網路爬蟲是 Python 一個非常重要且常見的應用,甚至有許多人是為了爬蟲才學 Python 的,接下來的幾天我會向是每天介紹一個應用,讓大家知道 Python 可以用在生活中的哪邊,也會給大家一些參考資料,如果對某一用有興趣,就可以繼續延伸閱讀,那今天就來初步認識網路爬蟲中很重要的 HTML 解析套件 beautifulsoup4 吧!
我們先建立一個虛擬環境,以便安裝第三方套件
pipenv --python 3.7
pipenv shell
安裝第三方套件
pipenv install requests beautifulsoup4
程式碼開頭引用 BeautifulSoup 和 requests
from bs4 import BeautifulSoup
import requests
先從 www.ptt.cc 下載網頁原始碼
url = "https://www.ptt.cc/bbs/Diary/index.html"
html = requests.get(url)
宣告 BeatifulSoup 物件,將 HTML 檔案用來初始化
s = BeautifulSoup(html.text, 'html.parser')
開始進行 HTML 分析,第一行先使用 find_all 函式搜尋 CSS class 為 title 的區塊,第二行將剛剛找出來的區塊轉型為HTML字串,再給 bs4 進行一次宣告,存進 stitle,第三行,再次解析,找出 stitle 裡面名稱叫 a 的標籤,也就是超聯結。
title = s.find_all(class_="title")
stitle = BeautifulSoup(str(title), 'html.parser')
ahref = stitle.find_all("a")
到這邊解析就完成了,bs4 幫我們創造了一個 list,裡面有我們要的超連結標籤,但是他依然是一個標籤,我們想要分離出標籤內文字和標籤的 href 屬性,所以我們用 .text 來取得標籤文字,用.get('href') 來取得標籤內我們想要的屬性,經過整理後再存入 data{} 已字典型態儲存以便後續利用。
data = {}
for item in ahref:
data[item.text] = (RootUrl + item.get('href'))
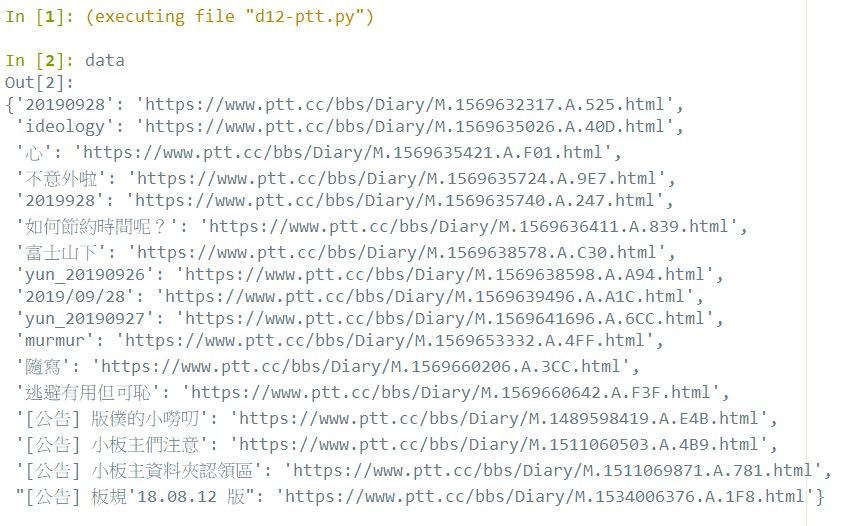
程式執行結果
from bs4 import BeautifulSoup
import requests
RootUrl = "https://www.ptt.cc"
url = "https://www.ptt.cc/bbs/Diary/index.html"
html = requests.get(url)
s = BeautifulSoup(html.text, 'html.parser')
title = s.find_all(class_="title")
stitle = BeautifulSoup(str(title), 'html.parser')
ahref = stitle.find_all("a")
data = {}
for item in ahref:
data[item.text] = (RootUrl + item.get('href'))
print(data)
選一個 www.ptt.cc 中你有興趣的板,並將其透過 bs4 + requests 爬蟲擷取下來。
延伸閱讀

