這個問題的答案並沒有一定的方法,我這邊示範的是我自己的想法,如果讀者有其他idea 也歡迎分享。
首先我們知道當k 值過大時,會有分類過細的問題,k 值過小會有分類過廣的問題,因此我的想法是,k 值隨著樣本數量做變化,然後再經過多次的k-means 分析,逐步把結果篩選出來,所以我必須定義,怎麼樣的k-means 分類結果算是合理。
目前我的想法是該分類的所有經緯度座標會在該種類中心點定義的某個範圍內,例如說:中心點經緯度是(121.5355, 25.06486) ,那所有該群組的其他經緯度必須距離該點300公尺內,這次的k-means 分類才被認可。
因此我們必須要準備計算兩點經緯度距離的公式。
rad = function(x) {
return (x * pi / 180)
}
getDistance = function(p1, p2) {
R = 6378137; # 地球平均的半徑
dLat = rad(p2[1] - p1[1])
dLong = rad(p2[2] - p1[2])
a = sin(dLat / 2) * sin(dLat / 2) +
cos(rad(p1[1])) * cos(rad(p2[1])) *
sin(dLong / 2) * sin(dLong / 2);
c = 2 * atan2(sqrt(a), sqrt(1 - a))
d = R * c
return (d)
}
定義好距離公式後,再來定義如果將dataframe 丟進來,判斷這個dataframe 有沒有任何地址超出範圍的公式,我是這麼樣定義的。
isCenterDistanceOverThreshold <- function(center, df, threshold){ # threshold 單位是公尺
for (i in 1:nrow(df)) {
if(threshold < getDistance(center, c(df$Lat[i], df$Lng[i]))){
return(TRUE)
}
}
return(FALSE)
}
再來,我們要先把地址資料分成兩種:一個是unclassifiedAddress,即尚未被分類的地址,另一個是classifiedAddresses,是已被分類的地址。
unclassifiedAddress <- address_LatLng_data %>% ungroup()
classifiedAddresses <- address_LatLng_data[0,]
然後定義好起始參數,其中iterDistance 的意思是第一次k-means 後,中心點300公尺內才算分類成功,第二次l-means 後,中心點500公尺內分類成功,等...隨著k-means 次數越來越頻繁,放寬的距離也就越大。
SEED <- 20180103
iterDistance <- c(300, 400, 500, 600, 700, 800, 1000)
category = 1 #分類編號
然後接下來是一個大for迴圈,iterDistance 內有多少元素,就會被執行多少次的k-means
for(iter in 1:length(iterDistance)){
#每次的k-means 分析
}
在迴圈內,第一步先是看未被分類的地址有多少個,如果少於5筆就不分析。
n = nrow(unclassifiedAddress)
if(n <= 5){
print("地址過少 無法分類")
break
}
然後是k 值的決定,在這邊我自己定義了一個公式,此公式的k 值會隨著樣本數量改變,數量大約是總樣本數除3的量。
centersCount = as.integer(1 + 0.23*n) #預計產生的中心數
接著就是執行k-means 分析,這邊除了紀錄y_kmeans分類以外,還會記錄每個分類的中心點y_centers。
set.seed(SEED)
kmeans = kmeans(x = unclassifiedAddress[, c('Lat','Lng')], centers = centersCount)
y_kmeans = kmeans$cluster
y_centers = kmeans$centers
再來我們用第二個for去檢查該分類的經緯度有沒有超過中心點太多,如果沒有超過的話,會將這個分類的地址寫入classifiedAddresses,並將category 加一。
for(i in 1:centersCount){
subAddress <- unclassifiedAddress %>%
filter(y_kmeans==i)
if(!isCenterDistanceOverThreshold(y_centers[i,], subAddress, iterDistance[iter])){
subAddress$category <- category
category <- category + 1
classifiedAddresses <- rbind(classifiedAddresses, subAddress)
next
}
}
最後會從未分類的地址中除去已分類的地址,並print出目前還未分類地址數量。
unclassifiedAddress <- unclassifiedAddress %>%
filter(!(V1 %in% classifiedAddresses$V1))
print(paste0("iter-", iter," complete! remain:", nrow(unclassifiedAddress), " addresses"))
以上就是執行的程式碼,執行完後可以看到結果如下。
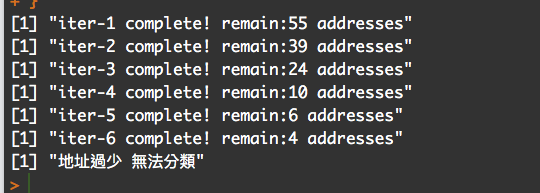
明天會再詳細分析我們所使用的方法是否有解決問題。
ref:
day18原始碼


