
我們在『Day 09:CNN 經典模型應用』討論到CNN的預先訓練好的模型,並在後續的篇幅,直接套用這些模型在『照片主體的相似性比對』、『畫風轉換』及『物體偵測(Object Detection) + 影像標題(Image Captioning)』等等的應用上,這些經典模型都是針對影像處理,在自然語言處理領域,是否有類似的作法呢? 有的,就是『詞向量』(Word Embedding or Word Vector)的資料集及其演算法。
對於影像而言,我們關心的是辨識主體的構成像素,相對於語言而言,我們要辨識句子乃至文章段落,最重要的就是單字了(中文可能是詞,例如人類、窗戶...),詞向量的技術就希望將每個單字賦予一個向量,用來表示這個單字在各種維度(Dimenesion)所代表的相對意義,以向量區分每個單字與其他單字的相似程度。所謂『各種維度』的意思是指,例如,就生物角度來看,man(男人)與woman(女人)是很相似的,因為他們同屬人類,但是從另一個角度『性別』來看,他們恰似相反的,所以,要將一個單字轉換為向量,不能像『Day 16:情緒分析』只考慮一維,而是要有多面向來觀察,亦即多維(通常是100~1000),這就是『詞向量』(Word Embedding or Word Vector)的粗淺概念。
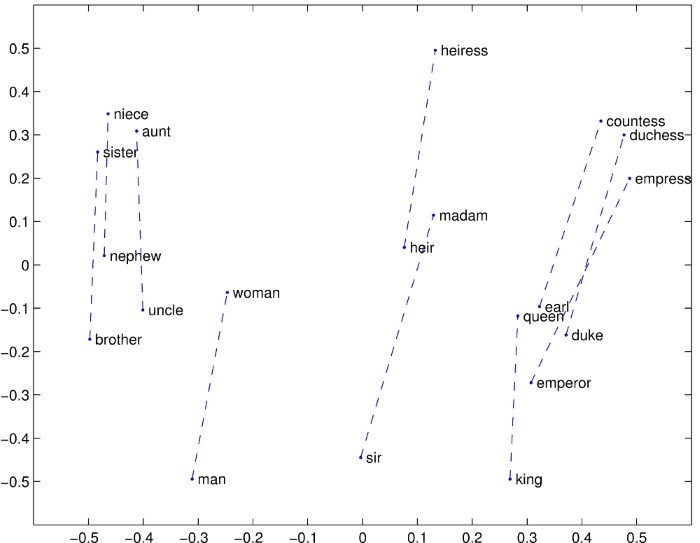
圖. 詞向量的示意圖,圖片來源:GloVe: Global Vectors for Word Representation
詞向量最有名的技術有兩個:
兩者的技術都是在計算單字在文件(Document)出現的次數,進而統計兩個單字共同出現的機率大小,以決定其相似性,也就是單字間的向量距離,距離越短表示越相似。另一方面,如果為每個單字都定義一個向量,所有單字就構成一個『向量空間』(Vector Space),我們就可以計算相對距離,來預測單字構成的文章是屬於哪一類,這就串接到 Neural Network 模型的分類概念了,先有個概念,我們在後續的篇章再仔細探討相關的技術及作法。
既然詞向量定義單字可以用向量來表達,那我們如何整理所有單字在各種維度代表的數值呢? 不是憑一己之力整理,當然是要站在巨人的肩膀上,史丹佛GloVe團隊已提供多種預訓詞向量,供我們使用,本例使用的是 glove.6B.100d.txt資料檔,6B代表使用60億的單字(Token)語料庫訓練,共含400K字彙,100d表100個維度,另外還有50d、200d、300d可供使用。檔案格式為csv(空白隔開),第一欄為單字,第二欄以後為各維度向量。
預訓詞向量涵蓋了字典大部分的詞彙,而且已經幫我們轉成向量,我們就可以擷取任何語料庫當作訓練資料,將訓練資料以查表的方式,轉成向量,再輸入模型訓練,即可形成某一領域的應用模型了。我們現在就來看一個 Keras 官方提供的範例,說明文件請看Using pre-trained word embeddings in a Keras model。
程式來自Keras 官方提供的範例,我加了一些註解,可以自這裡下載。預訓詞向量檔 glove.6B.100d.txt 及 newsgroup 資料集請讀者自行下載。
'''This script loads pre-trained word embeddings (GloVe embeddings)
into a frozen Keras Embedding layer, and uses it to
train a text classification model on the 20 Newsgroup dataset
(classification of newsgroup messages into 20 different categories).
