word2vec 正如其名就是
word to vector 是一個能把文字變成向量的演算法.
用更口語的表達來說,
word2vec 是在做一項翻譯的工作,把詞(word)轉換成電腦可以了解的模式(vector).當然,如果它只有這項功能的話,並不需要特別把它拿出來講.最有趣的事情是 word2vec 在做翻譯這項工作的時候,他同時可以讀取出詞裡的概念.舉個 word2vec 的經典例子來說,當我們想到英國的時候,可能就會想到它的首都倫敦.而word2vec
在經過訓練以後是有能力做到這樣的推想的.更棒的是他的訓練速度非常快,因此實用價值非常地高.
而為什麼 word2vec 可以讀取出詞與詞的概念呢,這個跟他的演算方法有關.用一句話解釋就是他會把這個詞附近的相鄰詞考慮進來.實際上實作有兩種的演算法,第一種稱作 Countinuous Bag Of Words(CBOW),此方法會利用上下文的詞來當作神經網路的輸入,最後預測這個目標的詞是什麼.而第二種則是 Skip-Gram 演算法,剛好跟第一種演算法相反,他所輸入的是當前的詞來預測這一段的文章上下文的詞.這兩種演算法可以在使用 word2vec 的時候進行選擇,會有不同的效果.
讓我們用口語的方式再說明一次上述演算法的概念.我們現在從一篇文章隨機取出了兩個詞,在學習的過程中,這兩個詞分別的上下文會被導入 word2vec 來決定他們向量的數值.而這個向量是一個 N(本文取 100 來做測試) 個長度的數字.同一個詞,例如:台灣.向量值必定是一樣的.
在訓練的過程中,如果這兩個向量的上下文被判定為相似的,那 word2vec 會調整向量裡的數值來讓彼此在向量空間裡的距離拉近,而反之則會把他拉遠.
從這個概念裡面可以推想的到,最後學習完成的模型會把同樣概念的詞在向量空間裡面聚集在一起,這可能是國家的名稱例如:法國,英國,德國.而抽象的概念也會被聚集在一起例如:高興,快樂,愉悅.
因此學習完成後我們可以任意抽出兩個詞,並得到他的詞向量,並用詞向量來計算他們之間的距離.這個實際距離的概念也就是抽象意義上面他們兩個詞的相似性.所以我們可以說當這兩個向量數值是相似的時候.他在抽象意義上面的關係是很近的.
(編按:我們是如何計算兩個詞的相似性呢?word2vec 使用 Cosine Similarity 來計算兩個詞的相似性.這是一個 -1 到 1 的數值,如果兩個詞完全一樣就是 1.像是「台灣」這個詞和他自身的 Cosine Similarity 就是 1)
而除了比較相似性以外, word2vec 還可已有類推這個概念.從引用至 google open source blog 的圖來看,我們可以看到國家的距離是彼此相近的.中國,俄國,日本...等.而相對應首都的距離也是相近的.接下來就是有趣的地方了,可以觀察到每個國家和其首都的距離都是類似的.如圖中每條虛線的所示.那如果我們把這種對應關係改成數學上的表示的話就是.巴黎 - 法國 = 柏林 - 德國.這真的是非常酷炫的對應關係.所以我們可以在向量上面有這樣的表示方法 巴黎 - 法國 + 德國 = ? .聰明的你應該可以想到我們可以用這個方法來推斷未知國家的首都在哪
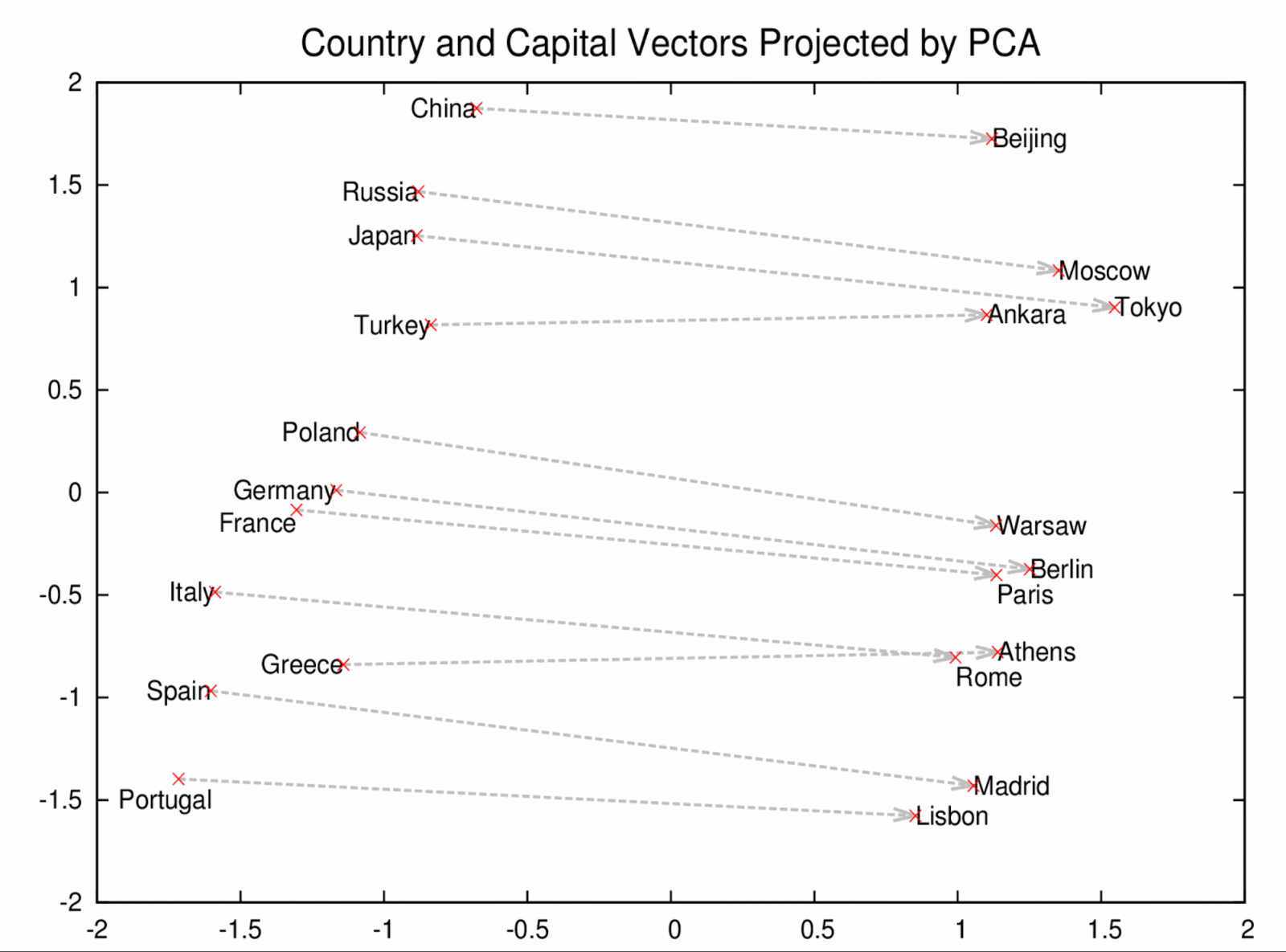
(圖片來源: google blog)
今天學習了 word2vec 的基本觀念,了解到把詞變成一個向量以後,可以根據語意做詞向量的加法減法得到新的詞向量.


