
昨天我們去除了 batch normalization 上冗贅的節點,但...其實呢... batch normalization 還可以做一種優化將它 folding 下去,恩?這是什麼意思呢?這時我們要從數學的角度切入,一般來說,batch normalization 都會接在 convolution 卷積之後,而卷積層的輸出我們可以表示成這樣: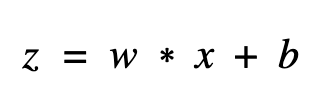
而在推論時,batch normalization 的會對上面 convolution 的輸出做的以下運算,其中 mean 和 var 分別代表 moving_mean 和 moving_var: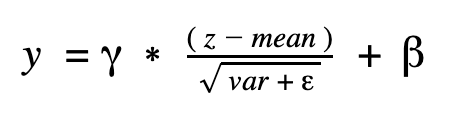
我們把 z 帶入,公式變成這樣: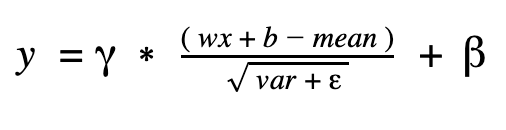
再來稍微移動一下,讓參數變成這樣: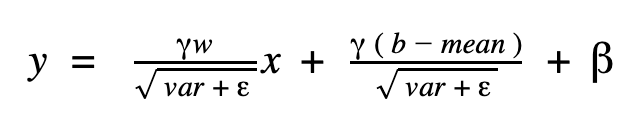
將將!改寫後,新的 convolution 運算變成下面這樣: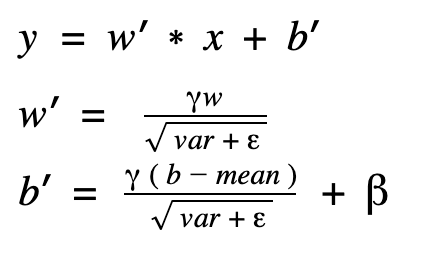
由此可知,我們完全可以把 batch normalization 的結果融合進前一層的 convolution 運算中,把 batch normalization 完全變不見!而這個動作很像把 batch normalization “折”進 convolution,所以會叫 fold batchnorm 。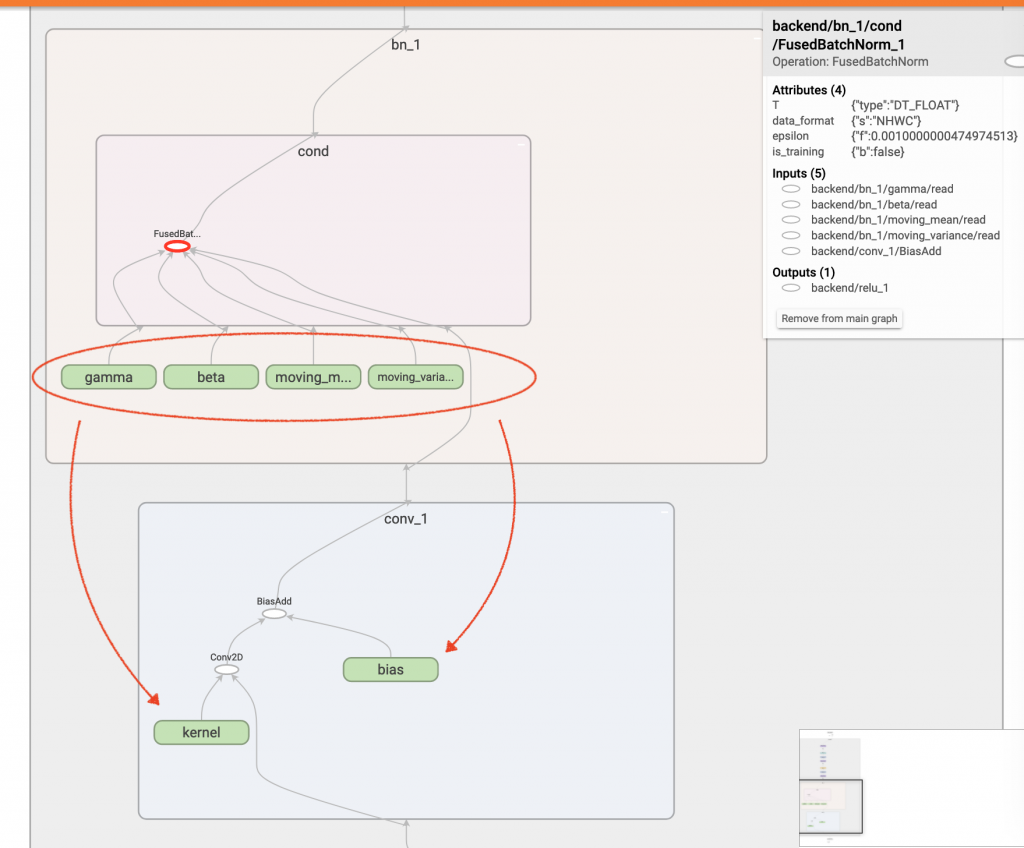
我們來寫寫程式碼吧,main 中的 opt 多了 fold_bn 這個優化。
# opt start #
preprocess_gd = add_preprocessing('backend/conv_1/Conv2D', 'input_node')
update_graph(preprocess_gd)
no_training_gd = remove_training_node('training', 'false_node')
update_graph(no_training_gd)
no_dropout_gd = remove_dropout()
update_graph(no_dropout_gd)
no_merge_gd = remove_merge()
update_graph(no_merge_gd)
no_switch_gd = remove_switch()
update_graph(no_switch_gd)
fold_bn_gd = fold_bn()
update_graph(fold_bn_gd)
# opt end #
和 dropout 一樣,我們定義 fold_bn() 來個別定義要簡化的區塊,然後真的某區塊的優化再寫成 fold() 來定義:
def fold_bn():
