昨天我們只有把結果分出來,今天我們就來比較這樣的方法有哪些差異吧。
首先是多次k-means 的結果如下:
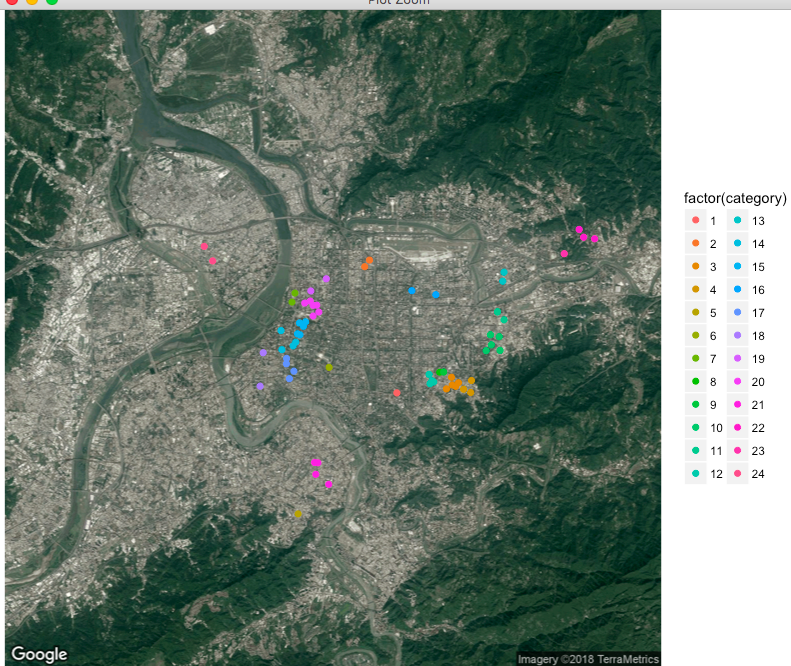
可以看到分成了24組,為了對照方便,單一次k-means 我們就直接指定24個分類,其結果如下。
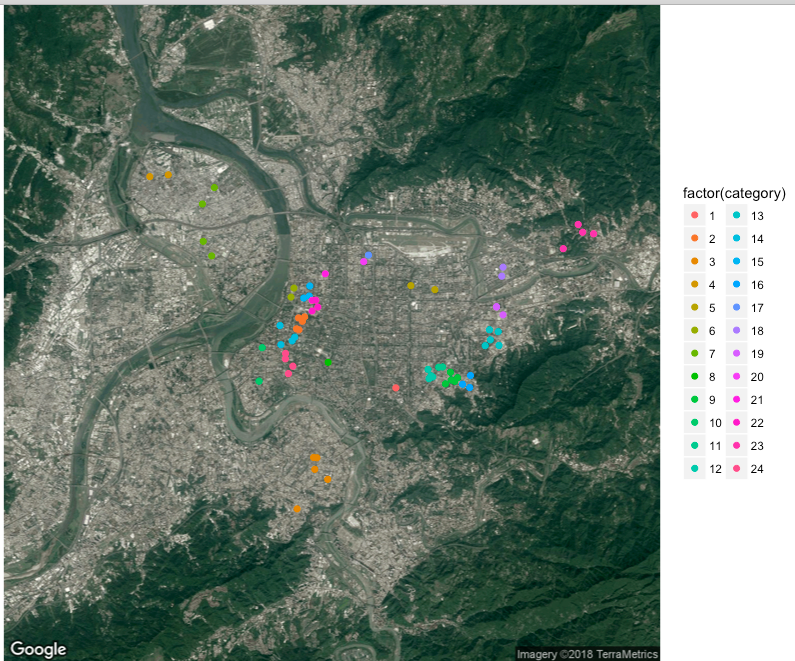
比較兩者,後者的分析中我們看到最後只剩下四個地址沒有分類,這四個地址就是位於左上方新北市三重區的四個地址,很有可能在某次k-means分類後因與中心距離過遠,所以無法被分成一類,另外