
預處理分成 tree-based models 跟 non-tree-based models, 他們長得不一樣, 視覺識別可用 tree-based models 會有格子塊狀來區分.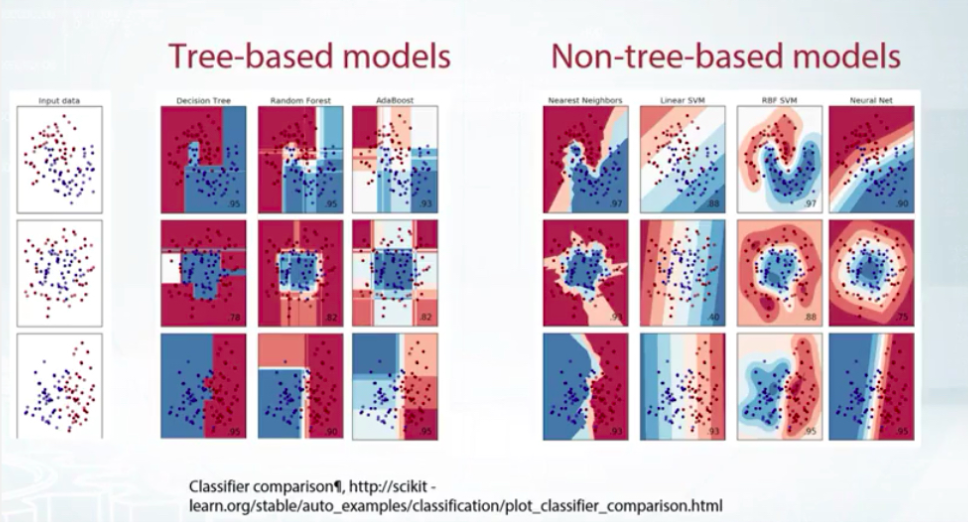
截圖自Coursera
以 Titanic dataset (https://www.kaggle.com/c/titanic/data) 舉例說明 features 型態跟預處理方式.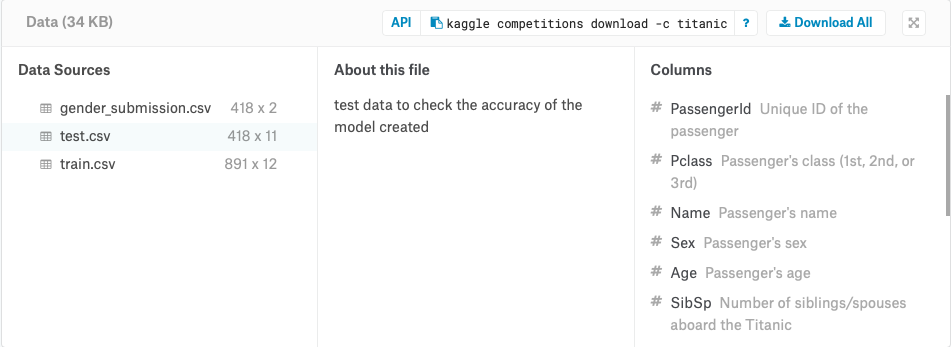
截圖自 Kaggle
-使用 Feature Scaling 特徵縮放避免在數字差異很大時被牽著跑, 正規化很重要, 就像是統計學講的標準化, 一種去單位的概念, 可以想像成被攤平的概念, 所以 Feature Scaling 可以改善 model 的品質.
-例如 Titanic 的 age 資料是 0~80, 而 Sibsp是 0~8. 若用 feature scaling 就能都轉成 0~1 區間來使用.
-方法一 MinMaxScaler --> To[0,1]
sklearn.preprocessing.MinMaxScaler
X=(X-X.min())/(X.max()-X.min())
-方法二 StandardScaler --> To mean=0, std=1
sklearn.preprocessing.StandardScaler
X=(X-X.mean())/X.std()
-方法三 rank <-- 適用在有 outlier 時
scipy.stats.rankdata
rank=([-100, 0, 1e5]) ==
[0,1,2]
rank([1000,1,10]) = [2,0,1]
-提醒 outlier 的處理可以設upper bound/lower bound, 例如財務面資料常用 1 percentile, 99 percentile 以避免資料被拉走
好的特徵萃取是贏得比賽的關鍵, prior knowledge跟對資料的了解(透過EDA), 此項在之後課程會講, 這邊先提概念, 以房屋中介的 dataset中價格跟面積兩個特徵, 可以新增價格/面積價格(price per meter square)
