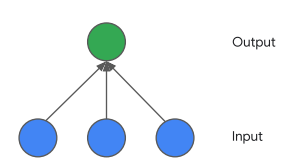
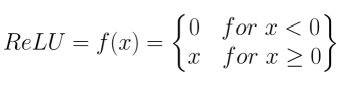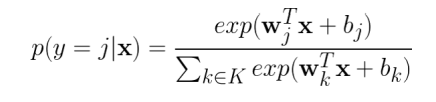我們前面很多的舉例以及實驗都以輸入與輸出作為節點作為運算,所以基本上算是線性模型
雖然針對簡單的問題用這個架構就已經可以解決了,但如果今天輸入有100個輸出也有100個那要算到甚麼時候呢???
所以我們希望加入神經元幫我們做運算,除了將建構出非線性模型同時將模型複雜化
雖然看似會消耗很多資源,但同時會提升處理效率,就把它想成多了好幾個小幫手幫忙你寫功課的概念
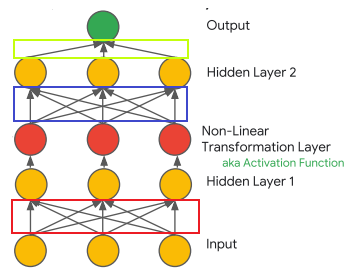
直接用圖來做舉例,先看到左邊這張圖X為輸入Y為輸出,通過隱藏層後插入了一層激活函數作為非線性的架構
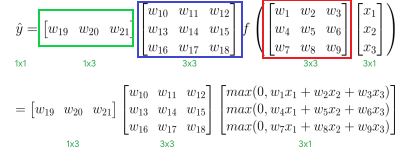
公式如下所示,我們可以看到最右邊的矩陣會經過我們定義的function再輸出到下一層,而這邊的function依照我們所設定的激活函數傳遞到下一層的輸出會有所不同
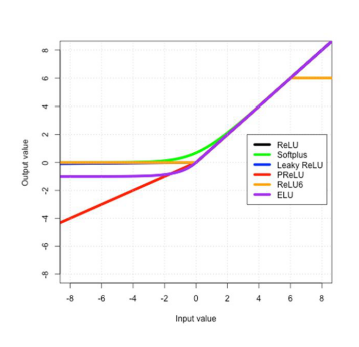
下圖為常見的激活函數,大家可以依照自己的需求選用相關的參數,藉此達到非線性的效果,現在最常使用的就是ReLU function,公式如右圖所示對於CNN架構提取特徵非常的好,因為它只會放大需要被選擇的特徵,濾除不必要的特徵,現在廣泛應用於各種模型當中
當然在訓練的過程中會遇到很多的問題,這邊舉出關於梯度下降三樣常見的錯誤
| 問題 | 梯度消失 | 梯度爆炸 | ReLu layers死亡 |
|---|---|---|---|
| 影響 | 慢慢的傳遞訊號會消失 | 學習速率要仔細調整 | 會產生很多包含0的權重 |
| 解決方法 | 使用ReLu取代sigmoid/tanh function | 加入Batch normalization | 降低學習速率 |
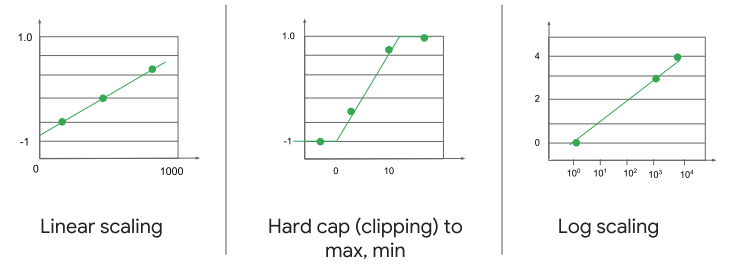
而在訓練的過程中使用較小的數值能達到滿多的好處,這邊列舉幾點來做說明
那要怎麼將數值進行縮放呢?這邊提供一些方式來進行縮放大家有興趣可以參考看看
Dropout最簡單的觀念有點像選擇性遺忘,會依照你選擇的比例丟棄數值
假設我選擇Dropout = 0.2,在學習過程中會將已經學會的20%丟棄,在繼續學習避免過擬合的狀況發生
softmax則是在種類太多時,先進行機率的分配,根據最大的可能性來輸出結果
公式如下方所示,每個神經元依照目標神經元輸出/總數來判斷輸出類別的最大機率
※圖片參考至 Art and Science of Machine Learning slide