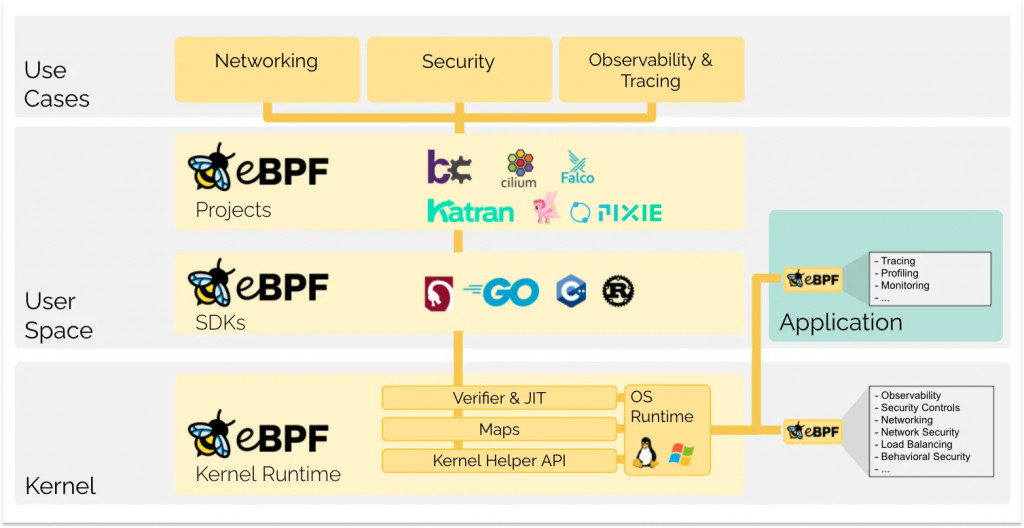
傳統上,想要在 kernel 層級加入新功能的創新速度,遠遠落後於在應用層實作的功能。 eBPF 從根本上改變了這個局面。透過 eBPF,開發者可以在不修改 kernel 原始碼的情況下,動態載入程式到 kernel 中執行。這帶來了幾個關鍵優勢:
由於 eBPF 是在作業系統運行時,才額外添加功能上去,所以開發者就不需要等待 kernel 本身的版本更新,就可以加入新的監控功能。這個支援在 Linux kernel 3.18 版本以後就可以使用。
雖然 eBPF 程式運行在 kernel space,但它不會像傳統的 kernel module 一樣有安全風險。載入 kernel module 如果有 bug,可能會導致 kernel panic、系統當機、記憶體洩漏、安全漏洞等風險。
eBPF 則透過 verifier 機制在載入前進行嚴格檢查,確保以下幾件事:
eBPF bytecode 在載入時會透過 JIT (Just-In-Time) compiler 編譯成原生機器碼,執行效能接近手寫的 kernel code。同時,eBPF 可以在 kernel 內直接做資料聚合和過濾,只把最終結果傳回 user space,大幅減少 context switch 和記憶體複製的開銷。
那麼 eBPF 是怎麼動態載入到 Kernel 上面的?在這邊,我們就必須談到 Hook 的概念。
eBPF 程式是事件驅動(event-driven)的。當 kernel 或應用程式執行到特定的 hook point 時就會被觸發。預先定義的 hooks 包括:
如果以上預先定義的 hooks 無法滿足需求,也可以建立 Kernel Probe (kprobe) 或者 User Probe (uprobe),兩者分別的用途就是分別掛載在 kernel 或者 user space 中的函式上。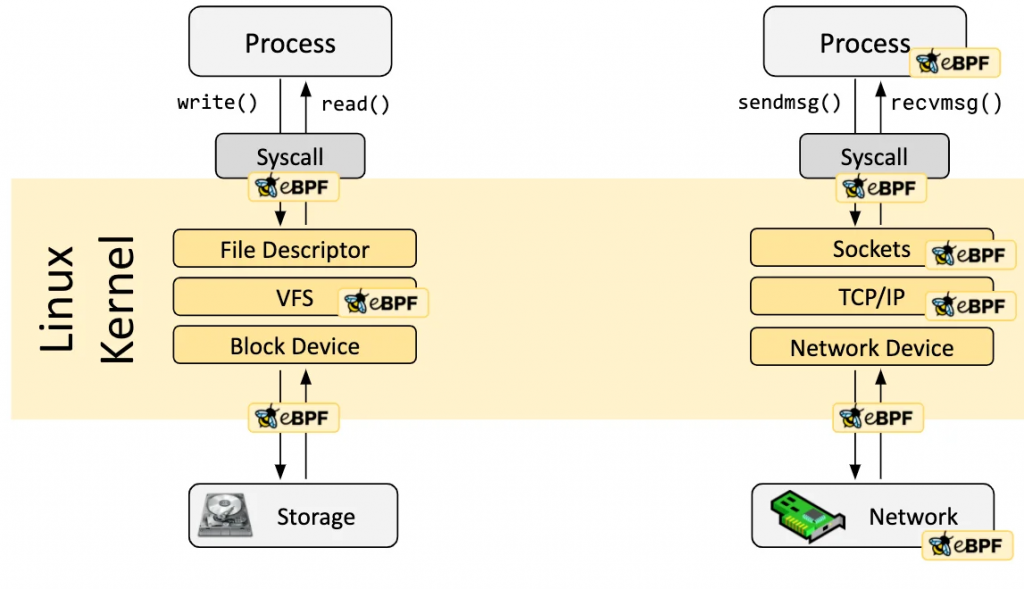
eBPF 可以掛載的各種 hook points,從 user space 的 process、system call 層、到 kernel 內部的 VFS、TCP/IP、網路設備層,幾乎涵蓋了系統的每個層級。
透過這些 hook points,eBPF 程式可以掛載在 kernel 或應用程式中的幾乎任何位置,實現全方位的可觀測性。
eBPF 讓我們能在不修改 kernel 或應用程式的情況下,收集系統各個層級的可觀測性資料。從 BPF 最初的網路封包過濾,到 eBPF 擴展到系統呼叫、kernel 函數、甚至 user space 的追蹤,eBPF 補足了傳統應用層監控看不到的盲點
而透過多樣化的 hook points,eBPF 可以在系統的關鍵時刻收集資料,實現從網路層到應用層的全方位可觀測性。接下來兩天,我們會看看如何使用 eBPF 工具收集實際的可觀測性資料,以及要如何將 eBPF 的資料和 OpenTelemetry 進行整合。
eBPF Documentation - What is eBPF?
Ian Chen - 初探 Linux Kernel 中的 BPF 與 XDP 技術:以 Tiny Load Balancer 為例
Linux kernel Documentation - Classic BPF vs eBPF
Linux kernel Documentation - eBPF verifier

