昨天提到部分timing的問題,並提供了一個簡單的方法去解決timing violation的問題,就是找出critical path並加一層register,但這樣的解決方式會造成效能的下降,所以今天要來跟大家分享pipeline的使用方式,首先我就用上課聽到的洗衣故事來介紹給大家,大家先參考網路上抓到的示意圖:
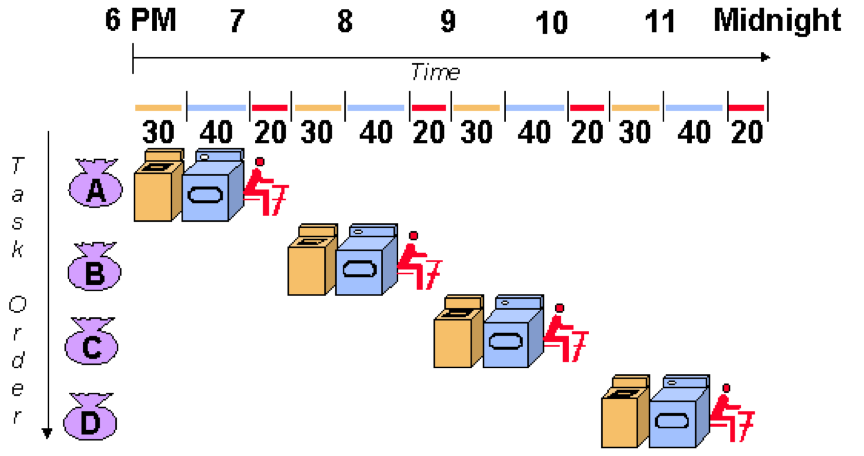
我們把完整的洗衣流程分為,1.洗衣服(30分鐘)2.烘衣服(40分鐘)3.摺衣服(20分鐘),所以一個完整的洗衣流程就需要90分鐘的時間,所以假設今天有四個人要洗衣服,等於要360分鐘才能洗完,你也可以很土豪的說:洗衣機烘乾機都各買四台不就好了,但這樣除了有錢還要浪費空間,但聰明的你應該能想到,當第一個人洗完衣服準備脫水時,就能讓第二個人洗衣服,以此類推,像下圖這樣
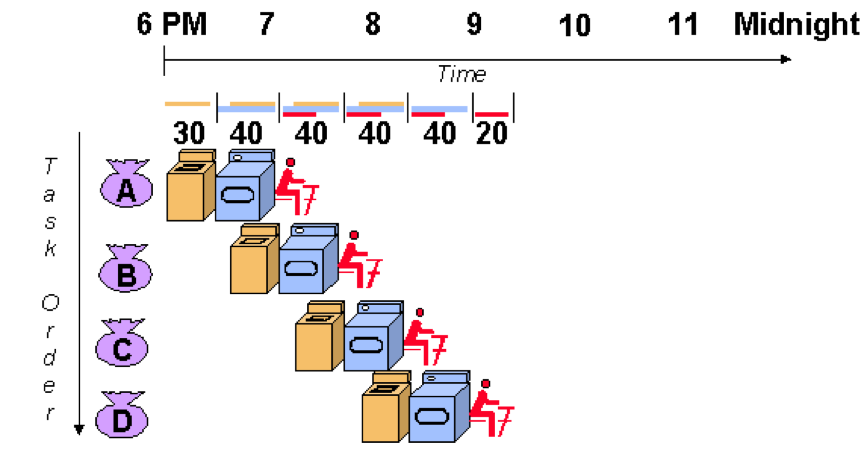
四個人做完只花了210分鐘,回到我們的主題,pipeline原理就像上面的故事一樣,再有限的資源下做出最有效率的排程,洗衣機烘衣機就像是邏輯運算,一個階段執行完,就要用暫存器去紀錄此時的邏輯運算換誰來做,
再舉一個例子:假設我有大筆的資料要做乘法運算 a <= bcd*e;
如果直接這樣寫的話timing可能就會有問題,看一下下面是意圖:

乘法本身就是一個屬於較為複雜的運算,而且還要連續做三個,很有機會發生set up time violation,這時候就可以適用pipeline(洗衣的故事),把乘法器想像成洗衣機,到下一層乘法時用暫存器存前一層的結果跟這一層所要乘的數字,如下圖:
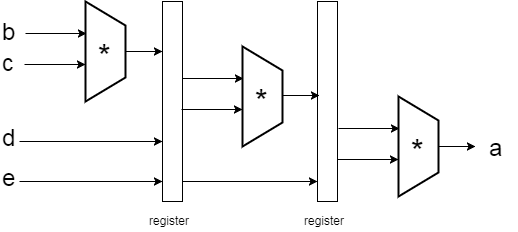
所以在大量資料底下,一樣可以維持一個cycle就算出一個結果,但相對的要多花額外的資源去除存前一筆的資料,所以在使用pipeline時除了能加速以外,資源也要納入考量,因為如果你花了很多資源去加速一個不常用到的電路也是挺浪費的.


