
為什麼要這樣做呢?理由非常的簡單即使tensorflow寫了那麼多好用的工具
但你能夠保證他的工具應用到你的資料會是百分之百效果最好嗎??
我想沒有一個人能夠保證吧,那就依照你的數據乖乖地自定義一個屬於自己的架構,藉此將模型效益最大化
這次的實驗主要是利用自定義模型,來預測一組序列後的結果,一樣先創建bucket、notebooks接著切換至training-data-analyst> courses> machine_learning> deepdive> 05_artandscience > labs 打開 d_customestimator.ipynb,開始進行實驗。
import os
PROJECT = 'xxx' #改成自己的資訊
BUCKET = 'xxx'
REGION = 'xxx'
接著利用隨機的方式產生數列,可以看到這邊y的範圍從正負1.5,我們的目標想要預測的是在下一個時間點(x=10)時結果為何,並且將這些隨機產生的資料寫入csv檔中做訓練與驗證集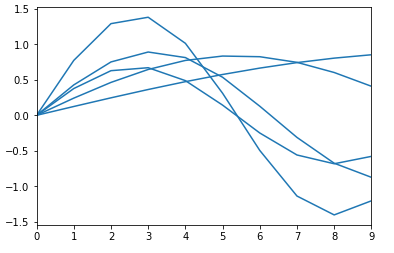

定義一個function去讀取csv,並且將數據的前面去除最後一位做為輸入資料、最後一位設定為labels,透過批次化的處理讀取檔案
inputs = all_data[:len(all_data) - N_OUTPUTS]
labels = all_data[len(all_data) - N_OUTPUTS:]
建構RNN模型
lstm_cell = rnn.BasicLSTMCell("層數", forget_bias = "bias")
outputs, _ = rnn.static_rnn(lstm_cell, "輸入資料", dtype = tf.float32)
loss = tf.losses.mean_squared_error(labels, "預測結果")
train_op = tf.contrib.layers.optimize_loss
(loss = loss,learning_rate = 0.01,optimizer = "SGD")
eval_metric_ops = {"rmse": tf.metrics.root_mean_squared_error(labels, "預測結果")}
predictions_dict = {"predicted": 預測結果}
export_outputs = {"predict_export_outputs": tf.estimator.export.PredictOutput(outputs = predictions)}
return tf.estimator.EstimatorSpec(
predictions = predictions_dict,loss = loss, train_op = train_op, eval_metric_ops = eval_metric_ops,export_outputs = export_outputs)
使用Estimator API來載入我們剛剛建構的模型
estimator = tf.estimator.Estimator(model_fn = "模型副程式", model_dir = "輸出資料夾")
最後可以決定要再本地端進行訓練或是使用Cloud ML Engine,唯一不同的地方只有需要更改路徑以及相關bucket的設定,並且可以透過TensorBoard來觀察訓練成效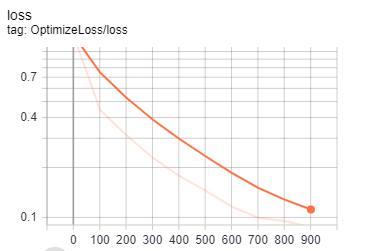
另外這些架構也都可以利用keras來做實作,keras有點像堆疊的概念,將其架構排列組合形成我們所要的功能
model = keras.models.Sequential()
model.add(keras.layers.Dense(32, input_shape=(N_INPUTS,), name=TIMESERIES_INPUT_LAYER)) #ˇ32個神經元
model.add(keras.layers.Activation('relu')) #激活函數
model.add(keras.layers.Dense(1)) #輸出神經元
model.compile(loss = 'mean_squared_error', optimizer = 'adam',metrics = ['mae', 'mape'])
# LOSS function 、優化器、評估模式
經過這三十天不長也不短,除了增進自己基礎的能力外更看到很多的高手是怎麼寫文章怎麼表達一個主題
對於第一次參加的我來說有點抓不到方向跟撰寫方式,在看了各個高手的分享才慢慢改進我的風格
在這三十天裡經歷過大大小小的事每天除了要發文,還要克服修課、參加活動、感冒等多項外在因素
能夠完成的大家實在是不容易,畢竟還有社會人士工作之餘還要發出那麼有質量的文章,我由衷佩服大家的毅力
我這次的方想比較偏向實作的部分,因為我是第一次使用GCP這個平台,會希望對於實作有多點的介紹
但礙於程式碼有版權的問題,所以我主要還是以介紹程式流程為主,如果有看不懂的地方,也歡迎大家有興趣的話可以一同討論,畢竟好用的平台還是要靠大家推廣出去的呀
最後恭喜大家都完成了30天的挑戰一起成為鐵人