,我們也發現了多次k-means的結果在大同區變得比較緊密,但仍有些地方和單次k-means的結果一樣分布不均。
接下來我們逐步來觀察,多次k-means 中,分類是如何逐一形成的。
iter-1 complete! remain:55 addresses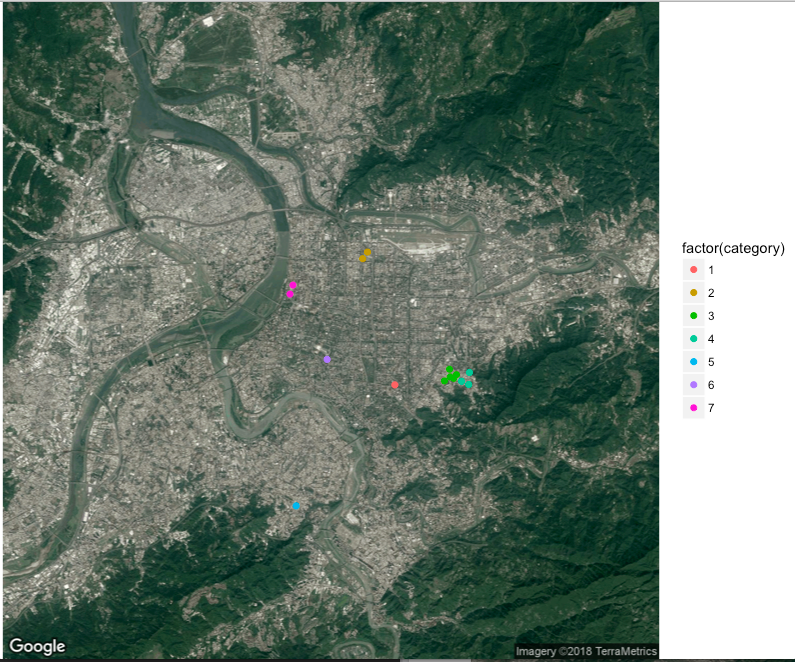
第一次的範圍是鎖定在300公尺,有15個地址被分成了7類,但是不辛地有些分類只有一個地址...
iter-2 complete! remain:39 addresses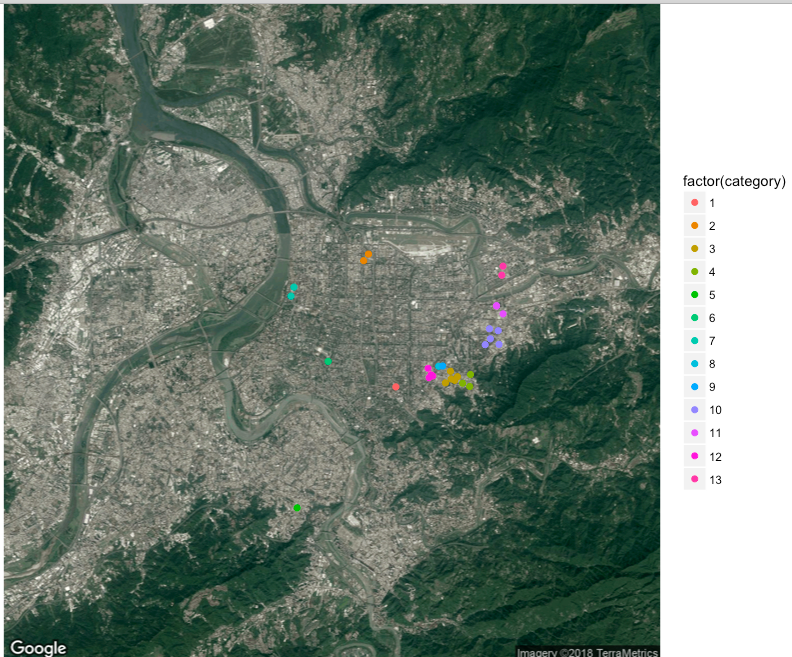
