⚠️ 免責聲明
本文為學習與研究筆記,整合該論文主要內容與 2025 年 AI 安全趨勢。非正式教材;實際應用請依組織政策與法規。
大型語言模型(LLM)擅長生成文字,但無法真正「學習新經驗」。
要更新知識,必須重新訓練或微調,成本高昂。
ACE (Agentic Context Engineering)提出另一條路——
「不改變模型權重,改變它的情境。」
透過動態管理 Context (任務提示、回憶、策略),
讓 LLM 能在執行中自我調整、自我進化。
ACE 視 Context 為活體知識:
每次任務後,模型會反思並更新「策略筆記(Playbook)」。
| 階段 | 功能 | 比喻 |
|---|---|---|
| Generate | 產生行動或解答 | 學生解題 |
| Reflect | 檢視成果、分析失誤 | 回顧錯題本 |
| Curate & Update | 取精華、更新筆記 | 修訂筆記本 |
如此循環,模型能不斷自我優化,而非重訓。
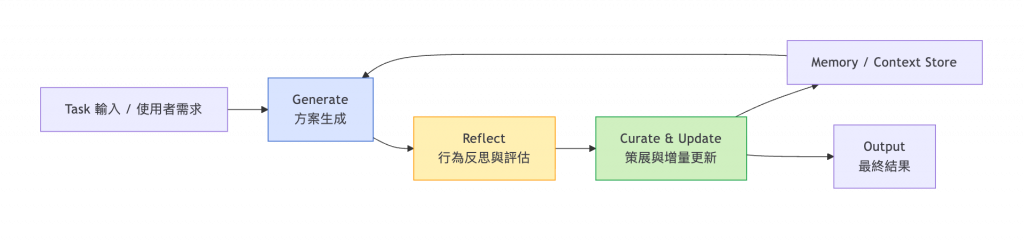
🎯 ACE 的核心是「循環學習而非重訓練」,
讓 LLM 具備持續成長與自修能力。
| 問題 | 說明 | ACE 解法 |
|---|---|---|
| 簡潔性偏誤 (Brevity Bias) | 為追求簡短 Prompt 而犧牲關鍵細節 | 透過 Reflection 與 Curation 保留重要上下文 |
| 情境崩潰 (Context Collapse) | 長期任務中,記憶反覆摘要導致資訊遺失 | 採 Incremental Update 分頁式增補,保留細節 |
ACE 是 Dynamic Cheatsheet (動態小抄) 的延伸版。
| 功能 | Dynamic Cheatsheet | ACE 進化 |
|---|---|---|
| 學習來源 | 任務輸出 | 任務 + 回饋 |
| 更新方式 | 覆寫或重寫 | 結構化增量更新 |
| 智慧層次 | 儲存結果 | 儲存 + 推理策略 |
| 目標 | 提升單次推理 | 持續自我進化 |
AI 代理不需人工標註,而是依據執行結果自行學習。
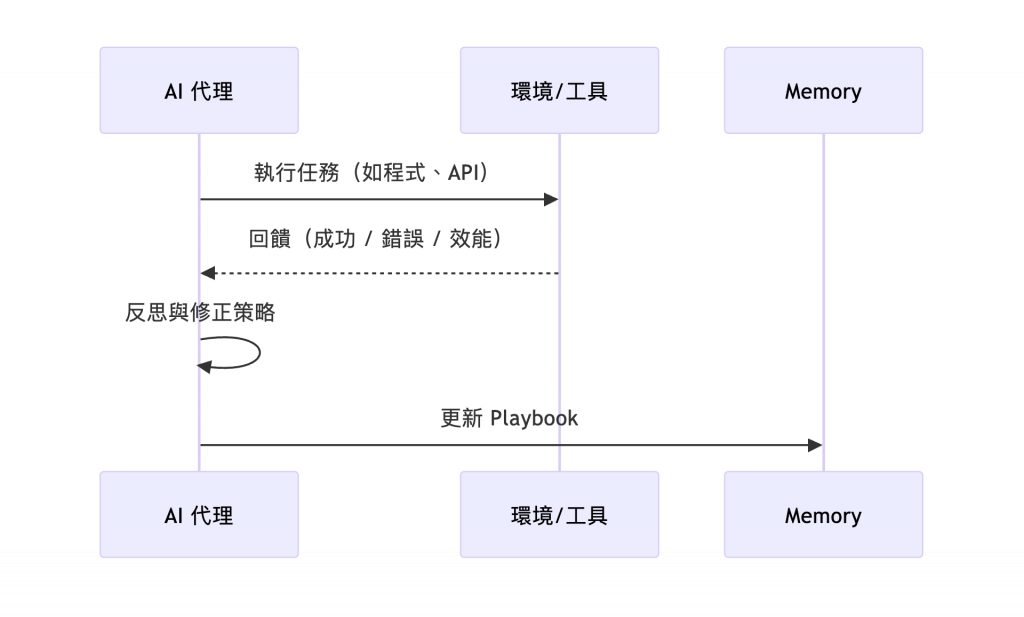
1️⃣ 生成 → 2️⃣ 執行 → 3️⃣ 接收 SyntaxError → 4️⃣ 反思 → 5️⃣ 修正邏輯 → 6️⃣ 成功通過測試。
