昨天我們已經推導出貝爾曼方程,透過這個數學式,我們可以實現估計價值。在實務上,動態規劃適用迭代的方式,計算狀態或動作的價值。在書中提到有兩種迭代的方法,第一種是策略迭代(Policy iteration),另一種是價值迭代(Value iteration),這邊先介紹策略迭代方法。
先回頭看一下昨天推導出的狀態價值函數: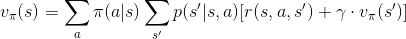
我們迭代的目標是狀態價值,而狀態的價值受到什麼影響呢?從符號上理解,狀態價值受策略 (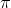 ) 影響。根據這個關係,數學家給出這樣的迭代規則:
) 影響。根據這個關係,數學家給出這樣的迭代規則: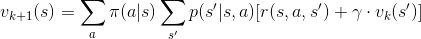
透過這條數學式,我們可以實現「根據現在的價值函數,估計新的價值函數。藉由重複獲得新的價值函數,我們可以逼近真實的狀態價值。」演算法如下: (取自 Sutton 書籍)
(取自 Sutton 書籍)
這裡有兩件事值得注意:
說了這麼多,還是比不上直接看程式運算的結果來的有說服力,這邊取用書上 Example 4.1 舉例。
想像現在有一個 4x4 大小的格子世界,最左上與最右下的格子是終點,如下圖灰色的部份:
 ,表示處於的位置
,表示處於的位置清點手邊的資訊,還缺轉移矩陣,根據其他規定我們可以自己實作,有興趣可以自己實作。
這邊提供我實作的 .npy 檔,是一個 16x16x4 的 numpy 陣列 (轉移後狀態 x 現在狀態 x 動作)
明天我們將使用這些資訊,實作策略迭代評估狀態價值的過程。

