上線快一個月,James 比較有時間,便想要針對 Stored Procedure 執行過久的問題進行調整。
之前因為趕著將案子如期上線,而這一段的執行時間也不會影響到簽核過程,所以針對 SQL 效能的部份並沒有花太多時間進行調整。
James 開啟 SQL Server 的 Query Analyzer(註1),並將 Excution Plan 選項打開,開始執行相關的 Stored Procedure,執行了一會兒,指令執行完畢,James 切換到 Excution Plan 視窗查看,並發現其中 sp_PO_resale_fcst 這一個程序的執行時間最久。(圖1)

圖1:Stored Procedure 執行 Excution Plan
James 發現,在這邊出現了 Bookmark Lookup,而且耗用了大部分的執行時間。(圖2)

圖2:Bookmark Lookup 耗用時間
於是 James 打開索引管理視窗,看看之前針對 sold_a 這個 Table 所建立的 Index,並沒有符合 Stored Procedure 中的查詢條件,而且每天重新 Create 的 sold_a Table 並沒有定義 Primary Key 以及叢集式索引。(圖3)
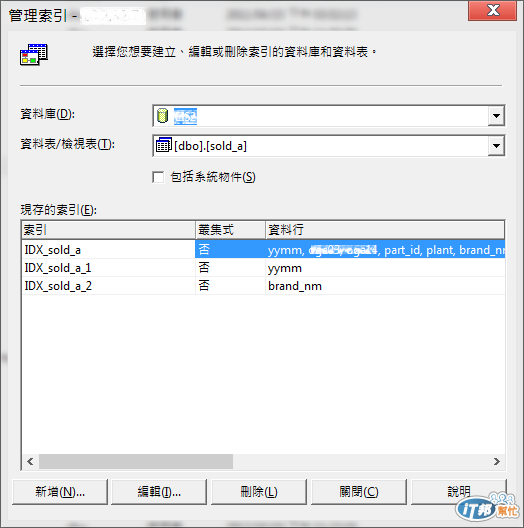
圖3:索引管理
於是 James 新增一個索引包含查詢條件中的兩個欄位,但執行後並沒有多大的改善。(圖4)
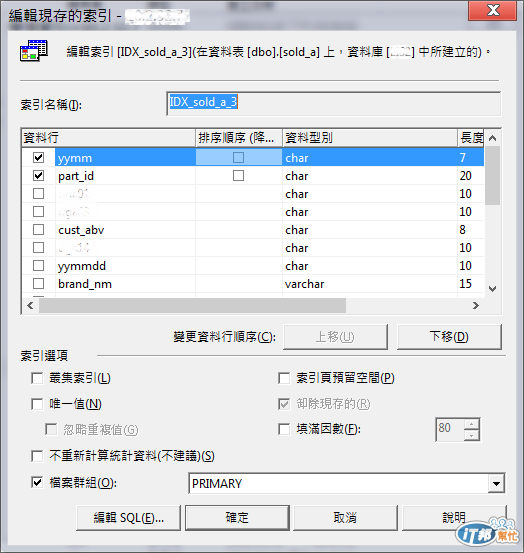
圖4:NonClustered Index
James 於是將新增的 Index 改為叢集式索引(Clustered Index)(圖5)(註2),並指定使用 IDX_sold_a_3 這個 Index,重新執行 Stored Procedure。
select isnull(sum(qty),0) from sold_a with (Index(IDX_sold_a_3)) ...
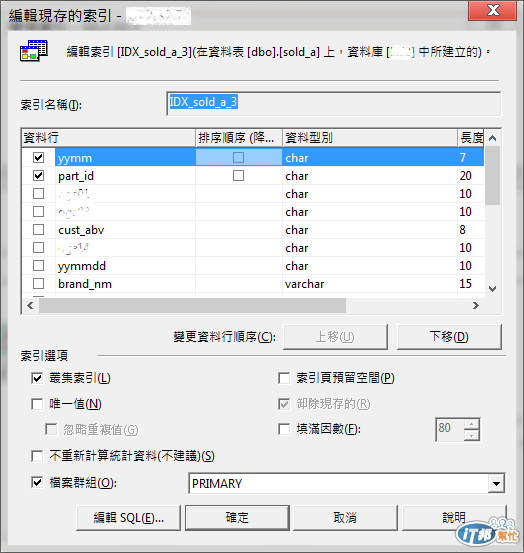
圖5:Clustered Index
再次執行完的結果,Bookmark Lookup 已經不見了,執行時間也順利的縮短(圖6),也確實使用到 IDX_sod_a_3 這個 Index(圖7),到此 James 終於可以比較放心了。

