上一篇我們複習了R語言資料集合,裡頭可以住著許多整理好的型別們並且存放著資料,不過有時會臨時增加資料行(欄位)、增加資料列,又或者篩選資料等等,我們今天依序來複習幾種常用的資料集合指令,救出高塔中長髮公主。
為了方便學習,我們直接選最常使用到的dataframe(資料框)做練習,另外從微軟關聯式資料庫SQL Server資料庫輸入進來的資料型態也是dataframe。
 '
'
這邊我們要用iris及自建的簡單資料集,Iris是R語言內建的資料集, 經常使用在幾種機器學習演算法中作為範例。
iris資料集有150筆生物樣本觀測值 ,中文是鳶尾花,共有5個資料行,前4個資料行(欄位)是作為定量分析的特徵(花萼+花瓣長寬),最後1個是亞種:
#http://archive.ics.uci.edu/ml/datasets/Iris
#如果要模擬一種新的演算法,也可以從UCI 加州大學網站下載適合的資料集。
在Day11.R中輸入程式碼
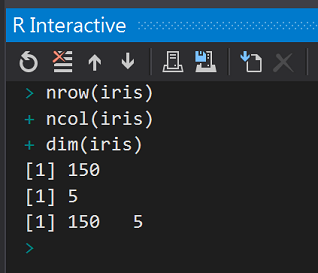
#(1)查看一下iris結構
nrow(iris)
ncol(iris)
dim(iris)
執行結果: 查看資料列、資料行個數。
在Day11.R中輸入程式碼
names(iris)
str(iris)
執行結果: 顯示欄位名稱、dataframe 結構(structure)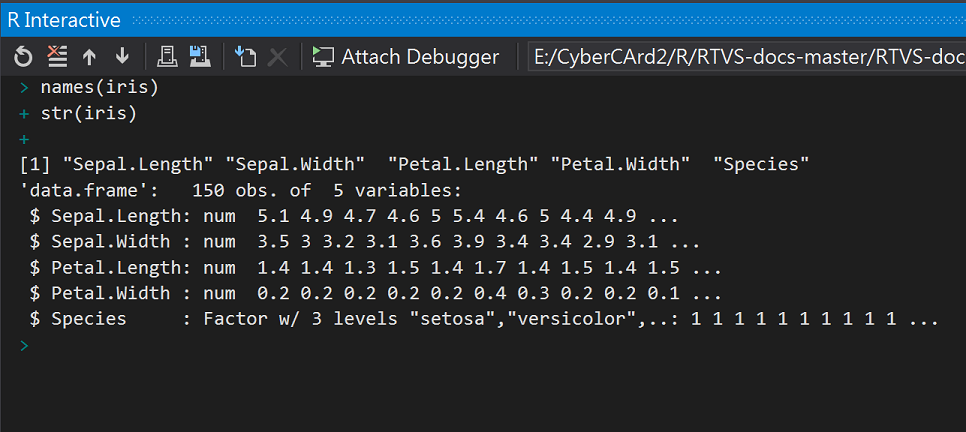
有時會把幾個向量(vector)結合成dataframe,集合的方式有資料列(row),也有資料行(column),我們來複習!
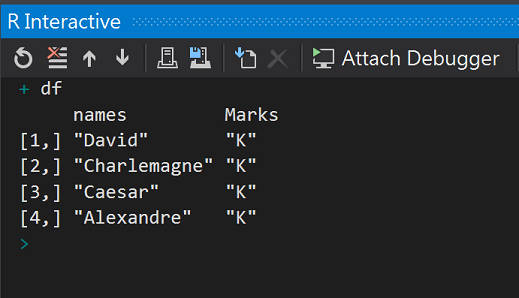
在Day11.R中輸入程式碼
names <- c("David", "Charlemagne", "Caesar", "Alexandre")
Marks <- c("K", "K", "K", "K")
df <- cbind(names, Marks)
df
執行結果: 2個資料行合併完成!
在Day11.R中輸入程式碼
#先製作1筆資料
dfQueen <- data.frame(names = "Athena", Marks = "Q")
dfQueen
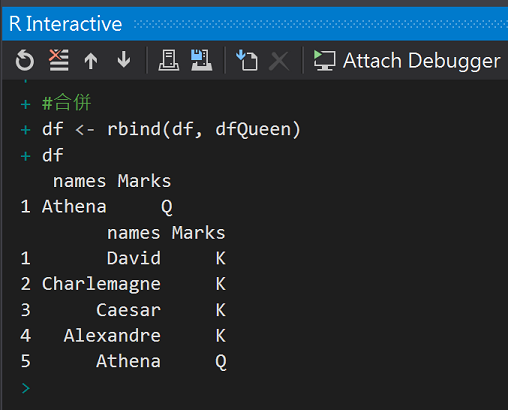
#合併
df <- rbind(df, dfQueen)
df
執行結果: 先產生雅典娜1筆資料的dataframe(dfQueen),然後合併到剛剛的dataframe(df)
如果想要取幾筆資料列出來面對廣大的粉絲?
