上一篇介紹了『協同過濾』(Collaborative Filtering)的概念,並實作『以記憶體為基礎的過濾』(Memory Based Collaborative Filtering),這種方法需要計算表格中每一格(Cell)的相似度,這種窮舉法會耗費大量計算資源,『以模型為基礎的過濾』方法以機器學習演算法直接找出機率最大的商品,可以改善前者的缺點。
今天我們來討論『以模型為基礎的過濾』(Model Based Filtering),可以使用各種機器學習、深度學習(Deep Learning, RL)或強化學習(Reinforcement learning, DL)的演算法,來構築推薦系統。
本篇介紹 KNN 及 SVD 兩種演算法。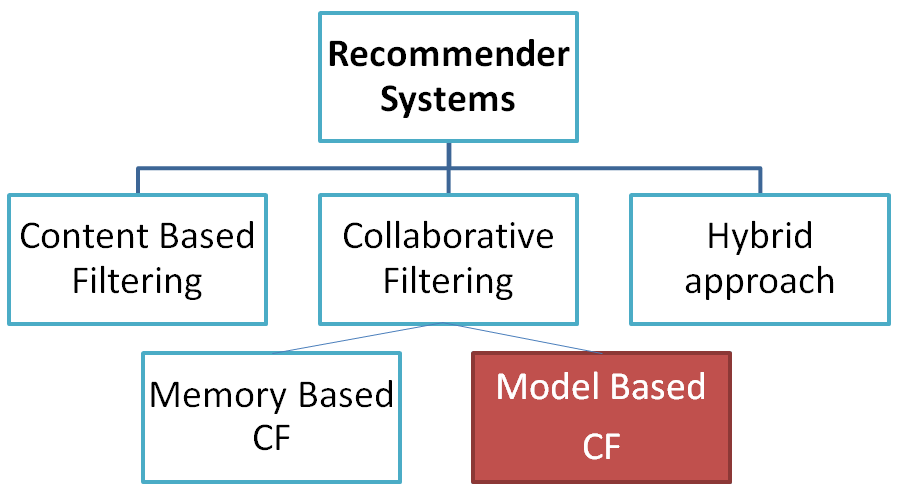
KNN是監督式學習演算法中最簡單的方法,它計算所有樣本點與預測點的距離,可以取1、3、5...點,然後以多數決(Majority Voting)決定預測點是哪一類,如下圖: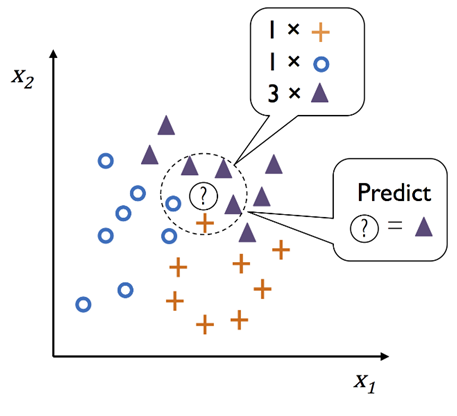
首先整理出每一使用者對每一個商品的評價表(User-Item Rating Table),再以下列程式進行模型訓練即可。
from sklearn.neighbors import NearestNeighbors
model_knn = NearestNeighbors(metric = 'cosine', algorithm = 'brute')
# us_canada_user_rating_matrix 即商品的評價表(User-Item Rating Table)
model_knn.fit(us_canada_user_rating_matrix)
接著,要預測某一商品的相似商品推薦,直接呼叫kneighbors函數即可:
query_index=0
distances, indices = model_knn.kneighbors(np.array(us_canada_user_rating_pivot.iloc[query_index, :]).reshape(1, -1), n_neighbors = 6)
其中 n_neighbors = 6,就是選出6項最相似的商品。
完整的程式碼放在這裡的 Day10 KNN、SVD 目錄。
NetFlix 很久之前辦過一個比賽 Netflix Prize,目標是希望有新的演算法能作幫該公司作電影推薦,比賽結果是『矩陣分解』(Matrix Factorization)演算法脫穎而出,其中又以奇異值分解(Singular Value Decomposition, SVD)為代表。