第二次範圍是400公尺,在信義區一代的一些地點被分群。
iter-3 complete! remain:24 addresses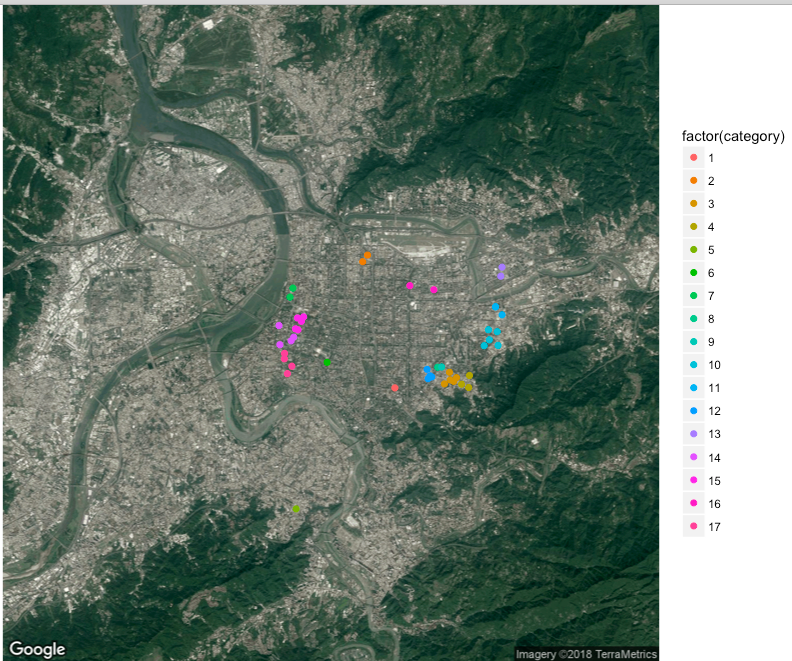
第三次範圍500公尺,主要的分類集中在西門。
iter-4 complete! remain:10 addresses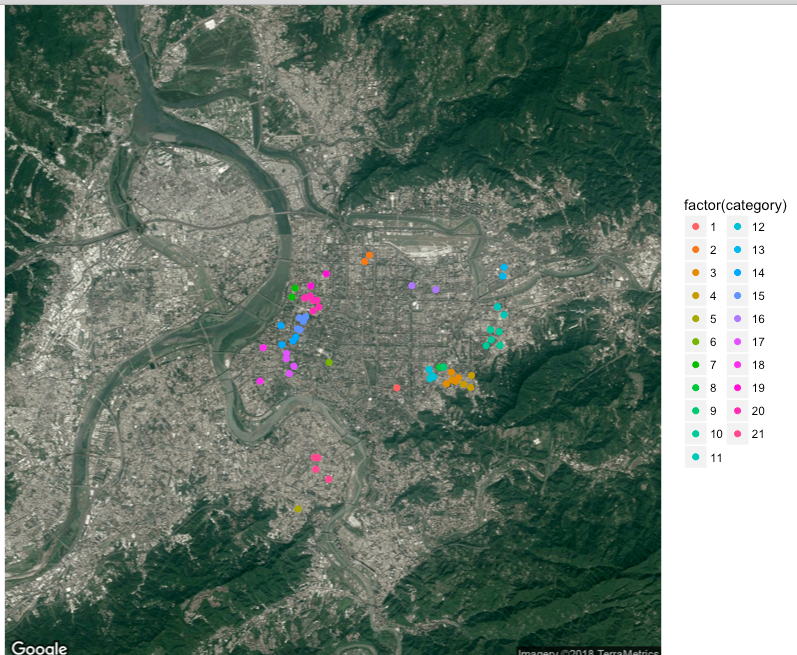
第四次600公尺,發生在西門和永和地區。
