
延續昨日的文章,今天要把Berge的Youtube搜尋頁面縮圖連結存下來。
Today we will continue last article to scrape the thumbnail URLs from the search result of Berge on Youtube.
# 同昨天的起始步驟,載入套件、創建美麗湯物件
# Same set up steps as yesterday, import packages, set up a beautiful soup object
import requests
from bs4 import BeautifulSoup
url = "https://www.youtube.com/results?search_query=Berge"
request = requests.get(url)
content = request.content
soup = BeautifulSoup(content, "html.parser")
# 印出標題以及URL,點開對照確認抓取的資料無誤
# print out titles and URLs to check that we have the correct URLs scraped
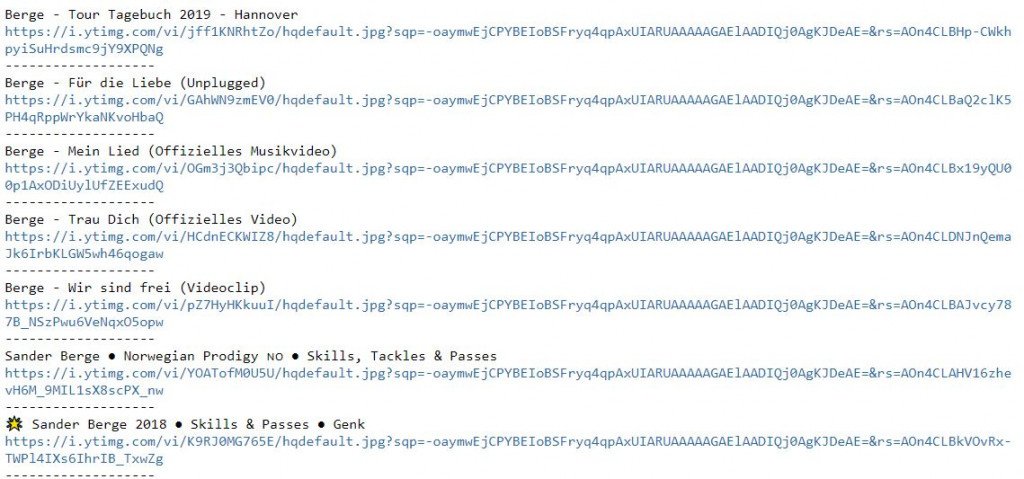
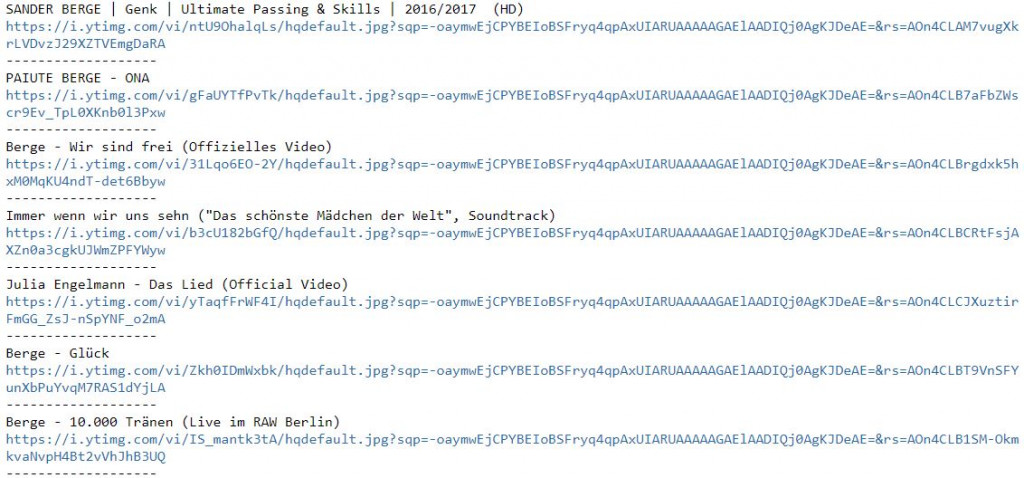
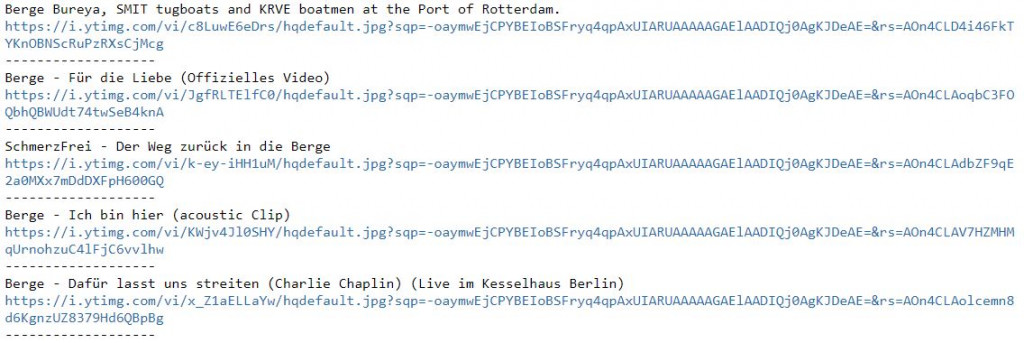
for vid in soup.select(".yt-lockup-video"):
data = vid.select("a[rel='spf-prefetch']")
print(data[0].get("title"))
img = vid.select("img")
if img[0].get("src") != "/yts/img/pixel-vfl3z5WfW.gif":
print(img[0].get("src"))
else:
print(img[0].get("data-thumb"))
print("-------------------")
# 把我們抓取到的URL存成清單以利稍後加入昨天的資料框架中
# save the URLs into a list so we can then add them into the dataframe we created yesterday
img_url = []
for vid in soup.select(".yt-lockup-video"):
img = vid.select("img")
# 發現如果src="/yts/img/pixel-vfl3z5WfW.gif",URL是存在data-thumb;否則就是直接存在src
# if the src="/yts/img/pixel-vfl3z5WfW.gif", URLs are in data-thumb. otherwise it's in src
if img[0].get("src") != "/yts/img/pixel-vfl3z5WfW.gif":
img_url.append(img[0].get("src"))
else:
img_url.append(img[0].get("data-thumb"))
print(img_url[:3])

