由於接下來幾天,將會談到資料科學中最神秘也最有魅力的部分,因此讓握們重新來回顧一下,我們目前已經經歷了哪些技術,未來即將要經的是那些技術,以及他們在資料科學領域中個別會是甚麼角色,要解決的是哪一類的問題。所以先讓我們回顧一下第一天的文章吧。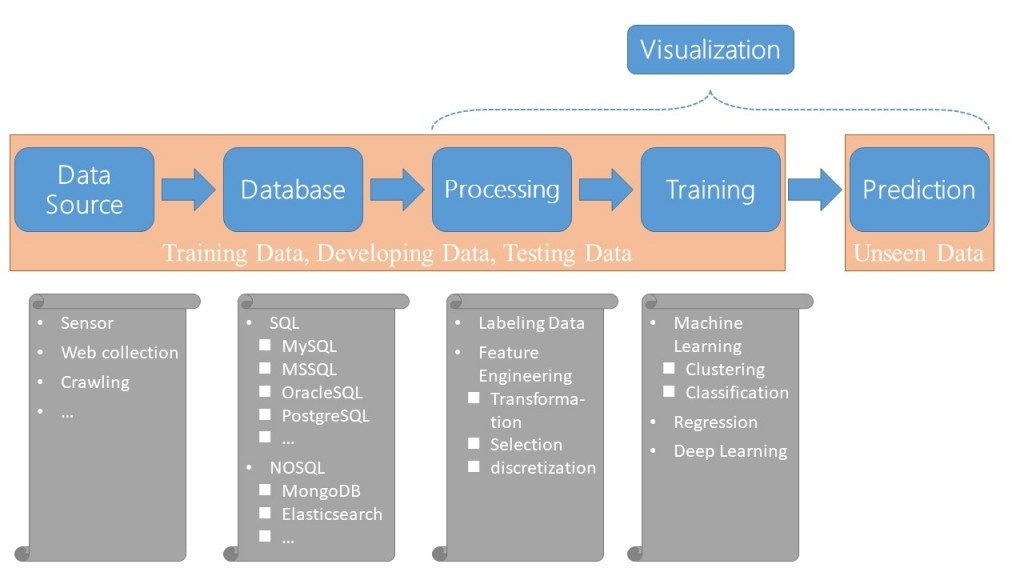
在資料取得的部分,我們談了爬蟲...
在資料儲存的部分,我們談了MongoDB...
在資料處理的部分,我們談了自然語言處理以及資料前處理...
在資料訓練的部分,我們談了文件檢索...
接下來我們將持續圍繞著資料訓練的部分,介紹許多神奇酷炫的演算法。
其實我滿建議在接下來的文章中,如果大家要認真觀看的話,可以先釐清人工智慧、機器學習、深度學習之間的關係,以下概略的說明。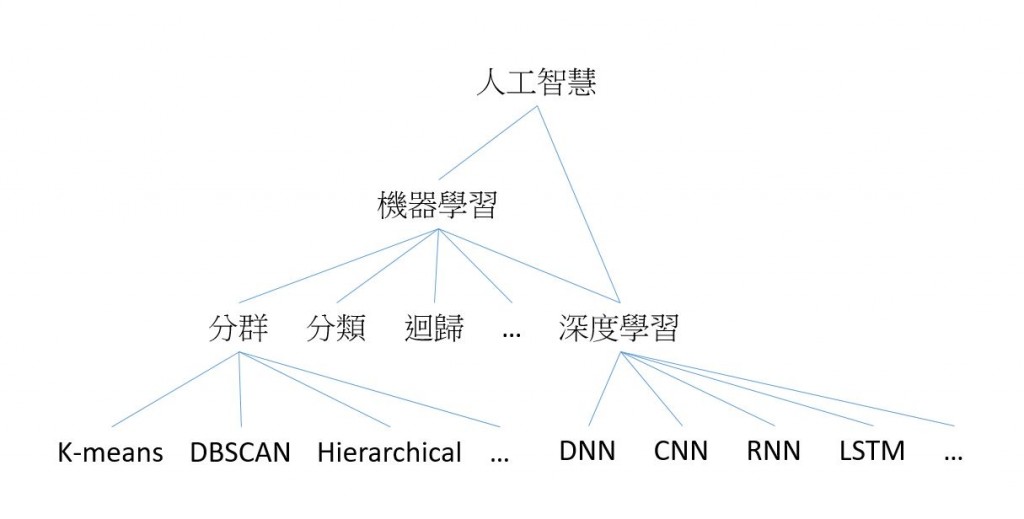
其實所謂人工智慧裡面包含的範疇非常的廣泛,裡面既包含了機器學習,也包含了深度學習,詳細定義因人而異,對我來說不管是深度學習或是機器學習,對沒有相關背景的人來說就是一門不知道在幹嘛的資訊技術,但是人工智慧就不一樣了,電腦可以模仿人類的行為與判斷,這是何等大事,名嘴表示:「電腦要取代人類啦!」
機器學習算是比較早一點出現的領域,主要分成幾個子領域: 分群、分類、迴歸分析、深度學習,分群指的是在沒有標記好的正確資料的情況下(Ground Truth),把資料分成多個群組。分類則是有標記好的正確資料可以讓機器去學習。而迴歸分析亦是有標記好的正確資料,其與分類的差異是在預測資料的型態不同。分類會有一個個明確的類別,向是某一張圖片是貓或不是貓、或是某一個民眾問題應該被分類到哪一個政府處室進行處裡;不過迴歸分析主要是用來預測連續型的變數,像是經濟成長率或是價格,順帶一提,在迴歸分析領域中,也有一種方法稱為羅吉斯回歸(logistic regression);
最後,深度學習其實是透過非常複雜的函式去做與分類以及迴歸分析相同的事情,當然其應用面會比分類以及迴歸分析廣非常多,這樣聽起來很厲害也很複雜,不過其實你可以想的簡單一點,基礎上來說,捼果你對迴歸分析有一點了解,你可以把它想像成有很多的回歸式接在一起,把某個回歸式的產出變成下一個回歸式的輸入,定透過逼近法的方式找到正確答案。不過這並不是這個文章集談論的重點,因此我們就點到為止吧。
另外,有另一種分類方式是這麼分類的,分成監督式學習、非監督式學習,主要看我們的資料及是否有正確答案,有正確答案者稱為監督式學習,反之亦然。分群由於沒有正確的答案指出某一筆資料應該被分到哪一群才是對的,因此是非監督式的學習。分類、迴歸則是屬於監督式學習。而深度學習處理的議題有監督式學習,亦有非間度式學習。