old_gd = tf.get_default_graph().as_graph_def()
new_gd = fold(old_gd,
bn_scope='backend/bn_1',
conv_scope='backend/conv_1')
new_gd = fold(new_gd,
bn_scope='backend/bn_2',
conv_scope='backend/conv_2')
new_gd = fold(new_gd,
bn_scope='backend/bn_3',
conv_scope='backend/conv_3')
return new_gd
而 fold() 的前半部,我們先取得幾個有興趣的節點,分別是推論會用到的 moving_mean, moving_var, gamma, beta 和 epison,而因為要和前一層的 conv 結合,所以也要拿該 conv 的 weight 和 bias,再來,因為會重新改動節點,所以也拿了 FusedBatchNorm_1, Conv2D, BiasAdd 這三個節點,最後創建了 nodes_to_skip 來記錄哪些節點不該產生。
def fold(graph_def, bn_scope, conv_scope):
nodes = graph_def.node
# get values and nodes #
mean_node, mean_value = values_from_const(nodes, f'{bn_scope}/moving_mean')
var_node, var_value = values_from_const(nodes, f'{bn_scope}/moving_variance')
epison_value = values_from_attr(nodes, f'{bn_scope}/cond/FusedBatchNorm_1', 'epsilon')
gamma_node, gamma_value = values_from_const(nodes, f'{bn_scope}/gamma')
beta_node, beta_value = values_from_const(nodes, f'{bn_scope}/beta')
kernel_node, kernel_value = values_from_const(nodes, f'{conv_scope}/kernel')
bias_node, bias_value = values_from_const(nodes, f'{conv_scope}/bias')
fused_bn_node = node_from_name(nodes, f'{bn_scope}/cond/FusedBatchNorm_1')
conv_node = node_from_name(nodes, f'{conv_scope}/Conv2D')
bias_add_node = node_from_name(nodes, f'{conv_scope}/BiasAdd')
