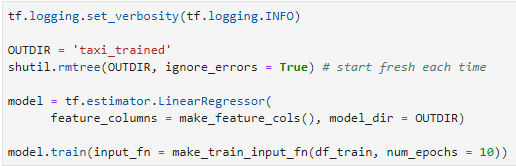
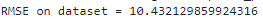接著介紹Estimator API(Qwiklabs – Lab Estimator API),這次的實驗室主要的目標是希望Estimator API建構出AI的模型、並且能透過checkpoint來做儲存的動作即使訓練途中中斷或是有問題將能夠依照checkpoint繼續做訓練;一樣先創建notebooks接著切換至training-data-analyst > courses > machine_learning > deepdive > 03_tensorflow > labs 打開b_estimator.ipynb,開始進行實驗
一樣先引入所需的套件
接著載入所需的資料集
read_csv('路徑',header,name)
定義訓練集、驗證集、預測集的各種參數
將訓練結果與驗證數據做比較
-利用evaluate函數來球的metrics,可得到訓練的RMSE是否過高,來檢驗是否需要重新訓練。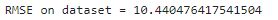
接著將模型進行預測使用沒有labels的測試資料集
model.predict(input_data)可以求得利用此模型預測出來的labels結果是多少。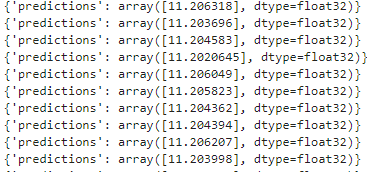
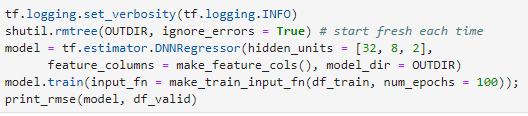
在這邊用了另外一種架構DNNRegressor

這次的實驗(Qwiklabs – Scaling up TensorFlow ingest using batching)最主要想要達到的目標是資料集非常的大需要批次去處理,那dataset API是一個非常好的選擇。一樣先創建notebooks接著切換至training-data-analyst > courses > machine_learning > deepdive > 03_tensorflow > labs 打開c_dataset.ipynb,開始進行實驗。
一樣先引入所需的套件。
接著我們希望使用dataset API
data.Dataset.list_files來讀取在資料夾中的所有檔案INPUT_COL = [
tf.feature_column.numeric_column('選取資料')....
]
def add_more_features(feats):
return feats
frature_cols = add_more_features(INPUT_COL)