今天來談談深度學習跟傳統機器學習的比較,主要從 Data、計算資源、特徵萃取 等三個方向進行討論。
深度學習(Deep Learning)的成功主要是基於大量可用的數據以及強大的計算資源例如 GPU(Graphic Processing Units)。
首先從這句話來剖析:深度學習是需要大量數據的,就像需要大量魔力的聖杯。
Fate 裡的聖杯。圖片來源:https://kknews.cc/comic/g29vmne.html
Data
實際上,Data 數量是深度學習的推力也是侷限。這是由於在小數據集上,深度學習還取代不了傳統機器學習方法,例如 SVM、Naive Bayes classifier。有關 Data 數量級變化如何影響深度學習和傳統機器學習的消長,可參考下圖: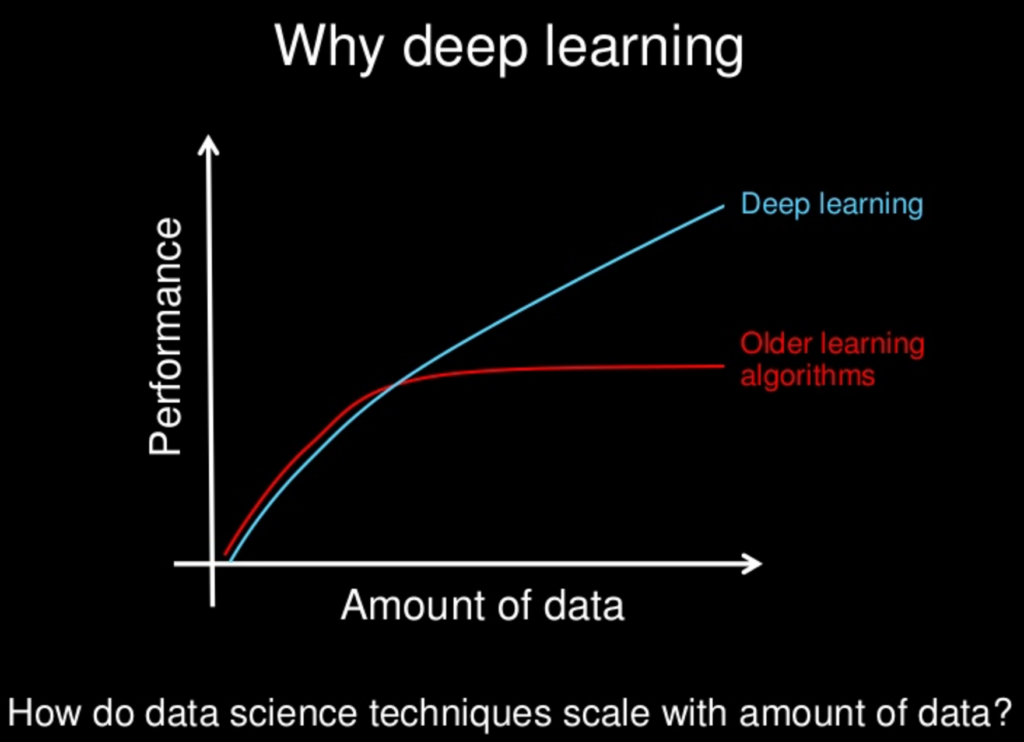
圖片來源:https://machinelearningmastery.com/what-is-deep-learning/
計算資源
我們先前有介紹過 CNN 與 RNN,可以知道在深度學習中蘊含大量的矩陣運算,和傳統機器學習不同的是,深度學習需要龐大的計算資源,也因此在深度學習上大多要求要有好的 GPU,這種專為矩陣運算所設計的計算資源來支援。
下圖是在 ImageNet 圖像分類競賽中,各團隊使用 GPU 的情形: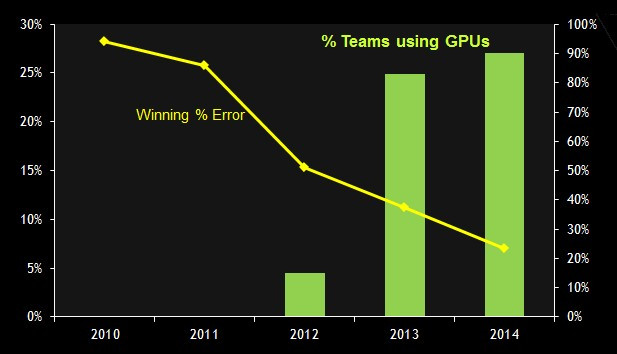
圖片來源:https://www.nextplatform.com/2015/07/07/nvidia-ramps-up-gpu-deep-learning-performance/
特徵萃取
除了 Data 的因子之外,深度學習和傳統機器學習之間有關鍵的不同: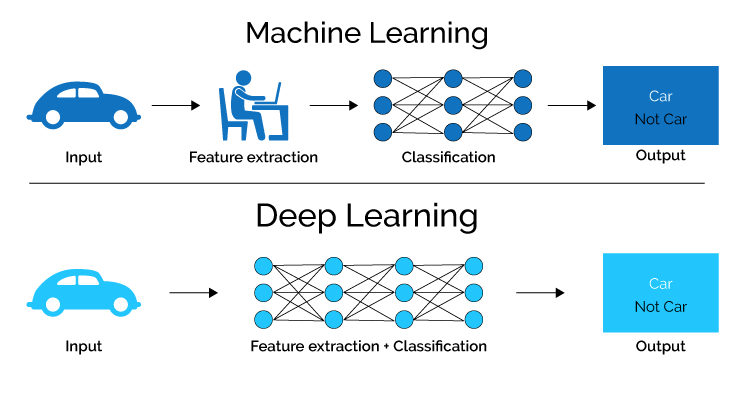
圖片來源:https://semiengineering.com/deep-learning-spreads/
機器學習使用為特定任務開發的算法,通常需要基於人工經驗來萃取特徵;而深度學習是分層特徵學習,能夠從原始數據執行自動特徵提取,也稱為特徵學習(feature learning)。
另外由上圖可以看出,傳統機器學習通常先把問題切分成幾塊,一個個解決後再重新組合起來。而深度學習是 end-to-end(端對端) 的方法,input 是原始數據,output 即是最終輸出結果。如果有可靠數據的話,這種做法可以給模型更多自動調整的空間,直接讓數據說話,且不需要人工介入處理。
不過深度學習也無須跟傳統機器學習切很開,它們是可以共同合作的。在實務上兩者合作的情況很多,例如深度學習可以當作特徵抽取(feature extraction)的角色,之後用傳統分類器進行分類;又或者在 Autoencoder 中,可以透過深度學習做降維的工作。這些都是很好的做法。
下篇就來講 Autoencoder 的原理與應用吧~


 iThome鐵人賽
iThome鐵人賽