Save the url of the thumbnails with the dataframe we created yesterday and save as a new file.
import pandas as pd
# 讀入昨天存的檔案來分析 read in the file we created yesterday
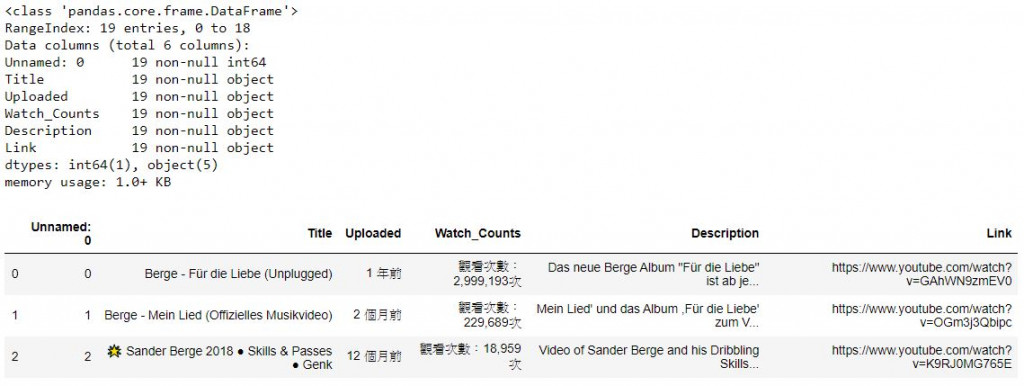
berge = pd.read_csv('berge.csv')
berge.info() # 查看資料細節 the info of data
berge.head(3) # 叫出前三筆資料看看 print out the top three rows of data
berge['Img_URL'] = img_url # 新增欄位 add the ima_url as a new column
berge.head(3)

berge.to_csv('berge_final.csv') # 儲存新的csv檔 save the new file
Have a look at the thumbnails
from PIL import Image
from io import BytesIO
import numpy as np
import matplotlib.pyplot as plt
# 取得連結 get the link of URLs
response = requests.get(img_url[0])
img = Image.open(BytesIO(response.content))
# 轉成Numpy陣列等等要繪圖 convert img to numpy array so we can then plot them out
img = np.array(img)
plt.imshow(img)
plt.show()

# 把URL都轉成陣列並存進清單 convert all the URLs into Numpy array then append into a list
thumbnail = []
for u in img_url:
response = requests.get(u)
try:
img = Image.open(BytesIO(response.content))
except OSError:
continue
img = np.array(img)
thumbnail.append(img)
for t in thumbnail:
plt.imshow(t)
plt.show()



















本篇程式碼請參考Github。The code is available on Github.
文中若有錯誤還望不吝指正,感激不盡。
Please let me know if there’s any mistake in this article. Thanks for reading.
Reference 參考資料:
[2] 爬蟲實戰-Youtube
[3] Youtube
[4] IndexError
[5] 第二屆機器學習百日馬拉松內容
[6] Adding new column to existing DataFrame in Pandas
