今天我們要利用一個 seq2seq 模型,來作英中翻譯,它不是以傳統字典的查詢方式,而是利用 LSTM 演算法,讓機器自我學習,進而達到翻譯的功能。這個程式是官方釋出的範例,旨在教學,故只能翻譯短句,但是,這支程式只要改變訓練資料,要作各種語言的翻譯均可,完全不需要改變程式,只要改變訓練資料即可。
本篇說明主要擷取自『A ten-minute introduction to sequence-to-sequence learning in Keras』,再加上少部分筆者實驗的心得,整理而成。
記得我們在『Day 14:循環神經網路(Recurrent Neural Network, RNN)』提到一張圖如下,其中第四項『多對多(many to many)』模型,就是所謂『序列對序列』(Sequence input and sequence output,seq2seq),從一個input序列,推導出另一個output序列,例如:
『You should know it.』 -> [Seq2Seq model] -> 『你應該知道的。』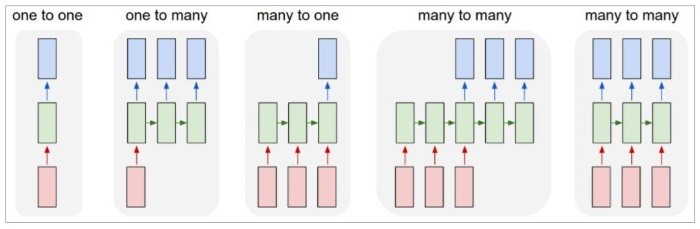
圖. RNN 模型,圖片來源:The Unreasonable Effectiveness of Recurrent Neural Networks
它串連兩個LSTM隱藏層(上圖藍色及綠色的方塊,粉紅色是input),一個隱藏層讓『input序列』擔任『編碼器』(encoder)的角色,以LSTM處理,但不管輸出,只保留記憶狀態(State),讓另一個隱藏層使用,另一個隱藏層額外再考慮前文,兩者綜合起來,預測下一個翻譯的字,這個機制稱為『解碼器』(decoder),請參閱下圖。這種利用編碼器累積的記憶,"同步"來訓練解碼器的過程,稱之『teacher forcing』(強迫教學?)。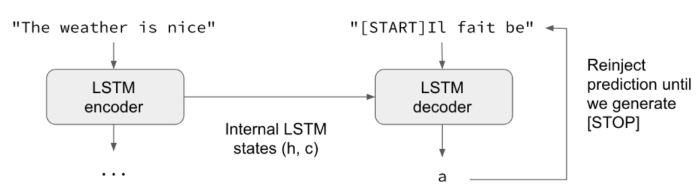
圖. 兩個LSTM隱藏層同步串連,圖片來源:A ten-minute introduction to sequence-to-sequence learning in Keras
接下來,我們就以 Keras 的程式碼來說明。
可自這裡下載,同樣,我額外加了一些註解,也可自這裡下載,主程式為 lstm_seq2seq.py,訓練資料集在cmn-eng/cmn.txt,可自anki下載,只有簡體字,想改用繁體,可直接用MS Word轉換即可,原程式使用英法翻譯,我改用英中翻譯。
'''https://github.com/keras-team/keras/blob/master/examples/lstm_seq2seq.py
Sequence to sequence example in Keras (character-level).
# Data download
English to French sentence pairs.
http://www.manythings.org/anki/fra-eng.zip
'''
from __future__ import print_function
from keras.models import Model
from keras.layers import Input, LSTM, Dense
import numpy as np
# 參數設定
batch_size = 64 # Batch size for training.
epochs = 100 # Number of epochs to train for.
latent_dim = 256 # Latent dimensionality of the encoding space.
num_samples = 10000 # Number of samples to train on.