這樣的回饋循環讓模型學會「從錯誤中學」。
ACE 本質上是一種 非梯度的結構化優化:
在高維語言空間中,藉由回饋信號調整「情境向量(Context Vector)」。
| 層次 | 對應技術 | 功能 |
|---|---|---|
| 表層 | Prompt Engineering | 控制輸入樣式 |
| 中層 | Context Adaptation | 動態選擇情境 |
| 深層 | ACE Optimization | 根據回饋演化情境空間結構 |
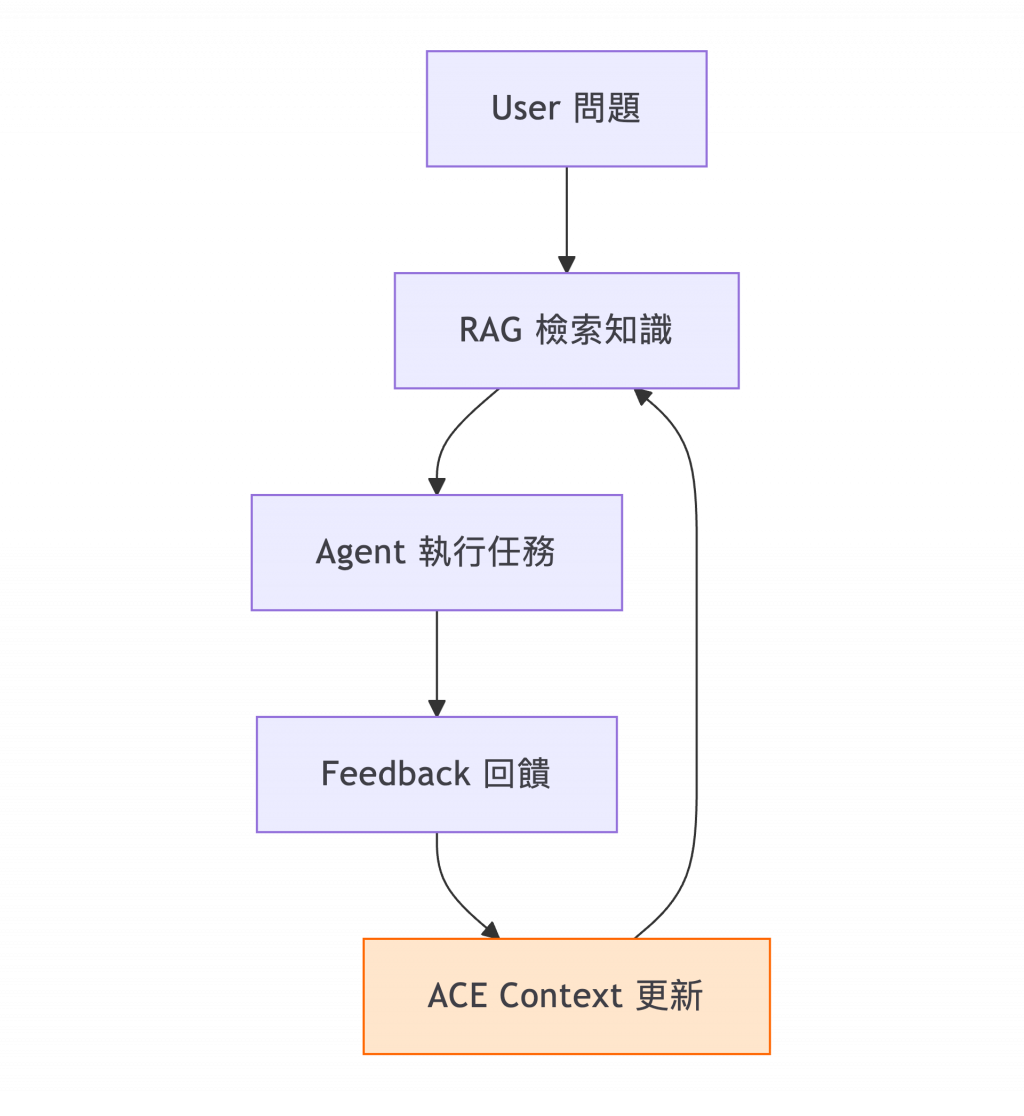
ACE 可作為 RAG 與 Agentic AI 之間的橋梁:
RAG 負責「知識檢索」,ACE 負責「知識演化」。
| 面向 | 潛在應用 | 風險 |
|---|---|---|
| 防禦 | 自主威脅獵捕與事件回應(SOC 自我優化) | 過度自動化導致誤封 |
| 攻擊 | 自我學習型惡意軟體 | 失控進化、規避偵測 |
| 治理 | 模型審計與可追溯 | 回饋信號被操縱 |
🧠 ACE 既是防禦利器,也是攻擊放大器。
關鍵在於 誰控制 Feedback 與 Playbook 的策展權。
| 項目 | 傳統 LLM | Fine-Tuning | RAG | ACE |
|---|---|---|---|---|
| 是否改動權重 | 否 | 是 | 否 | 否 |
| 知識更新方式 | 固定 | 再訓練 | 檢索 | 自我演化 |
| 學習來源 | 提示資料 | 標註樣本 | 外部知識庫 | 執行回饋 |
| 可解釋性 | 高 | 低 | 高 | 高 |
| 成本 | 低 | 高 | 中 | 中低 |
| 長期適應力 | 弱 | 中 | 強 | 最強 |
1️⃣ Self-Improving Agents:多代理協作下的集體 ACE。
2️⃣ Context Compression 研究:如何在長期記憶中避免崩潰。
3️⃣ 安全治理 (LLM Auditing):確保 Feedback 來源真實可信。
4️⃣ 標準化接口:推動 ACE API 與 LangGraph 兼容。
ACE 讓 AI 從 「模仿人」 進化為 「學習者」。
以前,我們教 AI 回答;
現在,我們教 AI 思考;
未來,我們讓 AI 自己學會教自己。