通常 User-Item Matrix 會是一個很稀疏的矩陣(Sparse Matrix),因為,每個使用者通常只買過網站中很少種類的產品,故對照表矩陣中應該大部分是空值(Null Value),因此,我們可以利用特徵向量(Eigenvector)或SVD作矩陣轉換,將稀疏的矩陣降維,變成比較小的矩陣,那計算就比較省時了。
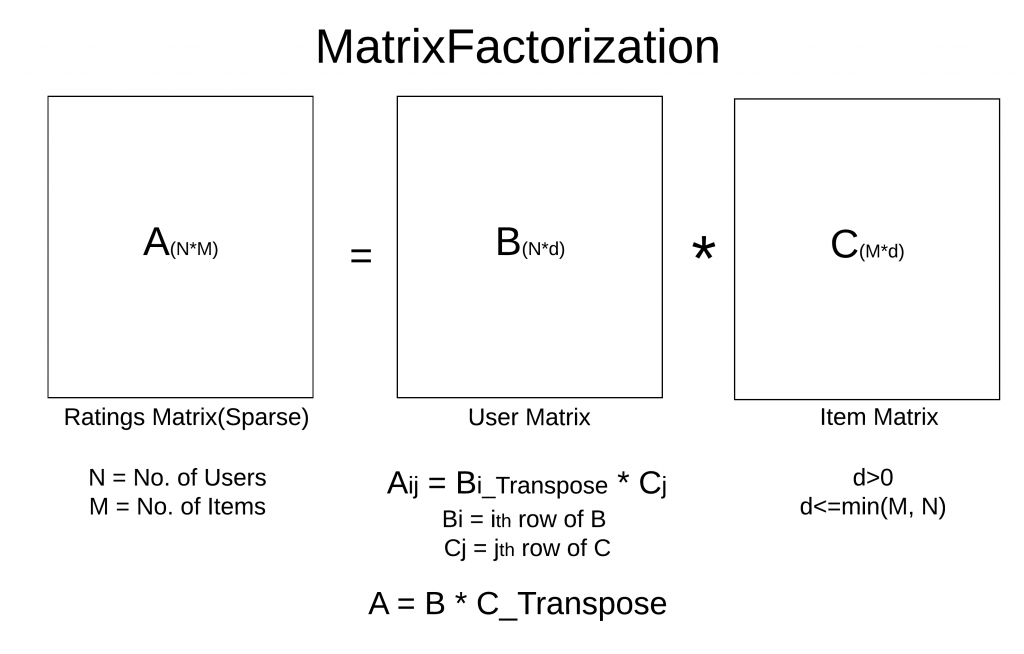
資料來源:How to Build a Recommender System,以下圖形也都來自此篇文章。
以下牽涉數學較多,沒興趣的讀者就跳過吧。
依最小平方法(OLS)定義的損失函數(Loss Function)或稱目標函數(Objective Function)如下: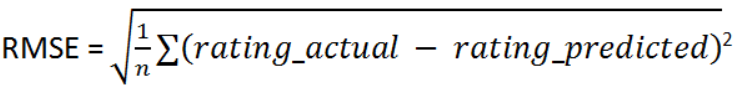
以上A/B/C矩陣對照商品推薦的資料如下:
損失函數就可改寫如下:
為避免過度擬合(overfitting),損失函數加上 L2 正則化(Regularization),如下: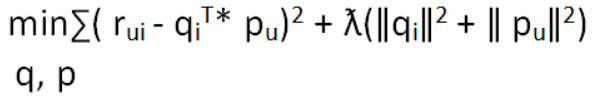
定義好損失函數之後,可以使用兩種優化方法(Optimizer),求出商品(i)及使用者(u)的向量:
ALS方法計算比較快,通常,會使用ALS。
之後作者發現一個問題,此算法不能保證可以最小化RMSE,因此,作者再加三個參數:bu, bi, µ,再修改損失函數如下: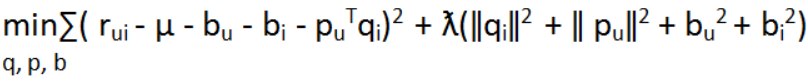
bu:估計每個使用者的偏差項。
bi:估計每個商品的偏差項。
µ :所有使用者及所有商品的平均值。
搞了這麼多,總之,就是利用上述的損失函數,優化求解,有興趣的讀者可參考『Day N+1:進一步理解『梯度下降』(Gradient Descent)』。
上面求解的過程很複雜,很慶幸有善心人士幫我們把套件寫好了,我們不需從頭撰寫程式,有很多套件都支援 SVD,其中又以 scikit-learn 及 Surprise 最常見,Surprise是以scikit-learn為基礎開發的套件,來看看 Surprise 的作法:
pip install surprise
from surprise import SVD
from surprise import Dataset
from surprise import accuracy
from surprise.model_selection import train_test_split
# 載入內建 movielens-100k 資料集
data = Dataset.load_builtin('ml-100k')
