上一篇R語言基礎Part4,我們認識了R語言的資料型別及自動推斷,在實戰機器學習或是資料視覺化時,更常遇到的是這些資料型別的集合;在.NET中,常見的集合有基本的清單、陣列、字典也包含Queue(FIFO)及Stack(LIFO)等資料結構,我們來試試幾種R語言資料集合:
我們在資料夾MyR新增一支Day10.R
向量是1維的資料集合,只會包含一種型別元素 ,用C#語言來說 C# list<string> list<int>...
如果輸入時有不同的型別,R語言會自動隱含轉換為優先順序較高的型別(logical -> numeric -> character)。
在Day10.R中輸入程式碼
# Create a vector
pokerK <- c("David", "Charlemagne", "Caesar", "Alexandre")
print(pokerK)
# Get the class of the vector
print(class(pokerK))
執行結果: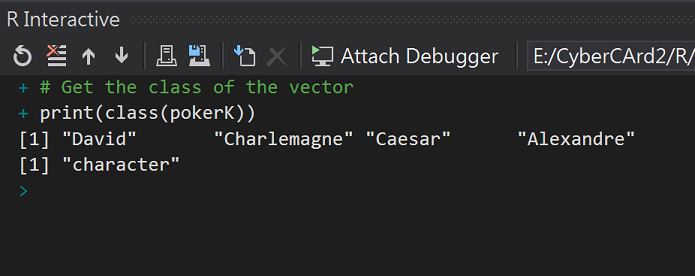
Class=character
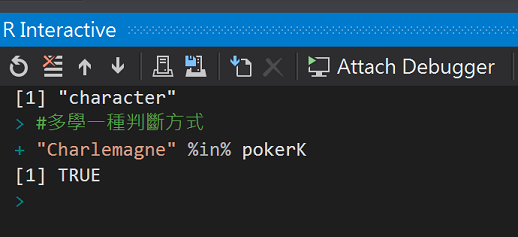
多學一種判斷方式,來試試法蘭克國王查理曼是否在撲克牌老k中?
"Charlemagne" %in% pokerK
list清單:1維的集合,可以包含很多R-object,也因此可以存放不同型態的值
List<object>
在Day10.R中輸入程式碼
#Create a list
list1 <- list(DOB = c("BC1000", "AD768", "BC100", "BC356"), Score = 100, Name = pokerK)
# Print the list
print(list1)
# Get the class of the list
print(class(list1))
執行結果: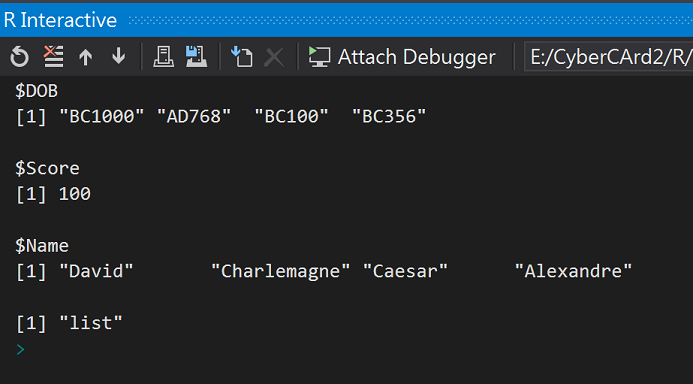
Class=list
矩陣:2維的集合
在Day10.R中輸入程式碼
# Create a matrix
M = matrix(c(1, 2, 3, 4, 5, 6), nrow = 2, ncol = 3, byrow = TRUE)
print(M)
# Get the class of the matrix
print(class(M))
執行結果: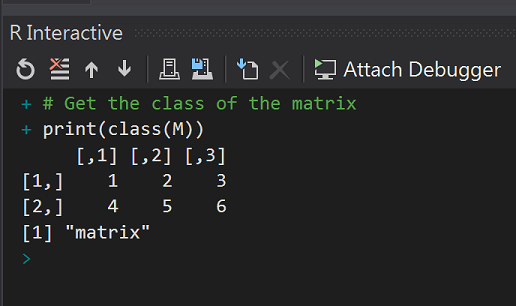
陣列:相較矩陣的2維,陣列則是可以指定更多維度的集合(列、行、維度),
不過也和向量(vector)相同,只會包含一種型別元素。
在Day10.R中輸入程式碼