# 設定訓練資料檔路徑
#data_path = 'fra-eng/fra.txt'
data_path = 'cmn-eng/cmn.txt'
# 讀取資料檔,並將所有單字整理為字典,分別為英文及中文字典,注意,英文為字母的集合,非單字(Word)
input_texts = []
target_texts = []
input_characters = set()
target_characters = set()
lines = open(data_path, encoding ='utf8').read().split('\n')
for line in lines[: min(num_samples, len(lines) - 1)]:
input_text, target_text = line.split('\t')
# We use "tab" as the "start sequence" character
# for the targets, and "\n" as "end sequence" character.
target_text = '\t' + target_text + '\n'
input_texts.append(input_text)
target_texts.append(target_text)
for char in input_text:
if char not in input_characters:
input_characters.add(char)
for char in target_text:
if char not in target_characters:
target_characters.add(char)
# 字典排序
input_characters = sorted(list(input_characters))
target_characters = sorted(list(target_characters))
num_encoder_tokens = len(input_characters)
num_decoder_tokens = len(target_characters)
# 計算編碼器、解碼器的最大長度
max_encoder_seq_length = max([len(txt) for txt in input_texts])
max_decoder_seq_length = max([len(txt) for txt in target_texts])
print('Number of samples:', len(input_texts))
print('Number of unique input tokens:', num_encoder_tokens)
print('Number of unique output tokens:', num_decoder_tokens)
print('Max sequence length for inputs:', max_encoder_seq_length)
print('Max sequence length for outputs:', max_decoder_seq_length)
# 以dict儲存字典單字及序號
input_token_index = dict(
[(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict(
[(char, i) for i, char in enumerate(target_characters)])
# 設定編碼器、解碼器input起始值(均為0矩陣)
encoder_input_data = np.zeros(
(len(input_texts), max_encoder_seq_length, num_encoder_tokens),
dtype='float32')
decoder_input_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
decoder_target_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
# 設定 encoder_input、decoder_input對應的順序
for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):
for t, char in enumerate(input_text):
encoder_input_data[i, t, input_token_index[char]] = 1.
for t, char in enumerate(target_text):
# decoder_target_data is ahead of decoder_input_data by one timestep
decoder_input_data[i, t, target_token_index[char]] = 1.
if t > 0:
# decoder_target_data will be ahead by one timestep
# and will not include the start character.
decoder_target_data[i, t - 1, target_token_index[char]] = 1.
# 建立 encoder LSTM 隱藏層
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder = LSTM(latent_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
# 捨棄 output,只保留記憶狀態 h 及 c
encoder_states = [state_h, state_c]
# 建立 decoder LSTM 隱藏層
decoder_inputs = Input(shape=(None, num_decoder_tokens))
# We set up our decoder to return full output sequences,
# decoder 記憶狀態不會在訓練過程使用,只會在推論(Inference)使用
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs,
initial_state=encoder_states)
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
# 定義模型,由 encoder_input_data 及 decoder_input_data 轉換為 decoder_target_data
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
# 訓練
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
model.fit([encoder_input_data, decoder_input_data], decoder_target_data,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
# 儲存模型及結果
model.save('s2s.h5')
# 推論(Inference)
# 過程如下:
# 1) encode input and retrieve initial decoder state
# 2) run one step of decoder with this initial state
# and a "start of sequence" token as target.
# Output will be the next target token
# 3) Repeat with the current target token and current states
# 定義編碼器取樣模型
encoder_model = Model(encoder_inputs, encoder_states)
# 定義解碼器的input
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
# 定義解碼器 LSTM 模型
decoder_outputs, state_h, state_c = decoder_lstm(
decoder_inputs, initial_state=decoder_states_inputs)
# 以編碼器的記憶狀態 h 及 c 為解碼器的記憶狀態
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model(
[decoder_inputs] + decoder_states_inputs,
[decoder_outputs] + decoder_states)
# 建立反向的 dict,才能透過查詢將數值轉回文字
reverse_input_char_index = dict(
(i, char) for char, i in input_token_index.items())
reverse_target_char_index = dict(
(i, char) for char, i in target_token_index.items())
# 模型預測,並取得翻譯結果(中文)
def decode_sequence(input_seq):
# Encode the input as state vectors.
states_value = encoder_model.predict(input_seq)
# Generate empty target sequence of length 1.
target_seq = np.zeros((1, 1, num_decoder_tokens))
# Populate the first character of target sequence with the start character.
target_seq[0, 0, target_token_index['\t']] = 1.