# 以下四個節點會拿去運算,新圖表不會產生
nodes_to_skip = [kernel_node.name, bias_node.name, fused_bn_node.name, bias_add_node.name]
再來就是數學的部分,上面我們得出了新的 weight 和 bias 該怎麼產生,這邊就怎麼撰寫,scale_value,是更新的權重的係數,也就是 w’ ,offset_value 是更新後的 bias,即 b’,更新的寫法如下,因為 kernel_value 的 shape 是四維,所以用了 while 來更新。
# fold bn values #
scale_value = ((1.0 / np.vectorize(
math.sqrt)(var_value + epison_value)) * gamma_value)
scaled_weights = np.copy(kernel_value)
it = np.nditer(scaled_weights, flags=["multi_index"], op_flags=["readwrite"])
while not it.finished:
current_scale = scale_value[it.multi_index[3]]
it[0] *= current_scale
it.iternext()
offset_value = (bias_value - mean_value) * scale_value + beta_value
第三個部分是產生新節點,我們有三個節點要產生,分別是新的 weight 常數節點,新的 bias 常數節點和新的 BiasAdd 運算節點,有別於之前都是在程式碼宣告,這次利用 node_def_pb2.NodeDef() 的方式來產生,而有個特別的一點須注意就是 BiasAdd 的名稱取名叫 FusedBatchNorm_1 ,這是因為下一層的 relu 的 input 是 FusedBatchNorm_1,我這次不想改動到 relu,所以重複使用了這個 input 名稱。
# 新的conv weight 常數節點
scaled_weights_op = node_def_pb2.NodeDef()
scaled_weights_op.op = "Const"
scaled_weights_op.name = kernel_node.name
scaled_weights_op.attr["dtype"].CopyFrom(kernel_node.attr["dtype"])
scaled_weights_op.attr["value"].CopyFrom(
attr_value_pb2.AttrValue(
tensor=tensor_util.make_tensor_proto(
scaled_weights, kernel_value.dtype.type, kernel_value.shape)))
# 新的conv bias 常數節點
offset_op = node_def_pb2.NodeDef()