在Day11.R中輸入程式碼
#(4)row index (列)
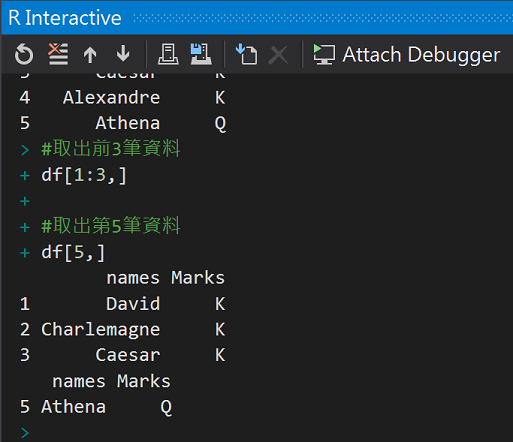
#取出前3筆資料
df[1:3,]
#取出第5筆資料
df[5,]
執行結果:
前面複習了取出指定資料列,接著我們直接下場實戰。
當我們在訓練模型時,如果想要很快取得模型貼近真實模擬的正確率(回測) ,我們可以將觀測出的樣本直接分為2組進行樣本外測試(out of sample test)
#訓練組樣本 ,通常的比例是70%-80資料。
#測試組樣本 ,剩下來的20-30%,用來驗證模型的正確率。
在Day11.R中輸入程式碼
#先取得資料框的筆數
n <- nrow(df)
#抽樣選出index
t_idx <- sample(seq_len(n), size = round(0.8 * n))
#訓練組樣本
traindatatraindata <- df[t_idx,]
#測試組樣本
testdata <- df[ - t_idx,]
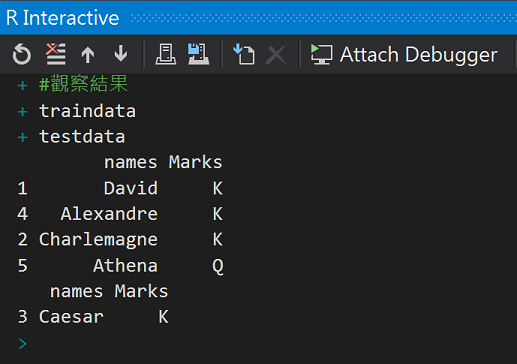
#觀察結果
traindata
testdata
訓練組4筆(80%,測試組1筆(20%)
如果想要取得特定資料行(欄位)的資料出來面對?
在Day11.R中輸入程式碼
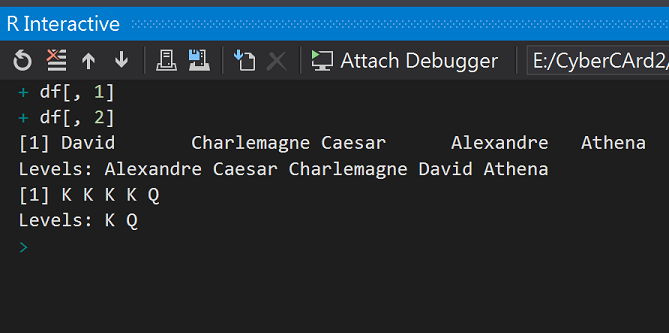
#(5)column index (行)
df[, 1]
df[, 2]
執行結果: 分別取出5個人物名稱和5個撲克牌號碼
比較推薦用$取,還有智慧提示intellisense
df$Marks
執行結果: 取出第5筆資料的人物名稱:雅典娜和5個撲克牌號碼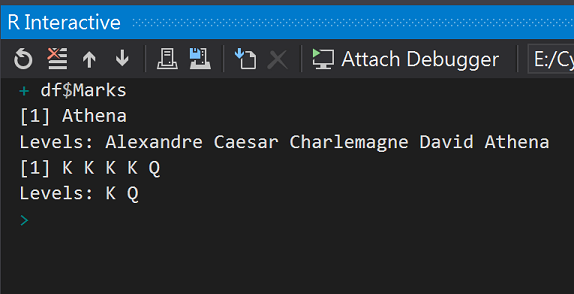
在Day11.R中輸入程式碼
#(6)filter條件
df_sub <- subset(df, Marks == "K")
df_sub
執行結果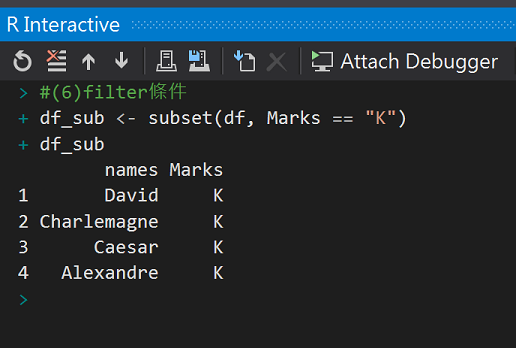
在Day11.R中輸入程式碼
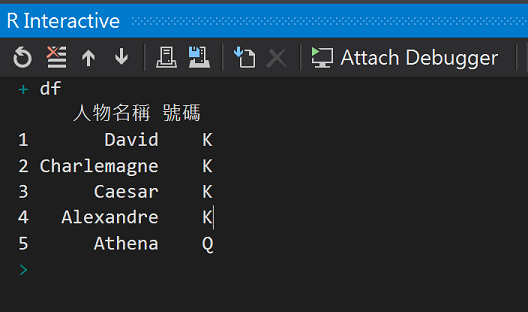
#(7)修改欄位名稱colnames
colnames(df) <- c("人物名稱", "號碼")
df
執行結果 : 欄位名稱被修改了!
如果有時間,推薦大家可以再多嘗試apply家族的函式,使用起來很方便。
呼~R語言的語法基礎終於要砍就了。
整理完畢以後就會很整齊了
2016-07 攝於日の出公園,上富良野,北海道,Japan



 iThome鐵人賽
iThome鐵人賽