圖6:Stored Procedure 執行 Excution Plan
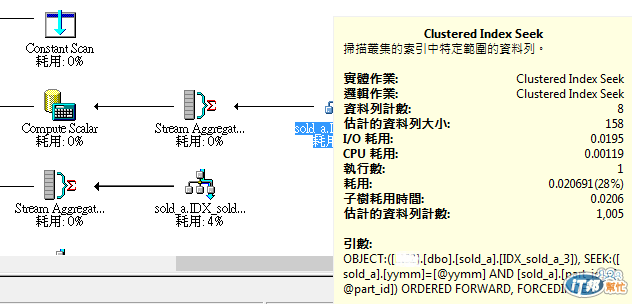
圖7:指定 Index
參考資訊:
2.善用索引提升查詢之效能 - Microsoft Performance Impact: Bookmark Lookup is Expensive - Even in Memory
註1:Query Analyzer 為 SQL Server 2000 的 SQL 工具
註2:SQL Server 2005 提供了 Convering Index 的功能,來輔助 Clusterd Index 只能有一個的不足
其實
索引一直是我多年以來的不滿
有多不滿呢
我開發的系統
從來不建索引
「那performance很差怎麼辦」
我才不管他呢
我是資料庫的「使用者」
我只負責下SQL
performance是資料庫自己的事
我在IBM VSAM要建索引
到了dBASE III Plus要建索引
到了RDBMS還要自已建索引
幾十年下來
資料庫系統自已都不改進了
還要使用者自已建索引
Performance不好還怪使用者沒建好索引

對於堅持認為索引是使用者的責任的人
我還有一個例子
使用了這麼久的Google
Google從來沒有要求使用者自己建過任何一個索引吧

相較於Google處理資料內容的多樣性
RDBMS面對的資料內容算是很「規律」了
而RDBMS可以很輕易地知道
「最常使用的是那些SQL指令」
「執行效能最差的是那些SQL指令」
知道了這兩項資訊
就該自動tunning執行效能
要自動建立索引也行

打完字發現寫了落落長一篇
真是老了
愛碎碎唸碎碎唸碎碎唸碎碎唸

所以才會有 DBA 這種角色出現...
antijava提到:
愛碎碎唸碎碎唸碎碎唸碎碎唸
我懂...
回應 antijava
在SQL Server 有資料庫引擎調校顧問(Database Engine Tuing Advisor, DTA), 有需要的大大可以學習使用看看;
但是當一個工具沒有百分之百正確時, 及對資源相當掌控時, 無法全自動化時需要人為適當判斷及參數.
以一個DBA對建立索引的認知來說:
當一個索引建立需要花費1個小時的時間, 若是離線建立則此段時間會造成相關表格無法交易, 若是線上建立則也會衝擊到資料庫效能, 因此需要人為去評估什麼是適當建立時間.
建立索引時需要使用大量的記憶體和暫存空間, 還有此索引所在的資料檔案的空間, 這些也是需要作業系統的配合才行.
以一段SQL 來說, 在上千筆的要格中, 讀取一筆資料或一個區間資料, 都要透過索引才能獲後良好效能, 除非是趨近於全表掃描, 才可以不需透過索引獲得良好效能; 所以當寫一段SQL進入資料庫要能有意識到用那個索引, 甚至會開立好索引, 才是下精準SQL, 才是一個好的使用者.
再以建立索引的時機, 理應是伴隨一段SQL的需求, 理想上是在新的SQL進入資料庫前, AP將此SQL知會DBA來評估建立索引; DBA 收到了此段SQL 在去評估相關表格及欄位(也就是人工的DTA工作), 及規劃建立資源, 時機, 及減輕對使用單位衝擊(公告維護時間).
在一般公司的環境上, 通常只有AP人員配置而沒有DBA人員配置, 往往是資深人員來充當資料庫設定的角色; 既然是資深人員對資源要有相當的掌控, 不是你我願不願意, 而是瞭解資料庫對AP人員來說是加分很大的.
charmmih提到:
在SQL Server 有資料庫引擎調校顧問(Database Engine Tuing Advisor, DTA), 有需要的大大可以學習使用看看;
別開玩笑了
我連索引都不建了
怎麼會去學這個呢

