提醒: code在這裡
這個部分其實跟資料整合很像,不過不一定要透過多個欄位的協作已產生新的欄位。舉例來說,我們現在有每個人的名字的資料,這份資料如果要讓電腦讀得懂,其實有一定的難度,以下試圖從這個欄位找出兩個Feature,第一個比較簡單: 名字的長度,第二個是稱謂的分類。
# title
title_mapping= {
'Ms':"Miss",
'Mlle':"Miss",
'Miss':"Miss",
'Mrs':"Mrs",
'Mme':"Mrs",
'MrsMartin(ElizabethL':"Mrs",
'Mr':"Mr"
}
title_cat = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
def applyfun(row):
row['Name_Length'] = len(row['Name']) ## 名字的長度
call = re.search(r'\,.+\.', row['Name']).group(0).replace(",", "").replace(".", "").replace(" ", "")
call_cat = title_cat.get(title_mapping.get(call, "Rare"))
row['Title'] = call_cat ## 稱謂
return row
df = df.apply(applyfun, axis=1)
之所以要做資料切片的原因是有時候有時候連續變數電腦來說不是特別友善,雖然現在機器學習中套件大都已經有很強的自動切片功能,但資料量如果比較大,效能是一個考量,另外透過資料切片新增Feature,嘗試看看有時候還真的可以增加預測的精準度。至於資料切片的切片方法,比較常見的有兩個方式,以下舉「票價」(Fare)這個欄位示範。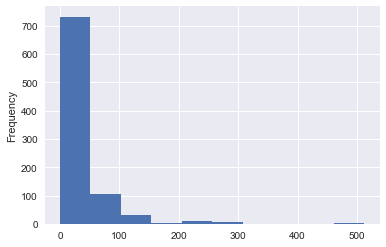
ranges = pd.cut(df['Fare'], 5) ## 回傳與原本索引對應的分類資料回來,如果覺得range太醜不好處理,可以把label設為False
df_Fare_discretization = pd.DataFrame(list(Counter(ranges).values()), columns=['count'], index= list(Counter(ranges).keys()))
df_Fare_discretization
| range | count |
|---|---|
| (204.932, 307.398] | 17 |
| (-0.512, 102.466] | 838 |
| (409.863, 512.329] | 3 |
| (102.466, 204.932] | 33 |
ranges = pd.qcut(df['Fare'], 5)
df_Fare_discretization = pd.DataFrame(list(Counter(ranges).values()), columns=['count'], index= list(Counter(ranges).keys()))
df_Fare_discretization
| range | count |
|---|---|
| (7.854, 10.5] | 184 |
| (39.688, 512.329] | 176 |
| (10.5, 21.679] | 172 |
| (-0.001, 7.854] | 179 |
| (21.679, 39.688] | 180 |
最後,我們把整份Titanic的資料前處理完整說明一次。
def preprocess(df):
## 處理None值
# avg_age = df['Age'].mean() #作法一: 取平均值
# avg_age = df['Age'].median() #作法二: 取中位數
# 作法三: 用相同的分布產生亂數塞入
std = df['Age'].std()
mean = df['Age'].mean()
size = len(df[pd.isnull(df['Age'])])
age_null_random_list = np.random.randint(mean - std, mean + std, size=size)
df.loc[pd.isnull(df['Age']), 'Age'] = age_null_random_list
# fare discretization
def farecat(f):
if f <= 16:
cat = 0
elif f > 17 and f <= 32:
cat = 1
elif f > 32 and f <= 48:
cat = 2
elif f < 48 and f <= 64:
cat = 3
elif f < 64 and f <= 80:
cat = 4
elif f < 80 and f <= 96:
cat = 5
else:
cat = 6
return cat
# avg_fare
fares_notnull = df[pd.notnull(df['Fare'])]['Fare']
avg_fare = fares_notnull.median()
# ticket
ticket_cat = {}
for ticket in df['Ticket']:
if ticket.isdigit():
ticket_cat[ticket] = 1
elif ticket.startswith('A'):
ticket_cat[ticket] = 2
elif ticket.startswith('C'):
ticket_cat[ticket] = 3
elif ticket.startswith('F'):
ticket_cat[ticket] = 4
elif ticket.startswith('P'):
ticket_cat[ticket] = 5