iter-5 complete! remain:6 addresses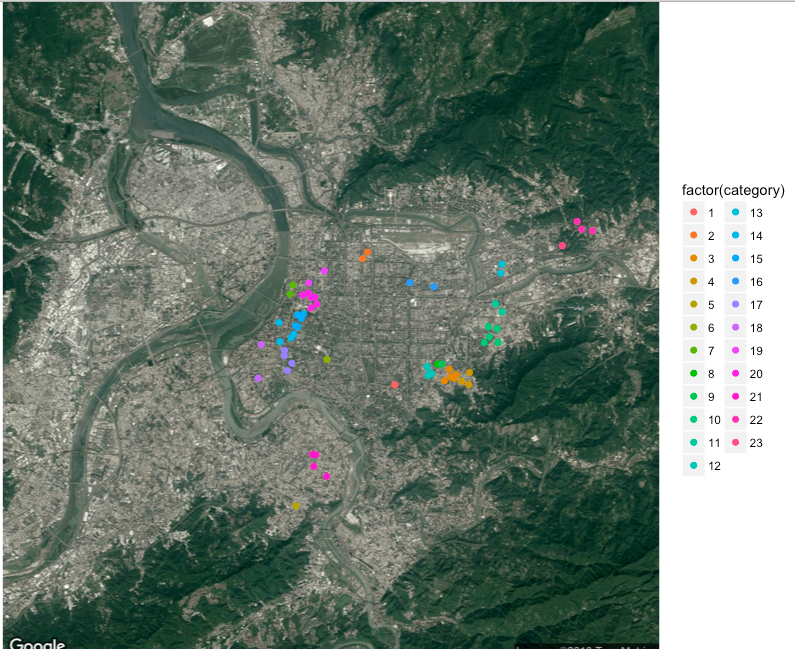
第五次700公尺,右上方有四個內湖區的地址被分類。
iter-6 complete! remain:4 addresses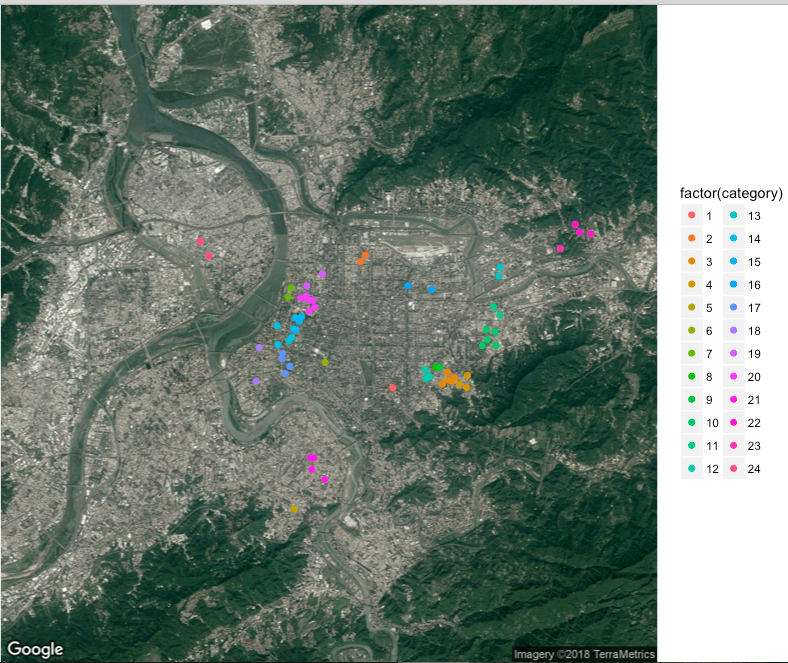
第六次800公尺,三重地區有兩個地址被分出來。
以上是我自己改用多次k-means分析的嘗試,繼續延伸還可以多跑幾個種子碼,再從裡面挑出最理想的結果,資料分析很難有最佳解,只能每次嘗試不同的方法,從一些結果中洞察微妙的變化啊!
ref:
day19程式碼