有時對有些不會建索引的程式開發大哥,
我心中會碎碎唸....
又是一位 "射後不理的大哥"...
你講的各項考量各項技術我都贊成,都沒意見
我的意見是
「這些該是RDBMS的工作還是使用者的工作」
經過幾十年的發展
RDBMS除了剛開始推出SQL語法
讓使用者不用自已在那裡seek來seek去之外
就再也不求長進了
我舉幾個很簡單例子
Web Server
FTP Server
SMTP Server
以上三個Server要處理搜尋的資料
某種程度上來看也不比DB Server單純到那裡去
但是
當你要Tunning以上三個Server的performance時
頂多只需要針對「整體環境」去改config
而不需要「依據資料內容」去調整設定
只有DBA這項職務
沒有聽過什麼WEBA, SMTPA, FTPA的職務
這究竟是RDBMS真的有那麼特別複雜
還是只是沒有人去challenge RDBMS的懶惰不長進
RDBMS已經發展到
連Left/Right/Inner/Outer Join來join去的sql指令都看得懂
連Query Analyzer和「調校顧問」都做得出來
難道
就沒辦法自己Tunning performance
要把責任推到使用者身上嗎
charmmih提到:
理應是伴隨一段SQL的需求, 理想上是在新的SQL進入資料庫前, AP將此SQL知會DBA來評估建立索引; DBA 收到了此段SQL 在去評估相關表格及欄位(也就是人工的DTA工作), 及規劃建立資源, 時機, 及減輕對使用單位衝擊(公告維護時間).
- 在一般公司的環境上,...(恕刪)
認同 charmmih 大的說法,DBA 的角色不僅在於提供系統良好的效能,對於資訊安全與稽核上的把關效用更大,也如同 charmmih 大第五點所提,現實環境中,很多都是校長兼撞鐘,湊活湊活,了解資料庫對 AP 開發人員來說,確實是加分,但這也暴露很大的風險,無從稽核...
antijava提到:
這些該是RDBMS的工作還是使用者的工作
antijava 大提出了一個相當值得思考的問題,RDBMS 主宰了企業應用幾十年了,效能為何一直都是企業應用系統的一個 issue!
也難怪乎 NoSQL 一再的被提出,不過就像當年的國語教育的推行一樣,我們逐漸忘了什麼是根本,什麼是自然...
「這些該是RDBMS的工作還是使用者的工作」
當你在學java時, 要深入研究JVM, 要學著耗用最少資源, 讓執行效能變快;
同時, 當我在學SQL時, 要深入研究RDMS, 要學著耗用最少資源, 讓執行效能變快;
只是, 你我有興趣深入研究的範疇不一樣而已.
經過幾十年的發展
RDBMS除了剛開始推出SQL語法
讓使用者不用自已在那裡seek來seek去之外
就再也不求長進了
當我是java門外漢時, 我也不知道JVM 長進什麼,
只知道是在OS層上會的VM, 好像效能方面不比其他原生程式.
當我沒有在此區塊耕耘時, 往往也是霧裏看花.
舉例來說, 以SQL資料庫最近幾年有下列進步, 有興趣google一下..
維護效能改善: always on ,HA, mirror,parition tabll/index, backup compression...
執行效能改善: clustered index, include index, where condition , table compression(row/page)...
才疏學淺, 未能詳列.
其實答案, 就在問題中....
Web Server
FTP Server
SMTP Server
以上三個Server要處理搜尋的資料
某種程度上來看也不比DB Server單純到那裡去
但是
當你要Tunning以上三個Server的performance時
頂多只需要針對「整體環境」去改config
這是系統管理範疇, 和資料庫一樣,
都要對 CPU, MEMORY, I/O Disk, Networking 的系統資源做設定,
只是一般 Server 用預設值就是可用狀態了....
而不需要「依據資料內容」去調整設定
當資料庫的資料成長量由 100MB -> 1GB -> 10GB -> 100GB -> 500GB 時,
那就要想想當初程式上線時, 壓力測試有沒有測到如此 ?
是不是要 「依據資料內容」去調整設定
ps: 先回答到此...
jamesjan提到:
SQL Server 2005 提供了 Convering Index 的功能,來輔助 Clusterd Index 只能有一個的不足
Convering Index(覆蓋索引)是一個觀念, 是SQL所用到的欄位均在索引中, 也就是索引就是基礎表格的經過排序的分身(小型表格), 此段SQL 並不會再需要去抓基礎表格, 舉例如下:
CREATE NONCLUSTERED INDEX IX_CUSTOMER_NAME ON CUSTOMER(NAME,ID);
select ID from CUSTOMER where NAME like '王%' (O)
select ID from CUSTOMER where NAME like '王%' order by TEL (X)
我認為索引有些演進, 值得關注並善加利用.
SQL 2000 每個表格某有一個叢集索引, 數個非叢集索引
SQL 2005 加入包含欄位(include field)
SQL 2008 加入條件子句(condition clause)
感謝 charmmih 的回覆,也讓我學習到很多

charmmih提到:
Convering Index(覆蓋索引)
筆誤, 是 Covering Index ...




 iThome鐵人賽
iThome鐵人賽