# Create an array (2個3x1的矩陣)
a <- array(c('black', 'white'), dim = c(3, 1, 2))
print(a)
# Get the class of the matrix
print(class(a)
執行結果: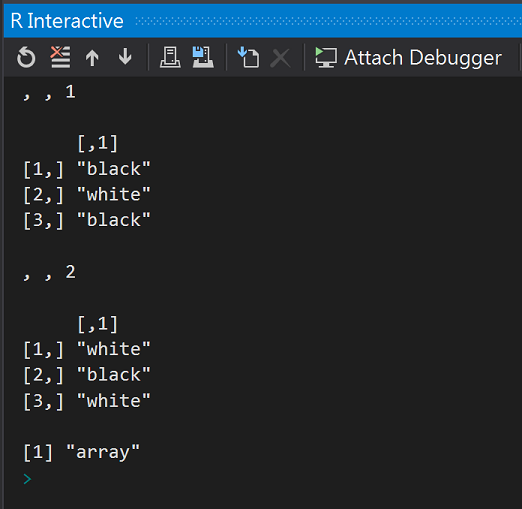
Class=array
因子:把向量的元素取唯一後作為標籤
在Day10.R中輸入程式碼
# Create a vector
country <- c('US', 'US', 'JP', 'JP', 'GB', 'TW', 'FR')
# Create a factor object
factor_country <- factor(country)
# Print the factor
print(factor_country)
# Count the Levels
print(nlevels(factor_country))
print(class(factor_country))
執行結果: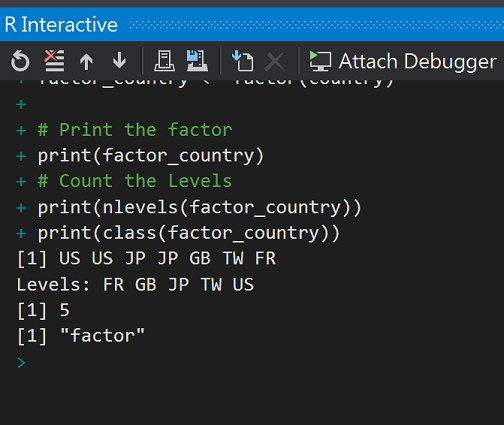
取唯一後,國別剩FR、GB、JB、TW、US,資料也排序了!
Class=factor
資料框: 用C#語言來說 DataTable
最常使用。
在Day10.R中輸入程式碼
# Create the data frame.
BMI <- data.frame(
gender = c("Male", "Female", "Female"),
height = c(176, 171.5, 165),
weight = c(70, 53, 49),
Age = c(37, 33, 28))
print(BMI)
print(class(BMI))
執行結果: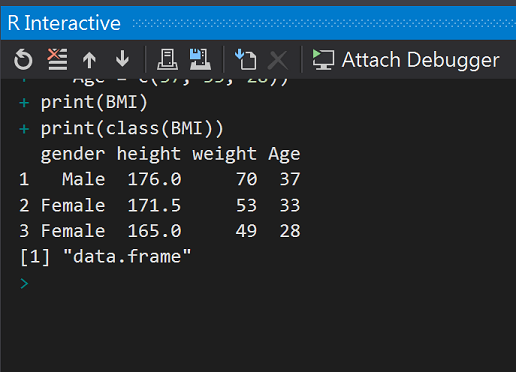
Class = dataframe
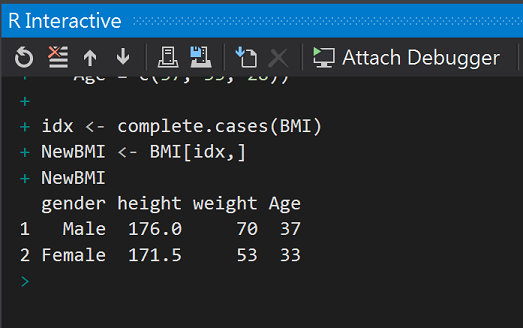
n種資料型態n維,1種資料型態n種資料型態要使用的函式就是complete.cases
#去除集合中的NA
BMI <- data.frame(
gender = c("Male", "Female", "Female"),
height = c(176, 171.5, NA),
weight = c(70, 53, NA),
Age = c(37, 33, 28))
idx <- complete.cases(BMI)
NewBMI <- BMI[idx,]
NewBMI
呼~10天了!加油!
整齊滿開的花田
2016.07 攝於 四季彩之丘,北海道,日本



 iThome鐵人賽
iThome鐵人賽