昨天我們用迭代的方式,實作計算狀態價值這件事,並在最後留下兩個問題:
針對第一個問題,可以自行改寫參數中的 gamma 測試。或是簡單看一下狀態價值的定義,就可以猜到可能會發生的是了。假設 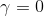 ,則
,則 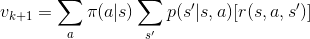 。
。
接著,我們討論決定動作的方法。
我們之前一直著重在狀態價值,現在我們需要使用動作價值了,先來回顧一下定義: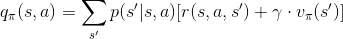
在計算完狀態價值後,我們可以使用「狀態價值」與「動作價值函數」,計算在每個狀態下,每個動作的動作價值。那麼要處理的問題,就變成是要怎麼分配每個動作產生的機率呢?
作者在這裡導入貪婪法,也就是說,我們只選擇在這個狀態下,最好的動作,產生其他動作機率為 0 。為了方便,我們將使用貪婪法的這個策略記作 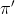 。並將透過貪婪法決定的動作記為
。並將透過貪婪法決定的動作記為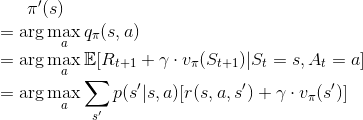
既然我們現在有更好的動作了,那是不是可以再回去更新狀態價值,如此一來,我們對狀態價值的判斷,就會比原本隨機動作的情況更準確。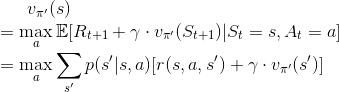
總結來說,我們目前有「計算狀態價值的方法」、「計算最佳動作的方法」,明天我們要把這兩個東西組合起來,完成策略迭代的整體過程。


 iThome鐵人賽
iThome鐵人賽