昨天介紹完貝氏分類器(Bayes Classification),有沒有覺得SKlearn內的函數真的很好用呀!今天要來介紹常用的線性迴歸(Linear-Regression)。
線性回歸簡單來說,就是將複雜的資料數據,擬和至一條直線上,就能方便預測未來的資料。
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
先從簡單的線性回歸舉例, ,
稱為斜率,
稱為截距。
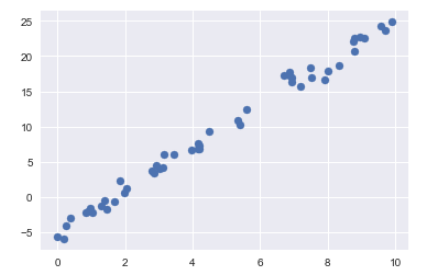
rng = np.random.RandomState(1)
x = 10 * rng.rand(50)
y = 3 * x - 5 + rng.randn(50)
plt.scatter(x, y);
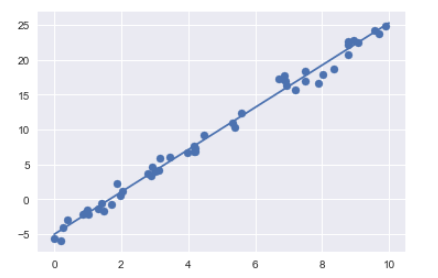
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model.fit(x[:, np.newaxis], y)
xfit = np.linspace(0, 10, 1000)
yfit = model.predict(xfit[:, np.newaxis])
plt.scatter(x, y)
plt.plot(xfit, yfit);
print("Model slope: ", model.coef_[0])
print("Model intercept:", model.intercept_)
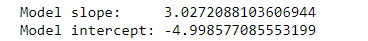
rng = np.random.RandomState(1)
X = 10 * rng.rand(100, 3)
y = 0.5 + np.dot(X, [1.5, -1., 2.])
model.fit(X, y)
print(model.intercept_)
print(model.coef_)

利用SKlearn中匯入 PolynomialFeatures,來做多項式函數處理。
from sklearn.preprocessing import PolynomialFeatures
x = np.array([2, 3, 4])
poly = PolynomialFeatures(3, include_bias=False)
poly.fit_transform(x[:, None])
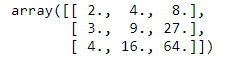
from sklearn.pipeline import make_pipeline
poly_model = make_pipeline(PolynomialFeatures(7), LinearRegression())
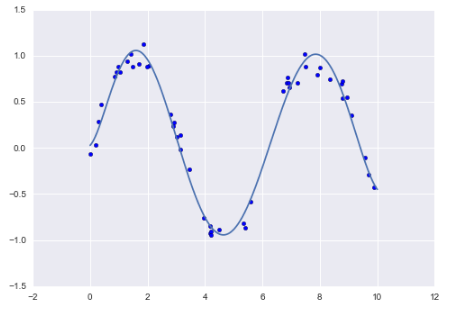
rng = np.random.RandomState(1)
x = 10 * rng.rand(50)
y = np.sin(x) + 0.1 * rng.randn(50)
poly_model.fit(x[:, np.newaxis], y)
yfit = poly_model.predict(xfit[:, np.newaxis])
plt.scatter(x, y)
plt.plot(xfit, yfit);