
今天嘗試來用美麗的湯從Youtube爬取影片標題、連結、觀看次數與簡介。爬取的資料是一個好聽德國樂團Berge的Youtube搜尋頁面(是想趁機推坑吧笑死)。
Today we are going to scrape title, link, view counts, and descriptions from Youtube using Beautiful Soup. The url we are scraping today is the search result on Youtube of a German band Berge.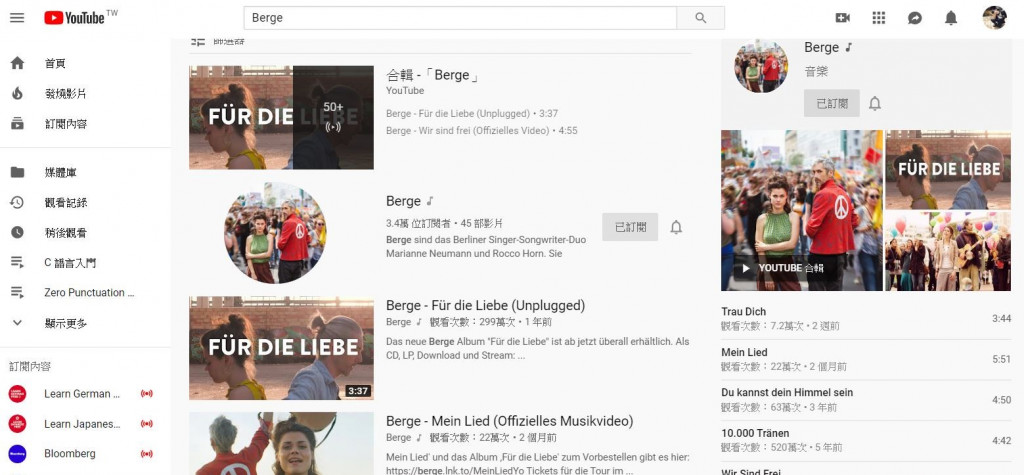
# 同前兩天的起始步驟,載入套件、創建美麗湯物件
# Same set up steps as in day25, import packages, set up a beautiful soup object
import requests
from bs4 import BeautifulSoup
url = "https://www.youtube.com/results?search_query=Berge"
request = requests.get(url)
content = request.content
soup = BeautifulSoup(content, "html.parser")
print(soup) # 看一下怎麼區分的 have a peak of how each video's seperated
# 印出第一筆資料來觀察 print out the first data to see
look_up = []
for vid in soup.select(".yt-lockup-video"):
look_up.append(vid)
print(look_up[0])

title = []
uploaded = []
watch_counts = []
description = []
link = []
for vid in soup.select(".yt-lockup-video"):
data = vid.select("a[rel='spf-prefetch']") # 找到有我們要的資料區塊 get the section that contains the info we want
title.append(data[0].get("title")) # 存標題 save the title
link.append("https://www.youtube.com{}".format(data[0].get("href"))) # 存連結 save the link
time = vid.select(".yt-lockup-meta-info") # 找到有我們要的資料區塊 get the section that contains the info we want
uploaded.append(time[0].get_text("#").split("#")[0]) # 存上傳時間 save the uploaded time
watch_counts.append(time[0].get_text("#").split("#")[1]) # 存觀看次數 save the watch counts
disc = vid.select(".yt-lockup-description") # 找到有我們要的資料區塊 get the section that contains the info we want
try:
description.append(disc[0].get_text()) # 有找到簡介的存起來 save if there's description
except:
description.append("Nan")
continue # 如果沒有就存一個空值然後跳過 append a Nan value and continue if there's none
print(title[0])
print(uploaded[0])
print(watch_counts[0])
print(description[0])
print(link[0])

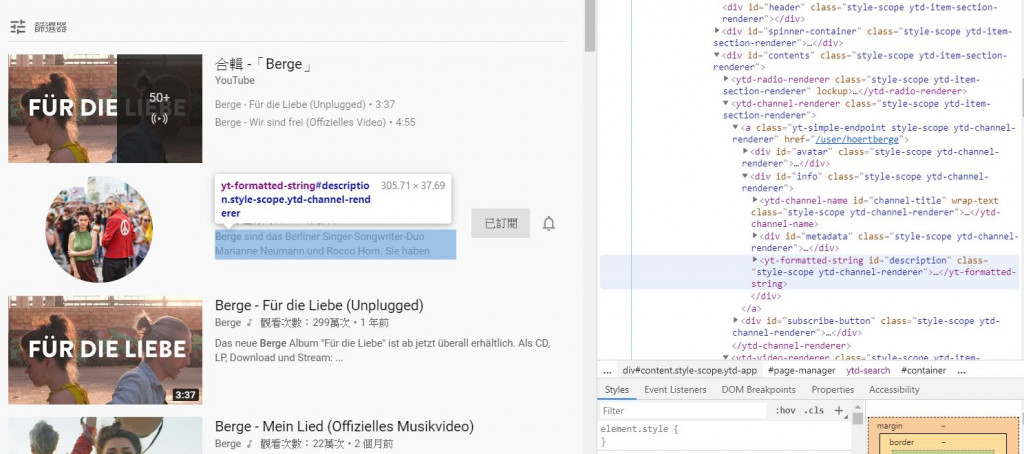
像上圖的頻道連結或播放清單等,有時裡面會沒有文字或沒有這個區塊,所以要跳過避免報錯。
When we look at the picture above, we can see that sometimes the search results contains the channel of the artist or even playlists. And there might be no string in the description or even without the description section. Thus, we need to set up a continue iteration for our loop to avoid errors occur.
import pandas as pd
berge = {'Title':title, 'Uploaded':uploaded, 'Watch_Counts':watch_counts, 'Description':description, 'Link':link}
berge = pd.DataFrame(berge)
berge.head()
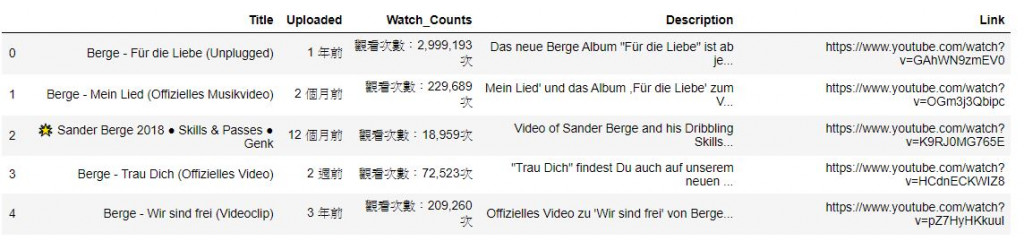
berge.to_csv('berge.csv')
本篇程式碼請參考Github。The code is available on Github.
文中若有錯誤還望不吝指正,感激不盡。
Please let me know if there’s any mistake in this article. Thanks for reading.
Reference 參考資料:
[2] 爬蟲實戰-Youtube
[3] Youtube
[4] IndexError