# Sampling loop for a batch of sequences
# (to simplify, here we assume a batch of size 1).
stop_condition = False
decoded_sentence = ''
while not stop_condition:
output_tokens, h, c = decoder_model.predict(
[target_seq] + states_value)
# Sample a token
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_char = reverse_target_char_index[sampled_token_index]
decoded_sentence += sampled_char
# Exit condition: either hit max length
# or find stop character.
if (sampled_char == '\n' or
len(decoded_sentence) > max_decoder_seq_length):
stop_condition = True
# Update the target sequence (of length 1).
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, sampled_token_index] = 1.
# Update states
states_value = [h, c]
return decoded_sentence
# 測試100次
for seq_index in range(100):
# Take one sequence (part of the training test)
# for trying out decoding.
input_seq = encoder_input_data[seq_index: seq_index + 1]
decoded_sentence = decode_sequence(input_seq)
print('*')
print('Input sentence:', input_texts[seq_index])
try:
print('Decoded sentence:', decoded_sentence)
except:
# 出現亂碼,以?取代
print('Decoded sentence:', decoded_sentence.encode('ascii', 'replace'))
#print("error:", sys.exc_info()[0])
在DOS下執行下列指令:
python lstm_seq2seq.py
原作者說在MacBook執行、CPU版執行約需一個小時就可完成,但是筆者執行了一整個晚上才搞定,原因可能有二,我在Windows下執行,TensorFlow 並未從Source重新建置(如果你執行時出現以下訊息 "The TensorFlow library wasn't compiled to use SSE instructions, but these are available on your machine and could speed up CPU computations."),另一個原因,可能他的MacBook比我的準系統(i5-5200U/12GB RAM)強很多吧。
執行結果如下圖,大部分都能出現正確答案,少數會出現亂碼,我還在找原因,程式先用 try/catch 忽略錯誤。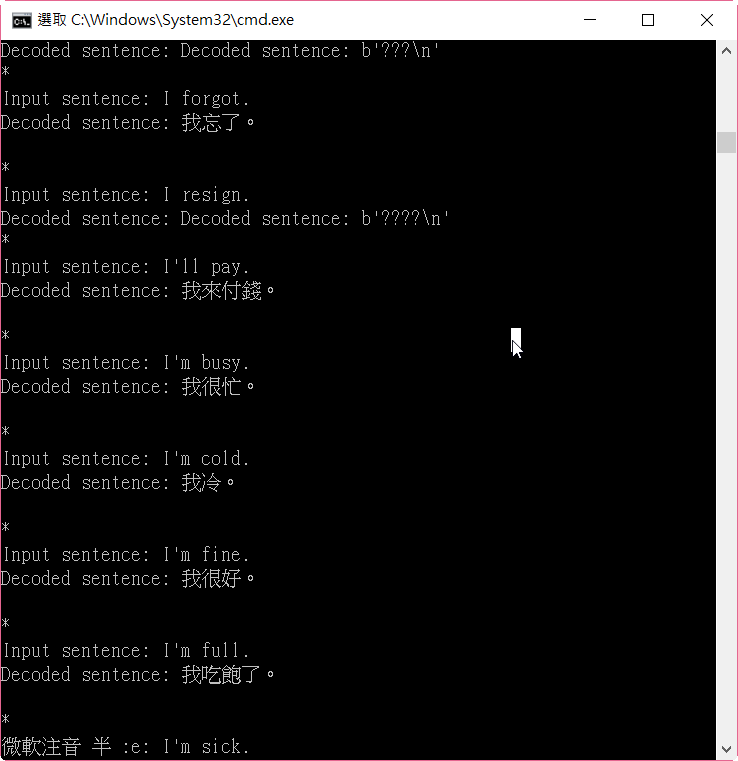
圖. lstm_seq2seq.py 執行結果
程式比較長,筆者分段註解,可依註解 trace 程式,大致處理流程如下:
這個應用非常實際,如果我們要解析整段文句的翻譯,傳統的方式要同時透過文法學、語意學,再建立特例以彌補規則的不足,因此,我們透過線上翻譯整篇文章,得到的結果常不盡理想,如果,能轉念另闢蹊徑,也許能突破障礙。當然,訓練模型的速度及資料集必須要更廣,這就需要有強大的軍火(CPU/GPU/FPGA....),也難怪郭台銘在高軟搞了一台超級電腦了。


