
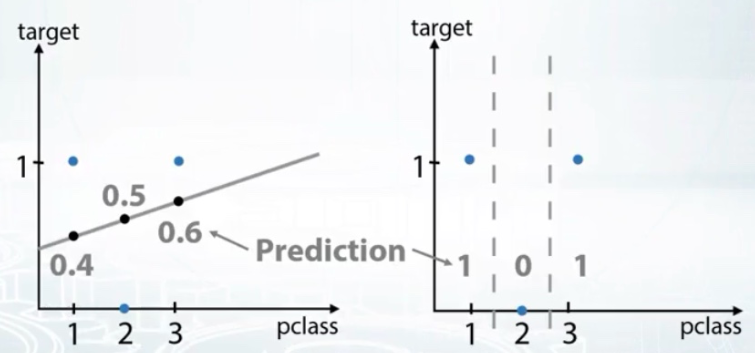
回到 Titanic dataset, 無庸置疑 三個features 'sex, cabin, embarked' 都是 categorical feature. 但是 pclass : 1,2,3 到底是 ordinal 還是 numerical? 我們知道的是頭等艙比二等艙貴, 而頭等艙比起三等艙貴更多, 再舉個例就更清楚, 教育是從幼稚園, 小學, 中學到大學. 這些不是數字, feature 的意義有順序.
| pclass | 1 | 2 | 3 |
|---|---|---|---|
| target | 1 | 0 | 1 |
截圖自Coursera
coursera 課程中建議用在 tree-based model 樹型, 還有 ordinal feature 不建議用線性 model, 依存關係比較不易找到.
賦值予類別型的特徵用encoding可做到, 以 Titanic dataset 的 embarked 來說明 label encoding 的運用
Alphabetical (sorted/依照字母排序)
[S,C,Q] -> [2,1,3]
sklearn.preprocess.LabelEncoder
Order of appearance (依出現順序)
[S,C,Q] -> [1,2,3]
Pandas.Factorize
Frequency encoding (依頻率)
[S,C,Q] -> [0.5, 0.3, 0.2]
encoding = titanic.groupby('embarked').size()
encoding = encoding/len(titanic)
titanic('enc') = titanic.Embaked.map(encoding)
from SciPy.stats import t=rankdata
適用 non-tree-based-models(KNN, NN), One-hot encoding 已scaling/縮放到[0,1], 是去單位非常好用的工具, (在我上 AIA 時就發現這個令人驚奇的好東西), 常用的 libraries XGBoost, LightGBM 或 sklearn 直接可用.
截圖自Coursera
Pandas.get_dummies, sklearn.preprocessing.OneHotEnder
針對特徵萃取比較好用的方法是直接將特徵間互動建立新特徵, 通常用在 non-tree-based-models, linear model, KNN 等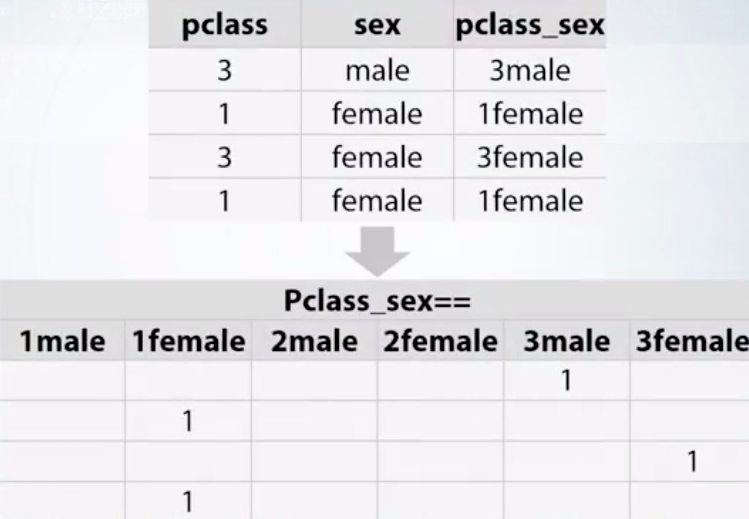
截圖自Coursera