elif ticket.startswith('SOTON'):
ticket_cat[ticket] = 6
elif ticket.startswith('STON'):
ticket_cat[ticket] = 7
elif ticket.startswith('S'):
ticket_cat[ticket] = 8
elif ticket.startswith('W'):
ticket_cat[ticket] = 9
else:
ticket_cat[ticket] = 0
ticket_cat1 = {}
for num, name in enumerate(list(set([item.split()[0].replace(".", "").replace("/", "") for item in df['Ticket'] if not item.isdigit()]))):
ticket_cat1[name] = num
# cabin
cabin_cat = {}
for cabin in df['Cabin']:
if pd.isnull(cabin):
cabin_cat[cabin] = 0
elif cabin.startswith('A'):
cabin_cat[cabin] = 1
elif cabin.startswith('B'):
cabin_cat[cabin] = 2
elif cabin.startswith('C'):
cabin_cat[cabin] = 3
elif cabin.startswith('D'):
cabin_cat[cabin] = 4
elif cabin.startswith('E'):
cabin_cat[cabin] = 5
else:
cabin_cat[cabin] = 0
# embarked
embarked_cat = {}
for embarked in df['Embarked']:
if pd.isnull(embarked):
embarked_cat[embarked] = 0
elif embarked.startswith('S'):
embarked_cat[embarked] = 0
elif embarked.startswith('Q'):
embarked_cat[embarked] = 1
elif embarked.startswith('C'):
embarked_cat[embarked] = 2
# title
title_mapping= {
'Ms':"Miss",
'Mlle':"Miss",
'Miss':"Miss",
'Mrs':"Mrs",
'Mme':"Mrs",
'MrsMartin(ElizabethL':"Mrs",
'Mr':"Mr"
}
title_cat = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
# Name_with specail chars
def withspecailchar(name):
for char in name:
if char in string.punctuation:
return 1
return 0
def applyfun(row):
# Normalization
row['Fare'] = row['Fare'] if pd.notnull(row['Fare']) else avg_fare
row['Fare_log10'] = math.log(row['Fare'], 10) if row['Fare'] != 0 else 0
# Transformation
row['Cabin'] = cabin_cat.get(row['Cabin']) ## 整理艙位的類別
row['Ticket'] = ticket_cat.get(row['Ticket']) ## 整理票券類別
row['Embarked'] = embarked_cat.get(row['Embarked']) ## 整出發地類別
row['Sex'] = 1 if row['Sex'] == 'male' else 0 ## 性別
row['Name_Length'] = len(row['Name']) ## Name => Name_Length
row['Name_With_Special_Char'] = withspecailchar(row['Name'].replace(',', "").replace('.', "")) ## Name => Name_With_Special_Char
call = re.search(r'\,.+\.', row['Name']).group(0).replace(",", "").replace(".", "").replace(" ", "")
call_cat = title_cat.get(title_mapping.get(call, "Rare"))
row['Title'] = call_cat ## Name => Title
# Discretization
row['Fare_Cat'] = farecat(row['Fare'])
# Integration
row['Family_Size'] = row['SibSp'] + row['Parch']
row['Is_Alone']= 1 if row['Family_Size'] == 1 else 0
row['Is_Mother']= 1 if row['Parch'] > 1 and row['Age']>20 else 0
return row
df = df.apply(applyfun, axis=1)
df.drop(['Name', 'Fare'], axis=1, inplace=True)
return df
df = pd.read_csv('train.csv')
df = preprocess(df)