offset_op.op = "Const"
offset_op.name = bias_node.name
offset_op.attr["dtype"].CopyFrom(bias_node.attr["dtype"])
offset_op.attr["value"].CopyFrom(
attr_value_pb2.AttrValue(
tensor=tensor_util.make_tensor_proto(
offset_value, bias_value.dtype.type, bias_value.shape)))
# 新的conv weight bias 合併運算節點
bias_add_op = node_def_pb2.NodeDef()
bias_add_op.op = "BiasAdd"
# 雖然是BiasAdd,但名稱仍叫FusedBatchNorm_1
bias_add_op.name = fused_bn_node.name
bias_add_op.attr["T"].CopyFrom(bias_add_node.attr["T"])
bias_add_op.attr["data_format"].CopyFrom(bias_add_node.attr["data_format"])
bias_add_op.input.extend([conv_node.name, offset_op.name])
最後是組合所有節點,這邊只需要注意記得跳過 nodes_to_skip 中的節點就好。
# gen graph def #
new_gd = graph_pb2.GraphDef()
for node in nodes: # for所有節點
if node.name in nodes_to_skip:
# 該skip的就skip
continue
new_node = node_def_pb2.NodeDef()
new_node.CopyFrom(node)
new_gd.node.extend([new_node])
# 除了原本該有的節點外多新增以下三個節點
new_gd.node.extend([scaled_weights_op, offset_op, bias_add_op])
return new_gd
終於寫好了,我們來看看跑出來的 graph 長怎樣吧。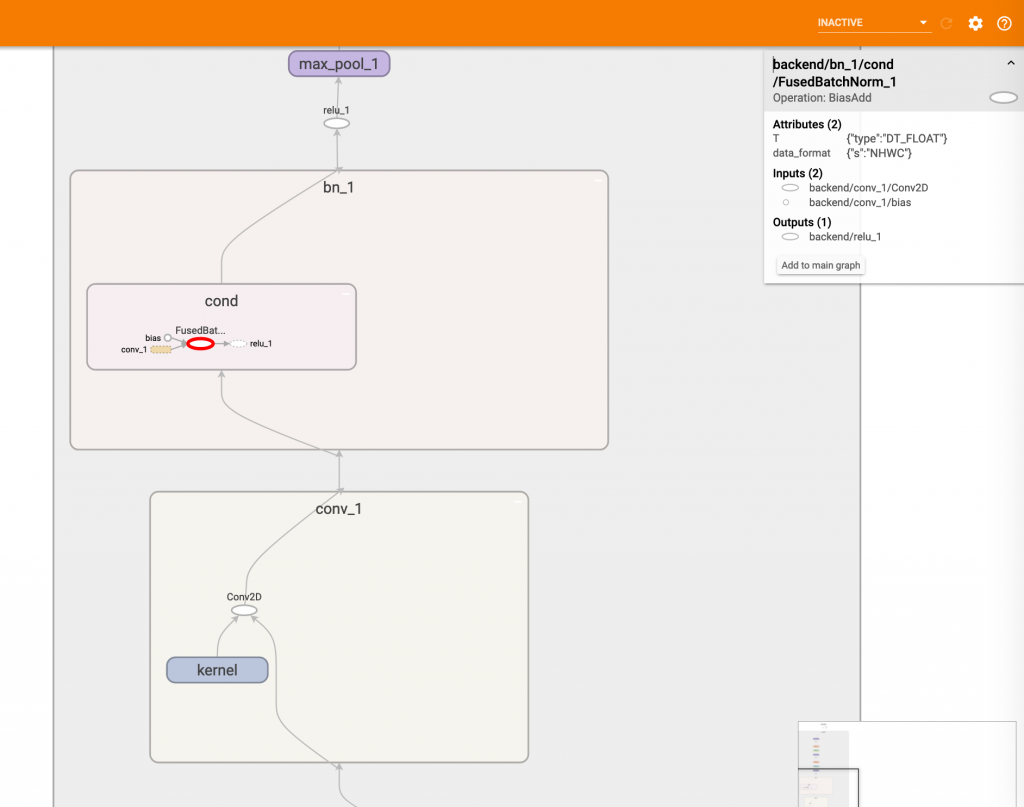
可以看到 gamma, beta, moving_mean 和 moving_var 都不見了,這四個數值都被更新到了 kernel 和 bias 中,而 cond 中裡面的那個節點名稱雖然是叫 FusedBatchNorm_1,但運算符寫著 BiasAdd 正好呼應上面的改動,雖然圖表多了一個 cond 的範圍看起來很亂,但它其實都是一條線性的運算!
為了證明邏輯不變,我們執行程式看看數值輸出: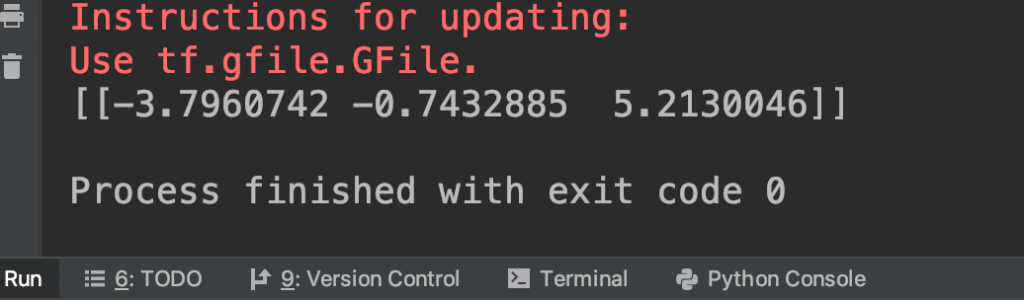
數值維持一樣,fold 成功!