GloVe embedding data can be found at:
http://nlp.stanford.edu/data/glove.6B.zip
(source page: http://nlp.stanford.edu/projects/glove/)
20 Newsgroup data can be found at:
http://www.cs.cmu.edu/afs/cs.cmu.edu/project/theo-20/www/data/news20.html
'''
# 導入函式庫
from __future__ import print_function
import os
import sys
import numpy as np
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
from keras.layers import Dense, Input, GlobalMaxPooling1D
from keras.layers import Conv1D, MaxPooling1D, Embedding
from keras.models import Model
# 參數設定
BASE_DIR = ''
GLOVE_DIR = os.path.join(BASE_DIR, 'glove.6B')
TEXT_DATA_DIR = os.path.join(BASE_DIR, '20_newsgroup')
MAX_SEQUENCE_LENGTH = 1000
MAX_NB_WORDS = 20000
EMBEDDING_DIM = 100
VALIDATION_SPLIT = 0.2
# 將 glove.6B.100d.txt 檔案轉成 dict,key:單字, value:詞向量
embeddings_index = {}
f = open(os.path.join(GLOVE_DIR, 'glove.6B.100d.txt'), encoding='utf8')
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Found %s word vectors.' % len(embeddings_index))
# 顯示the單字的詞向量
print(len(embeddings_index["the"]))
# 讀取訓練資料檔,包含 20_newsgroup 資料夾下所有子目錄及檔案,共20類
texts = [] # list of text samples
labels_index = {} # dictionary mapping label name to numeric id
labels = [] # list of label ids
for name in sorted(os.listdir(TEXT_DATA_DIR)):
path = os.path.join(TEXT_DATA_DIR, name)
if os.path.isdir(path):
label_id = len(labels_index)
labels_index[name] = label_id
for fname in sorted(os.listdir(path)):
if fname.isdigit():
fpath = os.path.join(path, fname)
if sys.version_info < (3,):
f = open(fpath)
else:
f = open(fpath, encoding='latin-1')
t = f.read()
i = t.find('\n\n') # skip header
if 0 < i:
t = t[i:]
texts.append(t)
f.close()
labels.append(label_id)
# 20類的代號及名稱
print(labels_index)
print('Found %s texts.' % len(texts))
# 將訓練資料的單字轉成向量
tokenizer = Tokenizer(num_words=MAX_NB_WORDS)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
# 將訓練字句截長補短
data = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)
labels = to_categorical(np.asarray(labels))
print('Shape of data tensor:', data.shape)
print('Shape of label tensor:', labels.shape)
# 將訓練資料分為訓練組及驗證組
indices = np.arange(data.shape[0])
np.random.shuffle(indices)
data = data[indices]
labels = labels[indices]
num_validation_samples = int(VALIDATION_SPLIT * data.shape[0])
x_train = data[:-num_validation_samples]
y_train = labels[:-num_validation_samples]
x_val = data[-num_validation_samples:]
y_val = labels[-num_validation_samples:]
print('Preparing embedding matrix.')
# 轉成 Embedding 層的 input vector
num_words = min(MAX_NB_WORDS, len(word_index))
embedding_matrix = np.zeros((num_words, EMBEDDING_DIM))
for word, i in word_index.items():
if i >= MAX_NB_WORDS:
continue
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
# words not found in embedding index will be all-zeros.
embedding_matrix[i] = embedding_vector
# 載入預訓模型,trainable = False 表示不重新計算
embedding_layer = Embedding(num_words,
EMBEDDING_DIM,
weights=[embedding_matrix],
input_length=MAX_SEQUENCE_LENGTH,
trainable=False)
# 訓練模型
print('Training model.')
# train a 1D convnet with global maxpooling
sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32')
embedded_sequences = embedding_layer(sequence_input)
x = Conv1D(128, 5, activation='relu')(embedded_sequences)
x = MaxPooling1D(5)(x)
x = Conv1D(128, 5, activation='relu')(x)
x = MaxPooling1D(5)(x)
x = Conv1D(128, 5, activation='relu')(x)
x = GlobalMaxPooling1D()(x)
x = Dense(128, activation='relu')(x)
preds = Dense(len(labels_index), activation='softmax')(x)
model = Model(sequence_input, preds)
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['acc'])
# summarize the model
print(model.summary())
model.fit(x_train, y_train,
batch_size=128,
epochs=10,
validation_data=(x_val, y_val))
# 模型存檔
model.save('embedding.h5') # creates a HDF5 file
# evaluate the model
loss, accuracy = model.evaluate(x_val, y_val, verbose=2)
print('Accuracy: %f' % (accuracy*100))

