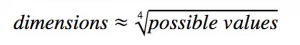Embeddings非常廣泛運用於NLP(Natural Language Processing)中,最主要是因為它有獨立儲存各項特徵的關係
舉個例子來說好了我有兩個字句,我今天很開心、我昨天很快樂
如果我希望預測明天我的心情是如何,正常來說我會去拆解上面兩個字句
但大家有發現"我"、"天"、"很"是裡面重複的字詞那如果今天我有一千個例句甚至一萬個
那就以上面六個字來做拆解好了我至少會有6000個參數,大家覺得對於機器它是能夠預測出來的嗎??
即使預測的出來我相信也要很久的時間,所以才會提出Embeddings這個概念
我們可以把上述提到的三個字詞映射到同一維度當中,這樣是不是少掉近3000筆的參數了
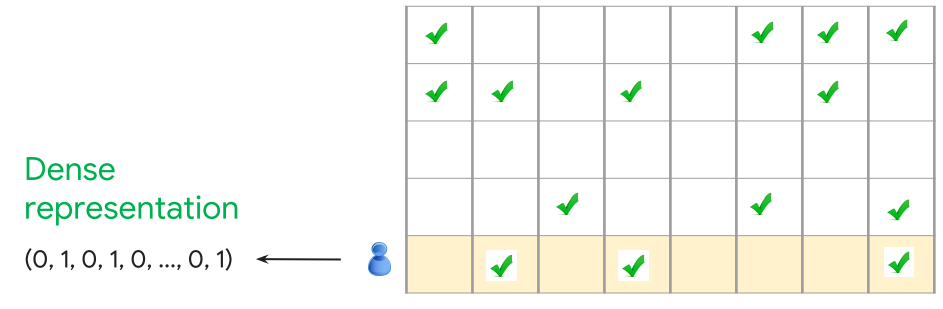
Dense representations
首先我們先來看之前如果我們要做這種分類的問題一開始會怎麼做吧
之前有提到利用one-hot-encode的方法將每個維度燈轉換成0、1的架構
那這有甚麼問題呢??如果今天資料量很少當然沒事,那今天資料量1000~10000筆
依照下方這張圖在計算時還要加入一堆根本沒有用的數據,那不就是浪費空間與時間了嗎
sparse representations
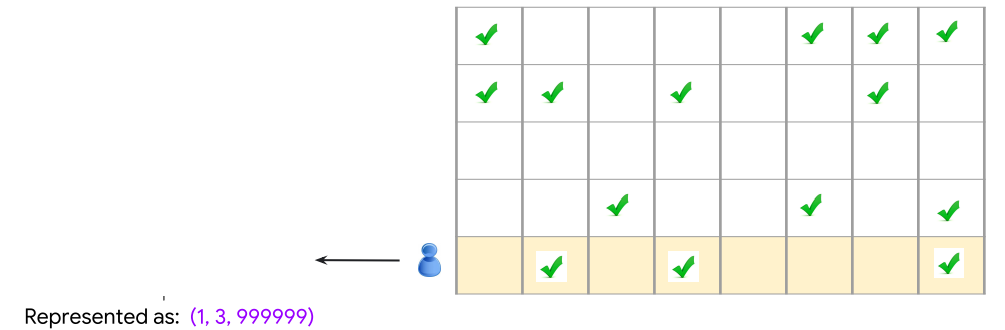
利用Embeddings的方式我們可以依照有內容的參數去進行紀錄
所以我們可以看到下圖我們只需要三個參數就可以代表這個人的特徵
講了那麼多那實際上要怎麼真正的應用於現實生活中呢??
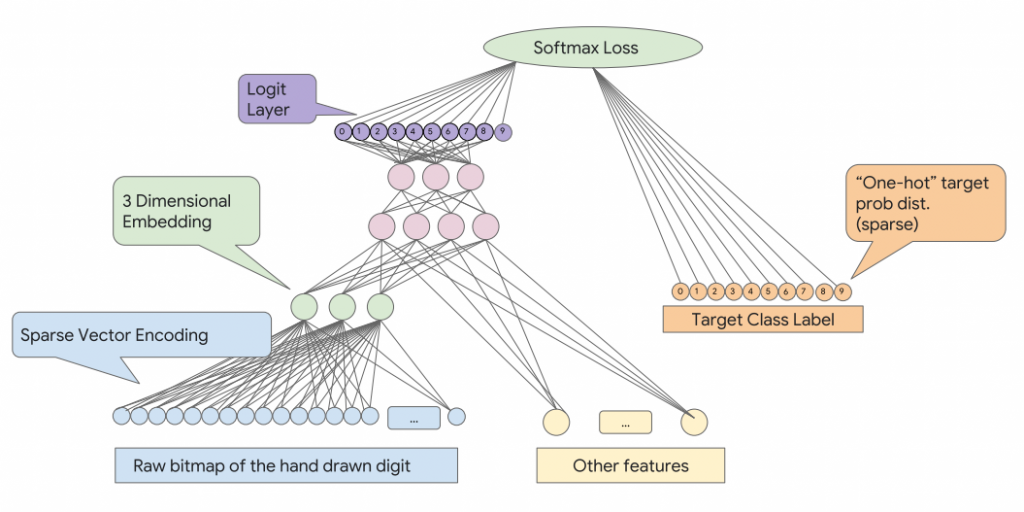
這邊有提供一個關於數字辨識的例子,給大家作為參考
首先我們要先將下方這個數字拆解成一格一格小方塊作為我們的輸入
接著將著建立三個維度的Embeddings(綠色圓點)用來替代重複的輸入(藍色圓點)
再加入其他特徵(黃色圓點)後放入neural network(粉色圓點)進行運算
最後依照輸出機率大小(紫色圓點)透過softmax與原來目標進行比對(橘色圓點)完成整個架構
最後統整Embeddings的好處
雖然高維度帶來更高的準確性,但太高維度的狀況下會產生overfitting與訓練過程很慢
我們可以參考此公式來進行embedding維度的調整
※圖片參考至 Art and Science of Machine Learning slide