# 切分為訓練及測試資料
# test set is made of 25% of the ratings.
trainset, testset = train_test_split(data, test_size=.25)
# 使用 SVD 演算法
algo = SVD()
# 訓練
algo.fit(trainset)
# 測試
predictions = algo.test(testset)
# 計算 RMSE
accuracy.rmse(predictions)
也可以使用其他surprise支援的演算法作比較,評估哪一個模型比較準。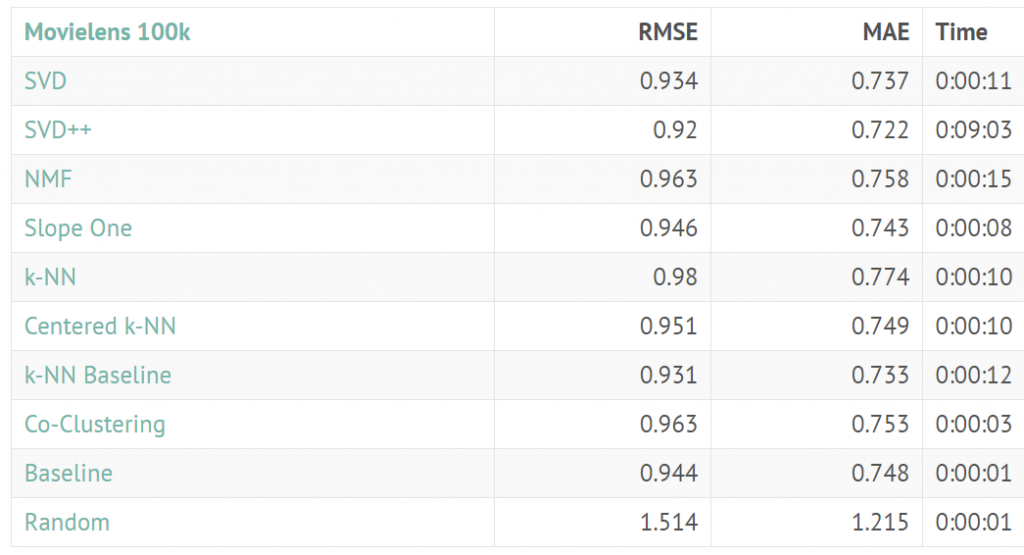
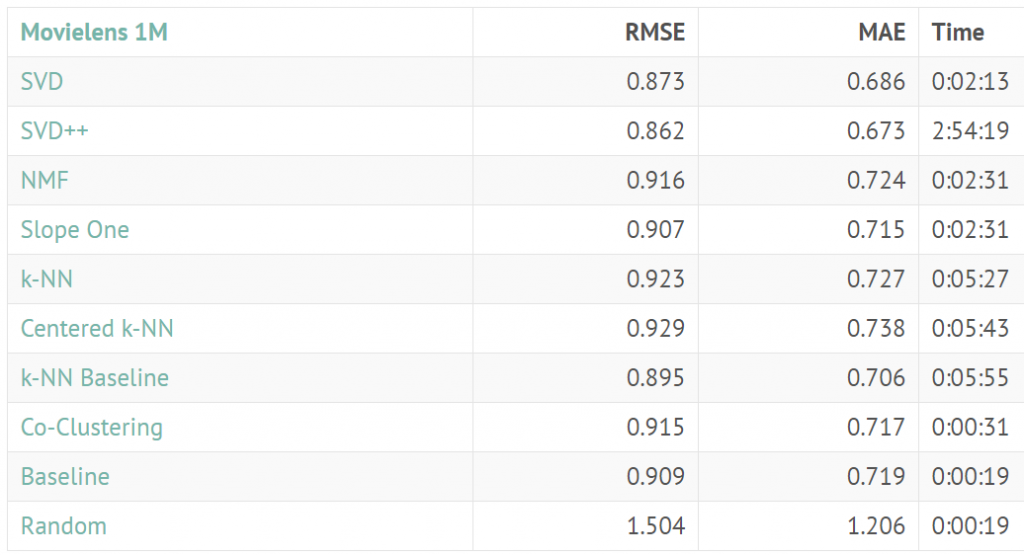
資料來源:http://surpriselib.com/
以模型為基礎的協同過濾 (Model Based Filtering)方法,可解決矩陣過大且稀疏的問題,實務上,應該比上一篇逐格計算的可行性較高,同時利用surprise套件,幾行程式就搞定了,但是,還是要了解原理,才能因應專案的特性量身訂作。


 iThome鐵人賽
iThome鐵人賽