Well… 資料分析大概就是這樣,每當你回答了一個疑問,就會再產生更多的疑問等著你去分析...目前我們的商品名稱是這個樣子:”品項(品牌)” ,所以我們要把品名這個欄位拆成兩欄,分別是品項和品牌,這邊我們需要tidyr 這個library,利用裡面的separate ,將可以將欄位切開。
#install.packages("tidyr")
library(tidyr)
result <- orders %>%
mutate(Month = as.Date(orders$CREATETIME, "%Y-%m-%d %H:%M:%S")) %>%
mutate(Month = substring(Month,1,7)) %>%
separate(NAME, c("Category", "Brand"), sep="\\(")
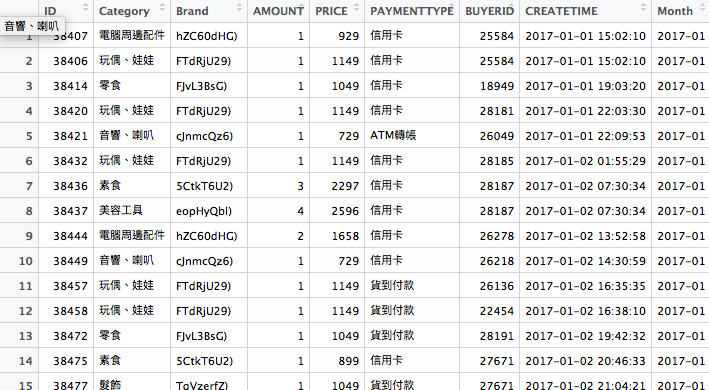
再來依照前幾天的教學,應該知道如果要用月份分可以用group_by(),但這次除了月份以外,我們還要依照Category 分,所以我們可以這樣子寫。
result <- orders %>%
mutate(Month = as.Date(orders$CREATETIME, "%Y-%m-%d %H:%M:%S")) %>%
mutate(Month = substring(Month,1,7)) %>%
separate(NAME, c("Category", "Brand"), sep="\\(") %>%
group_by(Month, Category) %>%
summarise(Income = sum(PRICE))
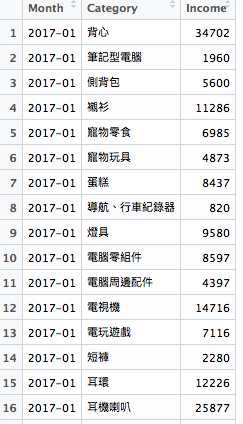
ok,我們用group_by()分好了時間與品項,不過這樣有779筆資料...,我希望可以Month變成行,Category變成欄,這時,就要介紹spread() 這個函式啦,
result <- orders %>%
mutate(Month = as.Date(orders$CREATETIME, "%Y-%m-%d %H:%M:%S")) %>%
mutate(Month = substring(Month,1,7)) %>%
separate(NAME, c("Category", "Brand"), sep="\\(") %>%
group_by(Month, Category) %>%
summarise(Income = sum(PRICE)) %>%
spread(Category, Income, fill=0)
spread()的第一個參數放的是欲被拆解的欄位,第二個欄位是被拆解之後它所代表的值,fill 則是代表如果這個欄位不幸沒有值,那他的預設值是什麼,這邊就給他0,然後把上面程式碼反白起來,按下command+enter, Bang!
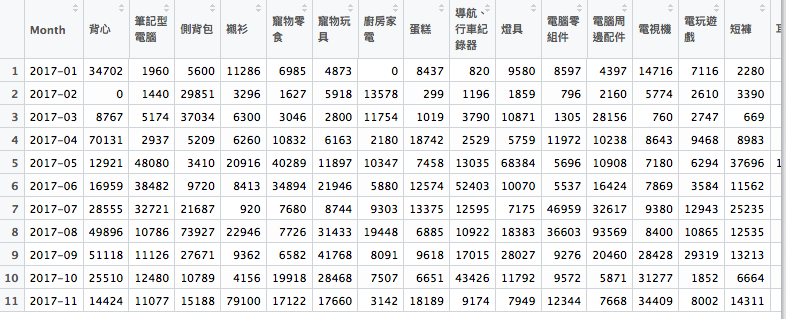
最後加上簡單的分析,就可以印出營收最高的商品囉!
category_sum = colSums(result[,-1])
highest_category_index = which(category_sum==max(category_sum))
print(paste0("Income最高的商品:",colnames(result[,-1])[highest_category_index]
))

ref:
day5原始碼


